




 本文探讨了计算机中的数据表示与数据结构,包括自定义数据表示(如标识符和数据描述符)、高级数据表示如向量数组和堆栈,以及寻址方式的不同面向。重点介绍了指令系统设计原则,比较了CISC和RISC的发展方向,讨论了浮点数处理和寻址方式优化技术。
本文探讨了计算机中的数据表示与数据结构,包括自定义数据表示(如标识符和数据描述符)、高级数据表示如向量数组和堆栈,以及寻址方式的不同面向。重点介绍了指令系统设计原则,比较了CISC和RISC的发展方向,讨论了浮点数处理和寻址方式优化技术。
2.1 数据表示
2.1.1 数据表示与数据结构
数据表示:能由计算机硬件直接识别和引用的数据类型,表现在它有对这种类型的数据进行操作的指令和运算部件。
数据结构:应用中要用到的各种数据元素或信息单元之间的结构关系
数据结构是通过软件映像,变换成计算机中所具有的数据表示来实现的。
2.1.2 高级数据表示
1 自定义数据表示(填空,简答)
(1)标志符数据表示
类型标志 + 数据值
将数据类型与数据本身直接联系在一起。
主要优点:
- 简化了
指令系统和程序设计 - 简化了
编译程序 - 便于实现
一致性校验 - 能由硬件
自动变换数据类型 - 支持
数据库系统的实现与数据类型无关的要求 - 为软件
调试和应用软件开发提供了支持
两个问题:
- 每个数据字因增设标志符,会增加程序所占的主存空间
- 采用标志符会降低指令的执行速度
(2)数据描述符
数据描述符是与数据分开存放,用于描述所要访问的数据是整块的还是单个的,访问该数据块或数据元素所要的地址以及其他信息等。主要用于向量、数组、记录等数据。
描述符
101 各种标志位 长度 地址
数据
000 数据
数据描述符与标志符数据表示的差别(简答)
标志符是和每个数据相连的,合存在一个存储单元中,描述单个数据的类型特征;
数据描述符则是与数据分开存放,用于描述所要访问的数据是整块的还是单个的,访问该数据块或数据元素所要的地址以及其他信息等。
2 向量、数组数据表示
增设向量、数组数据表示,组成向量机
引入向量、数组数据表示不止能加快形成元素地址,更重要的是便于实现把向量各元素成块预取到中央处理机,用一条向量、数组指令流水或同时对整个向量、数组高速处理。用硬件判断下标是否越界,并让越界判断和元素运算并行。
3 堆栈数据表示
有堆栈数据表示的计算机称为堆栈计算机
堆栈计算机表现于:
- 由高速寄存器组成的硬件堆栈,并附加控制电路,让它与主存中的堆栈区在逻辑上构成整体,使堆栈的
访问速度是寄存器的,容量是主存的 - 有丰富的
堆栈操作指令且且功能很强,可直接对堆栈中的数据进行各种运算和处理 - 有力地
支持了高级语言程序的编译 - 有力地
支持了子程序的嵌套和递归调用。子程序调用另一子程序称嵌套调用,子程序直接或经子程序间接调用自己称直接或间接递归调用。
2.1.3 引入数据表示的原则
原则1:看系统的效率是否有显著提高,包括实现时间和存储空间是否有显著减少
原则2:看引入这种数据表示后,其通用性和利用率是否提高
2.1.4 浮点数尾数基值大小和下溢处理方法的选择
1 浮点数尾数基值的选择
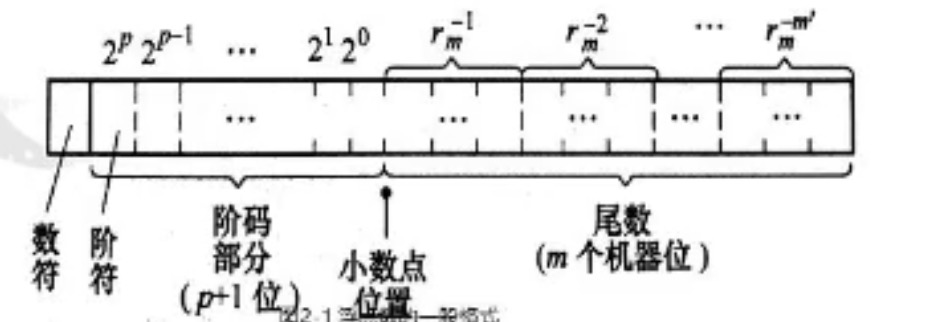
数符:最前面的+或者-,表示这个数的正负
阶符:阶码的正负
阶码p:浮点数尾数的总数位(小数点后有几位阶码就是多少),尾数右移一个数位则加1,大多题目中,p其实代表的是阶值的位数(bit数),实际的阶码是阶符|阶值,也就是p+1位
尾数:m个机器位
m:计算机位数,比如8位计算机则为8
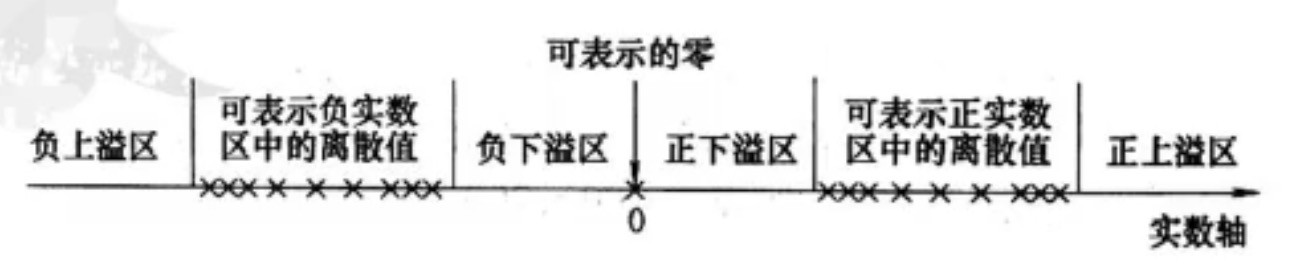
浮点数阶值的位数p主要影响两个可表示区的大小,即可表示数的范围大小,而尾数的位数m主要影响在可表示区中能表示值的精度。由于计算机中尾数位数限制,实数难以精确表示,因此,不得不用较为接近的可表示数来近似表示,产生的误差大小就是数的表示精度。
rm: 浮点数尾数的基值,比如2、4、8、10、16等(几进制就是几)
m’:浮点数尾数的计算机位数, m’=m/log2 rm,表示一个计算机字能存几个基值
如在二进制下,1.0010101 * 2 100,rm为2,阶值为100,m和计算机相关,log2 rm为 1,若m为8,m’为8
如在十进制下,18.625,rm为10,log2 rm为4,若m为8,m’为2
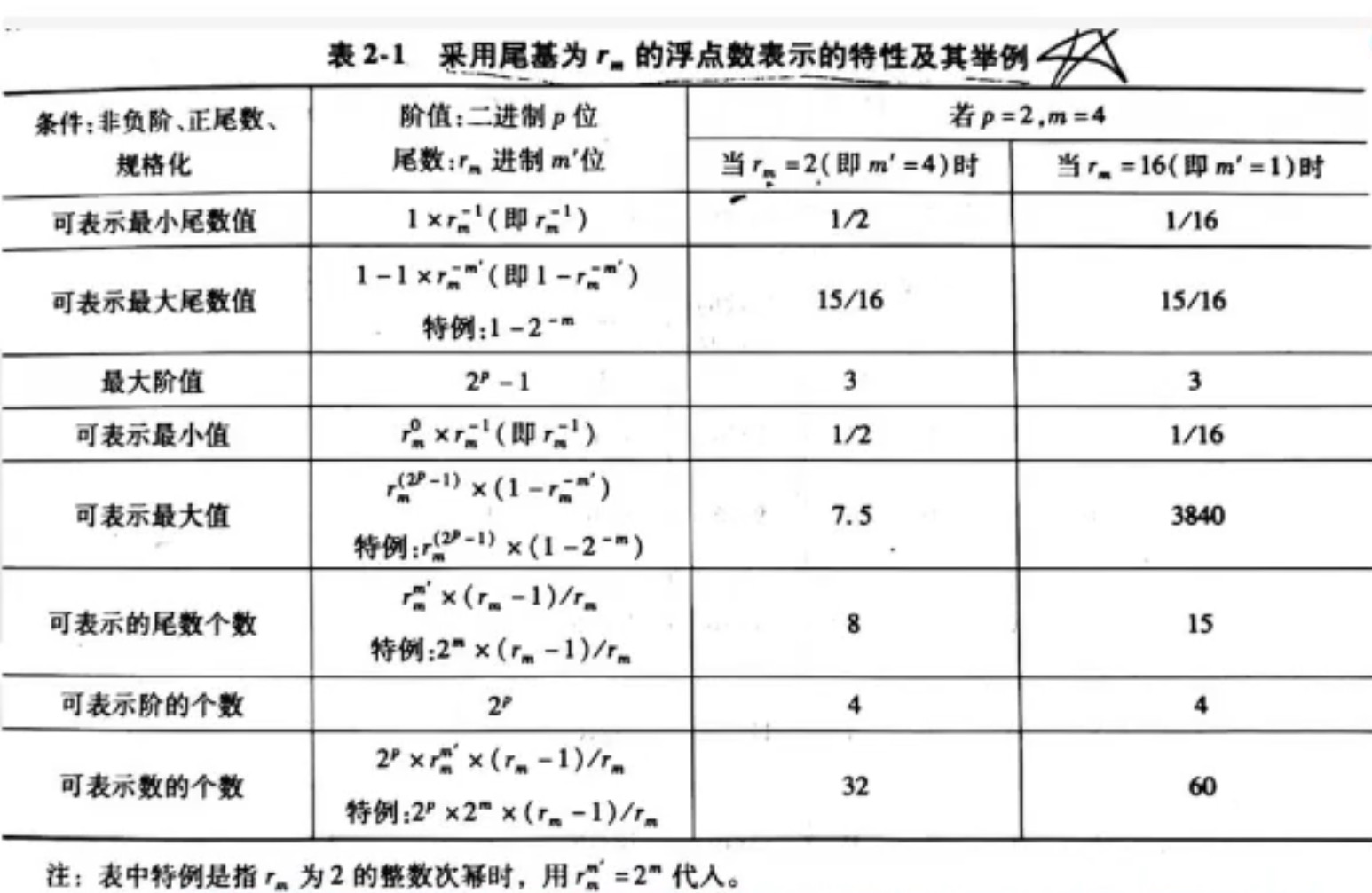
以 p=2,m=16,rm=4为例,可计算出m’=m/log2rm=16/2=8
可表示最小尾数值:由于小数点后第一位必为1,那么小数点后只有一位rm就是最小(剩下的都是0),同时,我们要在基值的所有取值中取最小,最终得rm^-1,如本例中,最小即为4进制的0.1000 0000,而4进制(可取为0,1,2,3,但是第一位不可取0)的最小为1,转为10进制即为1/4
可表示的最大尾数值:小数点后的每一位都取最大(每一位对应基值的可选取值选最大),即为最大,如本例中即为4进制的0.3333 3333,每一位我们都取3;观察得到,最后一位加1就可以进位到小数点前面得到1,最后一位为1是rm-m’,所以答案是1-rm-m’,答案也就是1-4-8
最大阶值:p代表实际阶值的位数,阶值是以2进制存储的,所以最大就是2p-1,答案也就是3
可表示最小值:最小值时,实际阶值为0,rm的实际阶值次方为1,乘以最小尾数,即rm-1,本例答案也就是1/4
可表示最大值:rm的最大实际阶值次方乘以最大尾数,所以就是rm(2p(2的p次方)-1).(1-rm-m’),本例答案也就是64 . (1-4^-8)
可表示的尾数个数:尾数中每一位可以有rm种组合(0,1,2,…rm-1),一共有m’位,但是第一位不能取0,所以第一位只有(rm-1)种取法,所以可表示的尾数个数为rm(m’-1) . (rm-1),本例答案也就是47 . 3
可表示的阶的个数:p代表实际阶值的位数,所以一共有2p种取法,本例答案也就是4
可表示数的个数:可表示的尾数个数乘以可表示的阶的个数,即2p . rm(m’-1) . (rm-1),本例答案也就是48 . 3
得到的结论:
- 可表示数的范围:基值越大,可表示数的范围越大
- 可表示数的个数:基值越大,可表示数的个数越多
- 数在数轴上的分布:基值越大,数轴上分布越稀
- 可表示的精度:基值越大,精度越低
- 运算中的精度损失:基值越大,精度的损失越小
- 运算速度:基值越大,运算速度越高
2 浮点数尾数的下溢处理方法
- 截断法:将尾数超出计算机字长的部分截去。优点实现
最简单,不增加硬件,不需要处理时间,不需要处理时间;缺点最大误差较大,平均误差大且无法调节 - 舍入法:规定字长外增加一位附加位,下溢处理时附加位加1。优点实现简单,增加的硬件很少,最大误差小,平均误差接近于0;缺点处理速度慢
- 恒置1法:最低位恒置为1。优点实现
最简单,平均误差接近0,不增加硬件,不需要处理时间,缺点最大误差最大,比截断法还大 - 查表舍入法:用ROM或PLA存放下溢处理表,处理时查表。速度快,平均误差可调节到0.缺点是硬件投入大。
2.2 寻址方式
定义:指令按什么方式寻找(或访问)到所需的操作数或信息的。
2.2.1 寻址方式的三种面向
面向主存的寻址:面向主存的寻址主要访问主存,少量访问寄存器面向寄存器的寻址:主要访问寄存器,少量访问主存和堆栈面向堆栈的寻址:主要访问堆栈,少量访问主存和寄存器
2.2.2 寻址方式在指令中的指明
- 占用
操作码中的某些位来指明 - 不占用操作码,而是在
地址码部分专门设置寻址方式位字段指明
2.2.3 程序在主存中的定位技术
逻辑地址:程序员编程用的地址- 主存
物理地址:程序在主存中的实际地址
定位技术有
- 静态再定位:在目的程序装入
主存时,由装入程序用软件方法把目的程序的逻辑地址变换成物理地址,程序执行时,物理地址不再改变,称这种定位技术为静态再定位 - 动态再定位:在执行每条指令时才形成访存物理地址的方法称为动态再定位
- 变址寻址:是对诸如
向量、数组等数据块运算的支持,以便于实现程序的循环 - 基址寻址:是对
逻辑地址空间到物理地址空间变换的支持,以利于实现程序的动态再定位
- 变址寻址:是对诸如
- 虚实地址映像表:查表映射
2.2.4 物理主存中信息的存储分布
信息在存储器中按整数边界存储:为了使任何时候所需的信息都只用一个存储周期访问到,要求信息在主存中存放的地址必须是该信息宽度(字节数)的整数倍。
2.3 指令系统的设计和优化
2.3.1 指令系统设计的基本原则
指令系统是程序设计者看计算机的主要属性,是软、硬件的主要界面,它在很大程度上决定了计算机具有的基本功能。
考虑:如何有利于满足系统的基本功能;有利于优化计算机的性能价格比;有利于指令系统今后的发展和改进。
指令系统的设计包括指令的功能(操作类型、寻址方式和具体操作内容)和指令格式的设计。
步骤:
- 1.根据应用,初拟出指令的分类和具体的指令
- 2.试编出该指令系统设计的各种高级语言的编译程序
- 3.对各种算法编写大量的测试程序并进行模拟测试,看指令系统的操作码和寻址方式效能是否都比较高
- 4.将程序中高频出现的指令串复合改成一条强功能新指令,即改用硬件方式实现;而将频度很低的指令操作改成用基本的指令组成的指令串来完成,即用软件方式实现。
非特权指令:应用程序员和系统程序员都可以使用。
特权指令:只供系统程序员使用。
编译程序设计者对指令系统设计要求(简答):
-
- 规整性。对相似的操作做相同的规定。
-
- 对称性。
-
- 独立性和全能性。
-
- 正交性。
-
- 可组合性
-
- 可扩充性
系统机构设计者对指令系统的要求(简答):
-
- 指令码密度适中
-
- 兼容性
-
- 适应性
2.3.2 指令操作码的优化
指令=操作码+地址码
就指令格式的优化来说,是指如何用最短的位数来表示指令的操作信息和地址信息,使程序中指令的平均字长最短。
研究操作码的优化表示主要是为了缩短指令字长,减少程序总位数及增加指令字能表示的操作信息和地址信息。
哈夫曼编码,构造哈夫曼树 (综合)
数据结构中的做法:依次选最小的两个,加起来的父节点值再加入原序列,依次执行下去,然后小的那边用1,大的那边用0,最后从根节点到叶节点的值,就是对应的哈夫曼编码。
指令操作码优化中可以的做法:由于哈夫曼树是一颗二叉树,而且总频度为1.0,那么根节点权值为1.0,我们可以从根节点开始构建,依次选取最大的来构建,依然是大的那边用0,小的用1,最后根节点到叶子结点的值,就是每个节点的哈夫曼编码。
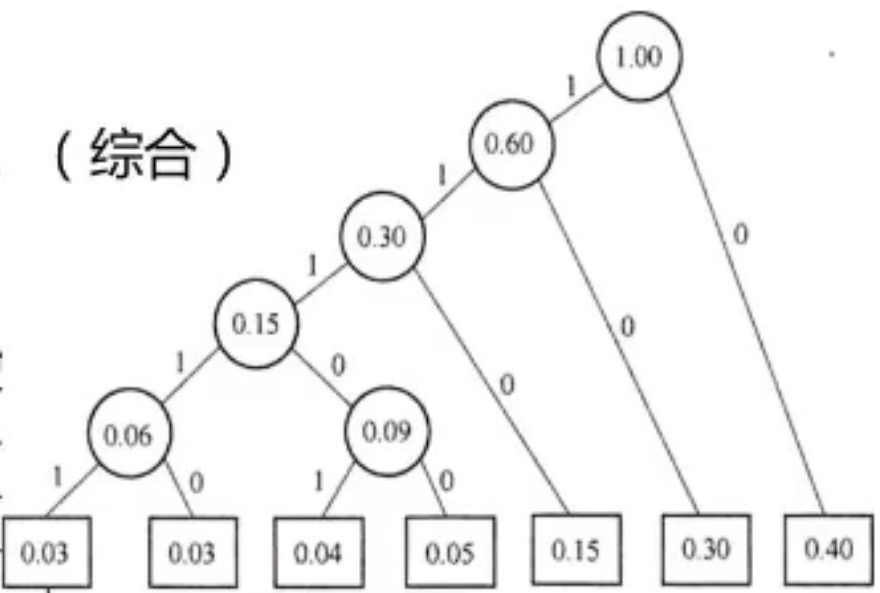
扩展操作码编码
在哈夫曼编码的基础上,将码长整合成少量的几个码长。原则是高概率的用短码,低概率长码。
15/15/15编码法:4/4/4,前面每分块最后一个1111用来给后面的作拓展
8/64/512编码法:3/6/9,前面每块分块的第一位1的各个值用来给后面用来拓展
2.3.3 指令字格式的扩展
指令字格式优化的措施有:
-
- 采用
扩展操作码,以缩短操作码的平均码长
- 采用
-
- 采用诸如基址、变址、相对、寄存器、寄存器间接、段式存放、隐式指明等
多种寻址方式,以缩短地址码的长度,并在有限的地址长度内提供更多的地址信息
- 采用诸如基址、变址、相对、寄存器、寄存器间接、段式存放、隐式指明等
-
- 采用0、1、2、3
等多种地址制,以增强指令的功能,这样从宏观上就越能缩短程序的长度,并加快程序的执行速度
- 采用0、1、2、3
-
- 在同种地址制内再采用
多种地址形式
- 在同种地址制内再采用
-
- 在维持指令字在存储器中按整数边界存储的前提下,使用
多种不同的指令字长度
- 在维持指令字在存储器中按整数边界存储的前提下,使用
2.4 指令系统的发展和改进
2.4.1 两种途径和方向(CISC和RISC)
CISC:进一步增强原有指令的功能以及设置更为复杂的新指令以取代原先由软件子程序的功能,实现软件功能的硬化。按此方向发展,机器指令系统日益庞大和复杂。称用这种方式设计CPU的计算机为复杂指令系统计算机。C:complex
RISC:通过减少指令种类和简化指令功能来降低硬件设计的复杂度,提高指令的执行速度。按次方向发展,机器指令系统精简。称用这种方式设计CPU的计算机为精简指令系统计算机。R:reduce
2.4.2 按CISC方向发展和改进指令系统
1.面向目标程序的优化实现改进
- 途径1:通过对大量已有机器的
机器语言程序及其执行情况,统计各种指令和指令串的使用频度来加以分析和改进。 - 途径2:增设强功能复合指令来取代原先由常用宏指令或子程序实现的功能,由
微程序解释实现。
2.面向高级语言的优化实现改进
尽可能缩短高级语言和机器语言的语义差距,支持高级语言编译,缩短编译程序长度和编译时间。
- 途径1:通过对源程序中各种高级语言语句的
使用频度进行统计来分析改进 - 途径2:如何面向编译,
优化代码生成来改进,增强规整性 - 途径3:
改进指令系统,使它与各种语言间的语义差距都有同等的缩小 - 途径4:采用让计算机具有分别面向高级语言的
多种指令系统、多种系统结构的面向问题动态自寻优的计算机系统。 - 途径5:发展
高级语言计算机
3.面向操作系统的优化实现改进
主要目标是如何通过缩短操作系统与计算机系统结构之间的语义差距,进一步减少运行操作系统的时间和节省操作系统软件所占用的存储空间。
- 途径1:通过对操作系统中常用指令和指令串的
使用频度进行统计分析来改进。 - 途径2:考虑如何
增设专用于操作系统的新指令。 - 途径3:把操作系统
重频繁使用的,对速度影响大的机构型软件子程序硬化或固化,改为直接用硬件或微程序解释实现 - 途径4:发展让操作系统由专门的处理机来执行的功能
分布处理系统结构
2.4.3 按RISC方向发展和改进指令系统
1.CISC的问题(简答)
-
- 指令系统
庞大,一般指令在200条以上
- 指令系统
-
- 许多指令的操作
繁杂,执行速度很低,甚至不如用几条简单、基本的指令组合实现
- 许多指令的操作
-
- 由于指令系统庞大,使高级语言编译程序选择
目标指令的范围太大,因此,难以优化生成高效机器语言程序,编译程序也太长、太复杂
- 由于指令系统庞大,使高级语言编译程序选择
-
- 由于指令系统庞大,各种指令的使用频度都不会太高,且
差别很大,其中相当一部分指令的利用率很低。
- 由于指令系统庞大,各种指令的使用频度都不会太高,且
2.设计RISC的基本原则(简答)
-
- 确定指令系统时,指
选择使用频度很高的那些指令,再增加少量能有效支持操作系统、高级语言实现及其他功能的指令,大大减少指令条数,一般使之不超过100条。
- 确定指令系统时,指
-
减少指令系统所用寻址方式种类,一般不超过两种。简化指令的格式限制在两种之内,并让全部指令都是相同长度。
-
- 让所有指令都在
一个机器周期内完成。
- 让所有指令都在
-
扩大通用寄存器数,一般不少于32个,尽量减少访存,所有指令只有存(STORE),取(LOAD)指令访存,其他指令一律只对寄存器操作。
-
- 为提高指令执行速度,
大多数指令都用硬联控制实现,少数指令采用微程序实现。
- 为提高指令执行速度,
-
- 通过
精简指令和优化设计编译程序,简单、有效地支持高级语言的实现。
- 通过
3.设计RISC结构采用的基本技术(简答)
-
- 按设计RISC的
一般原则来设计
- 按设计RISC的
-
- 逻辑实现采用
硬联和微程序相结合
- 逻辑实现采用
-
- 在CPU中设置
大量工作寄存器并采用重叠寄存器窗口
- 在CPU中设置
-
- 指令用
流水和延迟转移
- 指令用
-
- 采用高速缓冲存储器
Cache,设置指令Cache和数据Cache分别存放指令和数据
- 采用高速缓冲存储器
-
- 优化设计
编译系统
- 优化设计
4. RISC技术的发展
采用RISC的好处
-
- 简化指令系统设计,适合VLSI实现
-
- 提高计算机的执行速度和效率
-
- 降低设计成本,提高系统的可靠性
-
- 可直接支持高级语言的实现,简化编译程序的设计
RISC的问题与不足
-
- 由于指令少,复杂功能需要多条RISC指令才能完成,加重了汇编语言设计的负担,增加了机器语言程序的长度,占用存储空间多,加大了指令的信息流量
-
- 对浮点运算的执行和虚拟存储器的支持随有很大加强,单仍显得不足
- RISC计算机的编译程序比CISC难写

















 1645
1645

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









