




 提出一种无需训练网络即可评估其性能的神经架构搜索(NAS)方法,大幅减少搜索时间,提升效率。通过构建结构得分函数,该方法在Cifar10、Cifar100和Imagenet数据集上展现出了与实际验证精度正相关的趋势。
提出一种无需训练网络即可评估其性能的神经架构搜索(NAS)方法,大幅减少搜索时间,提升效率。通过构建结构得分函数,该方法在Cifar10、Cifar100和Imagenet数据集上展现出了与实际验证精度正相关的趋势。
文章题目:Neural Architecture Search without Training
链接:link https://arxiv.org/pdf/2006.04647
论文内容
论文阅读笔记,帮助记忆的同时,方便和大家讨论。因能力有限,可能有些地方理解的不到位,如有谬误,请及时指正。
常规的NAS在训练和单个结构验证的过程都非常耗时,动辄几百上千个GPU小时。本文在富含各种网络结构的数据集NAS-Bench-201中,根据相关性频谱得到最终的验证精度和网络结构的训练无关,因此提出了一个全新的观点:不训练网络,就能大体知道网络的表现,从而指导NAS训练。
如果在搜索的过程中不训练子网络,那么大量训练耗时以及为加速而共享权重引发的弊端都能避免。NAS-Bench-201所有sample出的网络有一个共同的框架,由3个normal block和两个residual block组成,每个block有N个cell。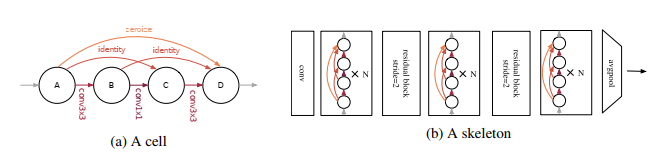
作者创新性的构建了结构的得分函数:
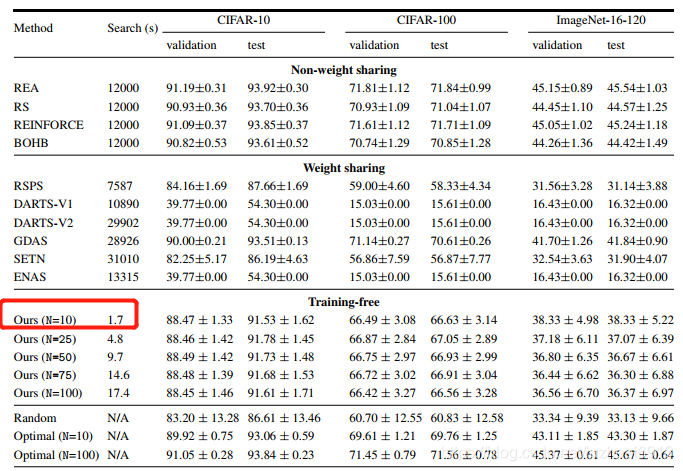
并且从Cifar10, Cifar100和Imagenet数据集的表现看出,虽然存在一定的噪声,但是其设计的得分函数和网络实际的验证精度成正向关系。并且作者做了详细的消融学习验证了该方法的可行性,但是哪种cell对精度有利却是难以说明的事情。
从三大数据集的结果可以看出,本文的方法完胜权重共享类的NAS,虽然性能不能超越非权重共享类的NAS,但是搜索时间确实秒级,快了几个数量级。 笔者认为这一发现,有如黑暗中的明灯,或许使得NAS不再是巨头门的专宠。

















 1120
1120

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









