








大语言模型的进展催生出了ChatGPT这样的应用,让大家对“第四次工业革命”和“AGI”的来临有了一些期待,也作为部分原因共同造就了美股2023年的繁荣。LLM和视觉的结合也越来越多:比如把LLM作为一种通用的接口,把视觉特征序列作为文本序列的PrefixToken,一起作为LLM的输入,得到图片或者视频的caption;也有把LLM和图片生成模型、视频生成模型结合的工作,以更好控制生成的内容。当然2023年比较热门的一个领域便是多模态大模型,比如BLIP系列、LLaVA系列、LLaMA-Adapter系列和MiniGPT系列的工作。LLM的预训练范式也对视觉基础模型的预训练范式产生了一定的影响,比如MAE、BEIT、iBOT、MaskFEAT等工作和BERT的Masked Language Modeling范式就很类似,不过按照GPT系列的自回归方式预训练视觉大模型的工作感觉不是特别多。下面对最近视觉基础模型的生成式预训练的工作作一些简单的介绍。
LVM
《Sequential Modeling Enables Scalable Learning for Large Vision Models》是UC Berkely和Johns Hopkins University在2023提出的一个影响比较大的工作,视觉三大中文会议也在头版头条做了报道,知乎的讨论也比较热烈。
-
Sequential Modeling Enables Scalable Learning for Large Vision Models(https://arxiv.org/abs/2312.00785)
-
https://github.com/ytongbai/LVM
-
https://yutongbai.com/lvm.html
按照自回归的生成式训练模型的工作之前也有,比如Image Transformer和Generative Pretraining from Pixels等,不过无论是训练的数据量还是模型的参数量都比较小。LVM把训练数据统一表述成visual sentences的形式。对训练数据、模型参数量都做了Scaling,并验证了Scaling的有效性和模型的In-context推理能力。
本文的一大贡献便是数据的收集和整理,和训练LLM的文本数据一样规模的视觉数据在之前缺乏的,因此从开源的各种数据源出发,得到了 1.64billion 图片的数据集 UVDv1(Unified Vision Dataset v1)。文中对数据的来源以及将不同数据统一为visual sentences描述形式的方法做了详细的介绍Fig 1,可以refer原文更多的细节。

Fig 1 Visual sentences 能够将不同的视觉数据格式化为统一的图像序列结构
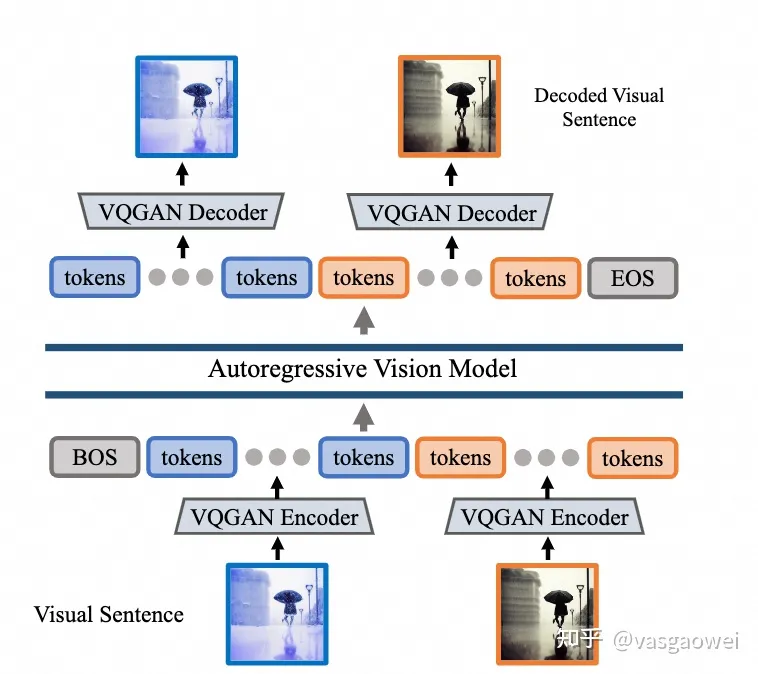
Fig 2
模型的结构如图Fig 2所示,主要包含三部分:Tokenizer、Autoregressive Vision Model和DeTokenizer。
其中Tokenizer和DeTokenizer取自于VQ-GAN,codebook大小为8192,输入图片分辨率为,下采样倍数为16,因此一张输入图片对应的Token数目为,这一个模块通过LAION 5B数据的1.5B的子集来训练。
这样对于一个visual sentence,会得到一个Token的序列(和目前的很多多模态大模型不一样,这儿没有特殊的token用以指示视觉任务的类型),作为Autoregressive Vision Model的输入,通过causal attention机制预测下一个Token。文中的自回归视觉模型的结果和LLaMA的结构一样,输入的token 序列的长度为4096个token(16张图片),同时在序列的开始和结束分别会放置[BOS](begin of sentence)和[EOS](end of sentence),代表序列的开始和结束。整个模型在UVD v1(包含420 billion tokens)数据上训练了一个epoch,模型的大小包括四种:300 million、600 million、1 billion和3 billion。
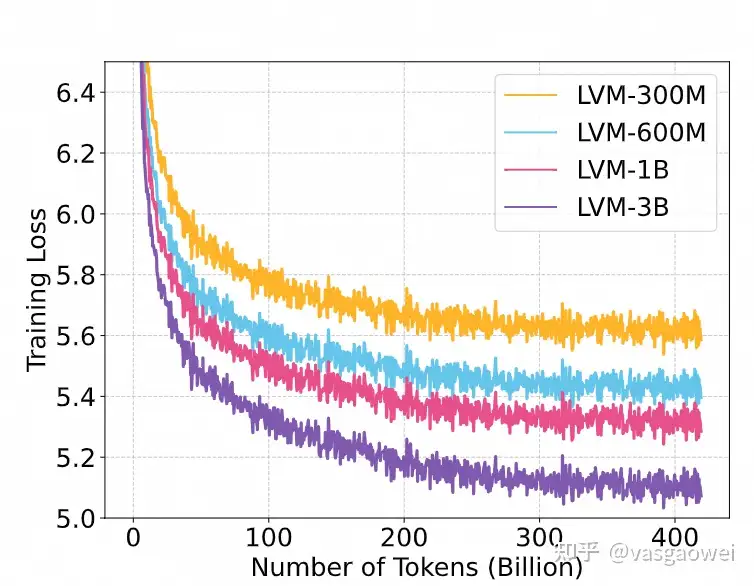
Fig 3
从Fig 3可以看出,训练过程中,模型的loss一直在下降,而且模型参数量越大,loss下降越快
更多的实验结果分析可以refer原文。
EMU
《Generative Pretraining in Multimodality》是BAAI、THU和PKU的工作,提出了多模态大模型EMU,EMU的输入是image-text interleaved的序列,可以生成文本,也可以桥接一些扩散模型的Decoder生成图片。
-
https://arxiv.org/abs/2307.05222
-
https://github.com/baaivision/Emu

Fig 4
EMU的结构如图Fig 4所示,包含四个部分,Visual Encoder(文中用的EVA-02-CLIP)、Causal Transformer、Multimodal Modeling(LLaMA)和Visual Decoder(Stable Diffusion)。
对于输入的 image-text-video interleaved的序列,EVA-CLIP会提取图片的特征,同时通过causal Transformer得到个visual embeddings ,即。对于包含个frame的视频,则会得到个视觉embedding。在每一张图片或者每一帧的特征序列的开始和结束分别有特殊的token,即[IMG]和[/IMG]。
text通过文本的tokenizer得到文本特征序列,和视觉信息对应特征序列连接,并在序列的开始和结束处分别添加表述开始和结束的特殊token,即[s]和[/s]。最后得到的多模态序列作为LLaMA的输入,得到文本输出,而LLaMA输出的视觉特征序列作为扩散模型的条件输入,得到生成的图像。
Emu用Image-text pair的数据、Video-text pair的数据、Interleaved Image and Text的数据以及Interleaved Video and Text的数据进行预训练。对于预测的文本token来说,损失函数为预测下一个token的cross entropy loss;对于视觉token来说,则是的回归损失。
对Emu预训练之后,会对图片生成的Stable Diffusion的Decoder进行微调。微调的时候,只有U-Net的参数会更新,其他的参数固定不变。训练数据集为LAION-COCO和LAION-Aesthetics。每一个训练样本的文本特征序列的结尾处都会添加一个[IMG] token,最后通过自回归的方式得到个视觉特征ÿ
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 658
658

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









