






 本文详细介绍了一个使用PySpark进行单词计数的实际案例。通过在E盘根目录创建的test.txt文件,文章演示了如何利用PySpark的SparkContext和RDD进行文本文件的读取、单词的拆分、计数及结果的输出。该过程展示了PySpark的基本操作流程,适用于初学者了解并实践PySpark的基础用法。
本文详细介绍了一个使用PySpark进行单词计数的实际案例。通过在E盘根目录创建的test.txt文件,文章演示了如何利用PySpark的SparkContext和RDD进行文本文件的读取、单词的拆分、计数及结果的输出。该过程展示了PySpark的基本操作流程,适用于初学者了解并实践PySpark的基础用法。
E盘根目录创建test.txt输入测试内容如下:
this is a test
this very good
you is very good
what are you
完整代码如下:
from pyspark import SparkContext,SparkConf
def wordcount():
txtfile=r'E:\test.txt'
conf=SparkConf()
conf.setAppName("worlcount")
conf.setMaster("local[*]")
sc = SparkContext(conf=conf)
rdd=sc.textFile(txtfile)
rdd.flatMap(lambda x:x.split( )).map(lambda x:(x,1)).reduceByKey(lambda x,y:x+y).foreach(lambda x:print(x))
if __name__ == '__main__':
wordcount()
pycharm直接运行,或者使用命令提交:spark-submit --master local E:\geotrellis\pyspark_dem\base\wordcount.py
执行结果:
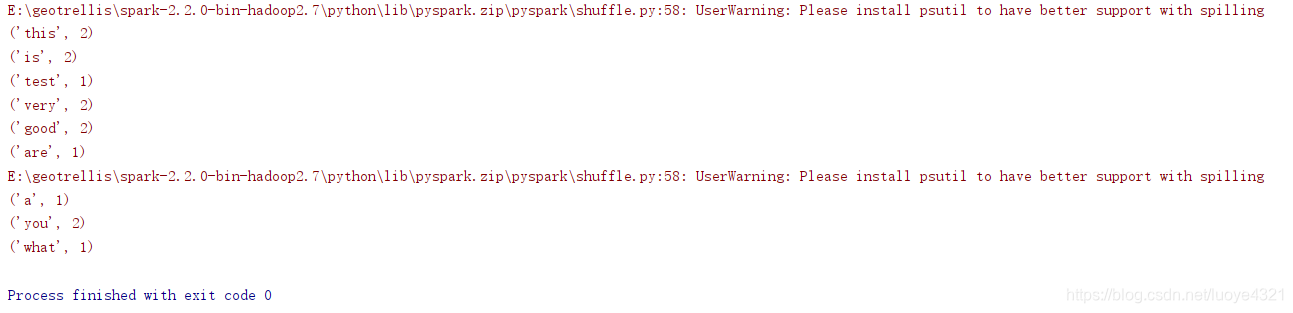
说明执行成功。

















 2654
2654

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









