







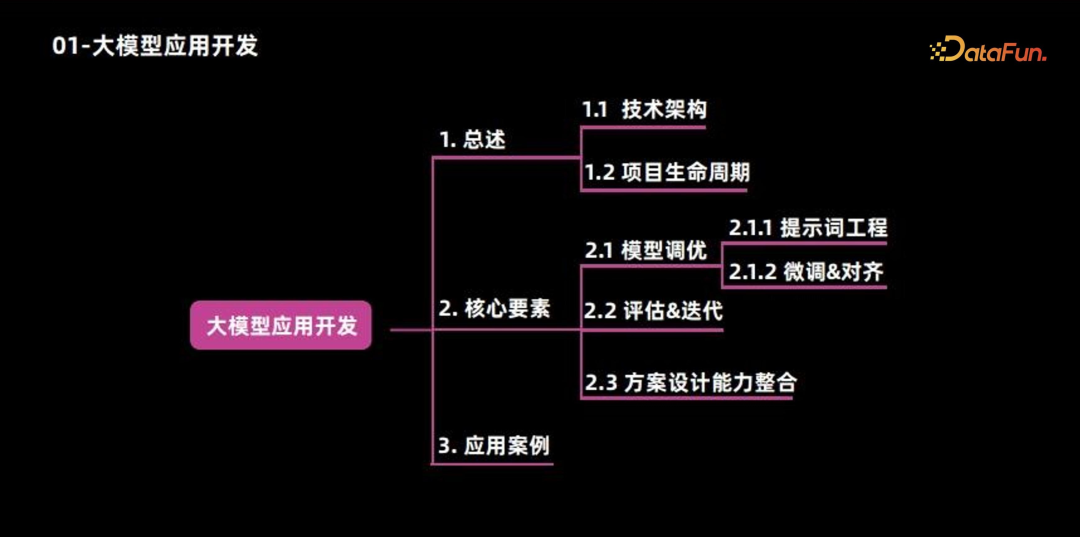
导读 本文将介绍大模型应用开发相关的知识地图。
主要包括以下三大部分:
-
总述
-
核心要素
-
应用案例
01
总述
1. 技术架构
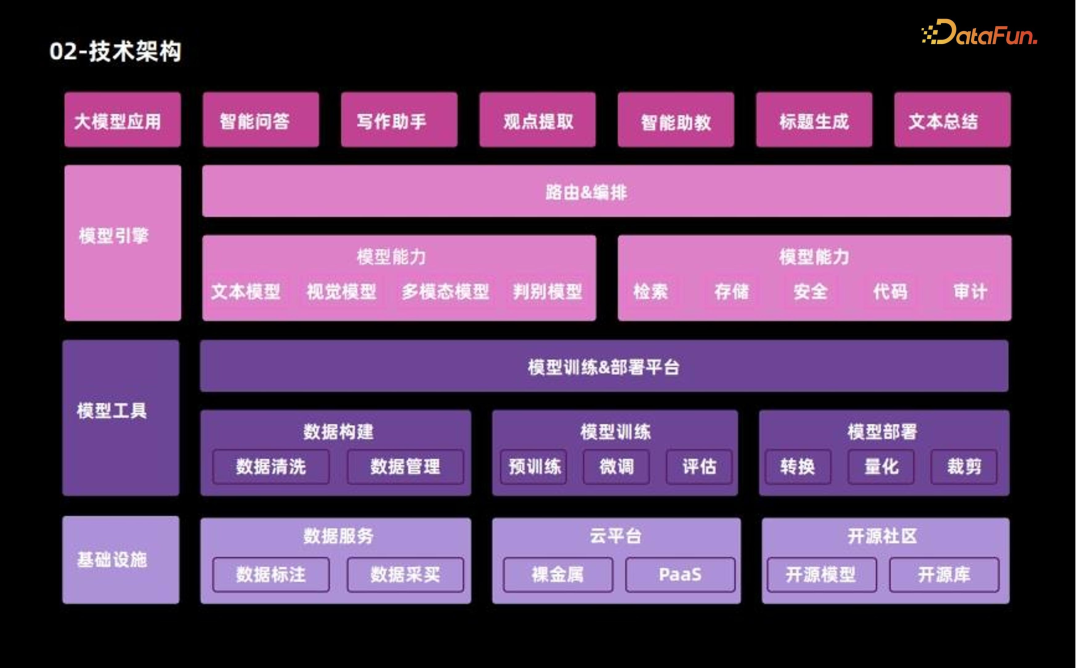
在构建大型模型应用时,技术架构的规划至关重要。整体架构可被划分为四个层次:基础设施层、模型工具层、模型引擎层及大模型应用层。
(1)基础设施层:涵盖了数据服务、云平台及开源社区等多个方面,为应用开发提供坚实的基础。
-
数据服务:大规模模型对数据的要求极高,厂商可通过自主标注数据或采购外部数据的方式满足需求。
-
云平台:大规模模型的训练和推理过程对算力资源的需求也十分庞大,拥有自身基础架构的厂商可自行采购裸金属或利用现有云平台所提供的 PaaS 服务来构建计算平台。
-
开源社区:活跃度极高,众多优秀的开源模型如 LLama、micheal 等不断涌现,为训练和推理提供了高效的工具。企业通常通过整合开源模型、数据和代码方案,以迅速建立自身的模型能力和推理训练能力;
(2)模型工具层:是模型训练与部署的平台,构建于基础设施层之上,涵盖了从数据构建、模型训练到模型部署的全过程。
-
数据构建:涵盖了数据清洗、分类和管理等工作。
-
模型训练:涵盖了模型预训练、微调和评估等工作。
-
模型部署:涵盖了模型转换、量化和裁剪等工作。
(3)模型引擎层:主要作用是实现路由和编排,将不同的模型能力进行整合和协调。
模型包括文本模型、视觉模型、多模态模型以及分类判别模型等,然而单一的模型并不能直接为最外层的应用提供所需的所有功能,需要根据各种模型能力进行编排,从而提供更加精准和高效的服务,包括但不限于检索、存储、安全、代码、审计等工具能力的集合。举个例子,在智能问答的应用中,不仅仅需要依赖一个生成模型,同时也需要结合内容检索和安全性识别的能力。
(4)大模型应用层:是整个架构的最高层,这些应用包括智能问答系统、写作助手、观点提取、智能助教、标题生成以及文本总结等。
对于规模较大的企业,可能需要建设好这四层。但对于小规模的企业和创业团队来说,许多开源平台和云平台都提供了包含模型引擎、模型工具和基础设施的服务。因此只需要利用现有的资源,针对具体的业务场景,专注于做好路由和编排相关的工作,或者偶尔准备少量数据,进行少量模型微调,就能以相对较低的成本实现需求。
2. 应用开发生命周期
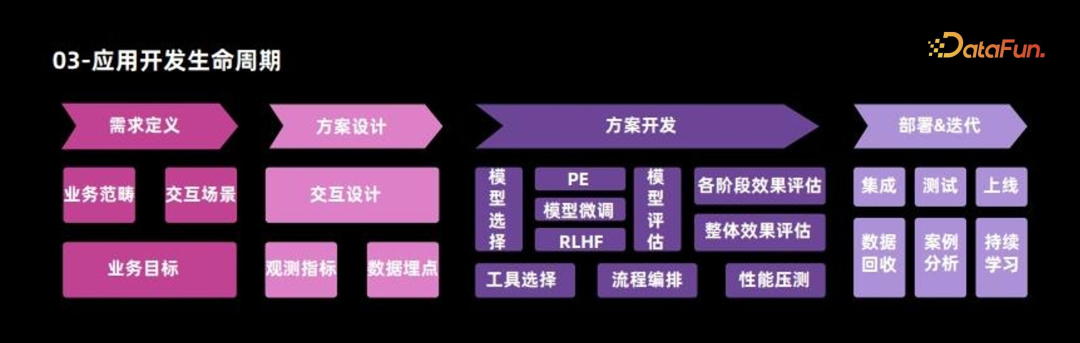
当具备相应技术能力时,开发大型模型应用需遵循一般项目开发的生命周期,包括需求定义、方案设计、方案开发以及部署 & 迭代等四个主要环节。
需求定义与方案设计阶段,主要从两个方向进行考量:
-
首先,明确业务范畴与交互场景。这要求界定产品功能中哪些部分依赖大模型支持并确定其交互边界。以聊天功能为例,需要界定大模型在其中的作用范围和交互限制,通常大模型与用户的交互界面是一个聊天框,因此,交互设计应以聊天为主,并支持流式输出,这是设计过程中需考虑的第一个方面。
-
其次是关注业务目标。以聊天为例,若产品属性为工具类,如智能助手,业务目标应为用户需求达成率,衡量这一目标,可观察用户点赞数量或正反馈数量;若产品属性为情感陪伴,则应关注对话轮次和对话次数,在这一场景下,期望 AI 与用户进行尽可能多的交流和陪伴,因此数据埋点需相应调整。
方案开发阶段,也包括两个方向:
-
模型选择是关键步骤,需要依据不同应用场景挑选最合适的模型。例如,针对多轮对话场景,更倾向于选择对话效果更优的模型,如 LLaMA chat 等模型;在知识问答方面,更倾向于选择具有高检索能力和安全性的工具。在此基础上进行效果调优,包括 PE、模型微调以及强化学习等。调优完成后,将对模型本身的效果进行评估,评估每个阶段的效果均达到预期后,还需对整体效果进行综合评估。
-
另一方面是选择相应的工具,通过流程编排来实现整体的互动效果。最后考虑到大模型具有较高的参数量和推理成本,需要对最终
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 7258
7258

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









