



 本文深入探讨了串处理中的关键算法,包括最小表示法、扩展KMP(Z算法)、及Duval算法求Lyndon分解。介绍了如何求解字典序最小的循环同构、两串的最长公共前缀及字符串的Lyndon分解。
本文深入探讨了串处理中的关键算法,包括最小表示法、扩展KMP(Z算法)、及Duval算法求Lyndon分解。介绍了如何求解字典序最小的循环同构、两串的最长公共前缀及字符串的Lyndon分解。
所有下标均从1开始
最小表示法
给定一个串,求字典序最小的循环同构。
我们把串复制一遍接在后面,然后求出 [ 1 , N ] [1,N] [1,N]开始的长为 N N N的子串中最小的
先设 i = 1 , j = 2 i=1,j=2 i=1,j=2
然后暴力找出 i i i和 j j j往后匹配的第一个不同的位置,记为 i + k i+k i+k和 j + k j+k j+k
如果 S i + k < S j + k S_{i+k}<S_{j+k} Si+k<Sj+k,说明 i i i比 j j j优,所以 j j j不是最优解;然后发现 i + 1 i+1 i+1比 j + 1 j+1 j+1优,所以 j + 1 j+1 j+1不是最优解……这样可以让 j j j直接跳到 j + k + 1 j+k+1 j+k+1。
S i + k > S j + k S_{i+k}>S_{j+k} Si+k>Sj+k同理
如果 i = j i=j i=j,随便让一个 + 1 +1 +1即可
两个指针都不能超过 N N N,一个超过之后另一个就是答案
因为所有位置都会被遍历,而最优解一定不会被丢掉,所以正确性可以保证。
复杂度显然是 O ( N ) O(N) O(N)
#include <iostream>
#include <cstdio>
#include <cstring>
using namespace std;
char s[10005];
int main()
{
int T;
scanf("%d",&T);
while (T--)
{
scanf("%s",s);
int n=strlen(s);
int i=0,j=1;
while (i<n&&j<n)
for (int k=0;;k++)
{
if (s[(i+k)%n]!=s[(j+k)%n])
{
if (s[(i+k)%n]>s[(j+k)%n])
i+=k+1;
else
j+=k+1;
if (i==j) j++;
break;
}
if (k==n) goto end;
}
end:
printf("%d\n",min(i,j)+1);
}
return 0;
}
(远古代码,和上面讲的略有不同,仅供参考)
扩展KMP
官方名称应该叫Z算法,不知道为啥传到国内就变成扩展KMP了
但实际上思想和manacher很像所以应该叫扩展马拉车
解决的问题是给两个串 S , T S,T S,T,求 T T T的每个后缀和 S S S 的最长公共前缀
先把
S
S
S接在
T
T
T后面,中间加个#之类的东西 把这个串记为
A
A
A
然后设 p i p_i pi表示 A A A的从 i i i开始的后缀和 T T T(也可以是 A A A)的最长公共前缀
并且设公共前缀扩展到的最右位置为 m x mx mx,取到这个最大值的 i i i为 x x x
然后 i i i从 2 2 2开始遍历(因为 p 1 p_1 p1没有意义还会把算法搞砸)
如果 i < m x i<mx i<mx
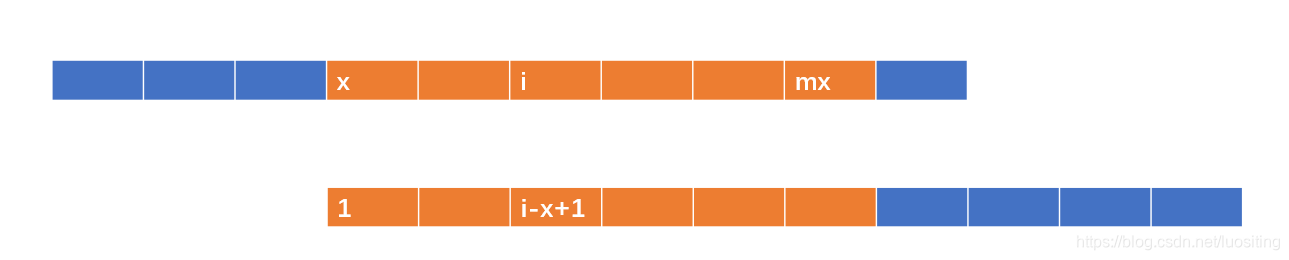
因为上下橙色位置相同,所以
p
i
=
p
i
−
x
+
1
p_i=p_{i-x+1}
pi=pi−x+1,当然要和
m
x
−
i
+
1
mx-i+1
mx−i+1取
min
\min
min
如果 i ≥ m x i \geq mx i≥mx,不管
然后暴力扩展,更新 m x mx mx,没了
复杂度显然 O ( ∣ S ∣ + ∣ T ∣ ) O(|S|+|T|) O(∣S∣+∣T∣)
#include <iostream>
#include <cstdio>
#include <cstring>
#include <cctype>
#define MAXN 200005
using namespace std;
char s[MAXN],t[MAXN];
int p[MAXN];
int main()
{
scanf("%s%s",t+1,s+1);
int m=strlen(s+1);
strcat(s+1,"#");
strcat(s+1,t+1);
int n=strlen(s+1);
for (int i=2,x=0,mx=0;i<=n;i++)
{
p[i]=i<=mx? min(p[i-x+1],mx-i+1):0;
while (s[i+p[i]]==s[p[i]+1]) ++p[i];
if (i+p[i]-1>mx) x=i,mx=i+p[i]-1;
}
for (int i=1;i<=n;i++)
if (s[i]=='#') puts("");
else printf("%d ",i>1? p[i]:m);
return 0;
}
Lyndon Word
定义:一个串是Lyndon Word(以下简称LW),当且仅当它本身是自己字典序最小的后缀
下文字符串的比较均为字典序,+为字符串拼接
性质1 两个LW u , v u,v u,v,如果 u < v u<v u<v,那么 u + v u+v u+v是LW
对于 v v v的后缀,它比 v v v大,所以一定不是最小的;
对于 v v v,因为 u < v u<v u<v,所以 u + v < v u+v<v u+v<v
对于 ( u 的 后 缀 ) + v (u的后缀)+v (u的后缀)+v,因为 u < ( u 的 后 缀 ) u<(u的后缀) u<(u的后缀),所以 u + v < ( u 的 后 缀 ) + v u+v<(u的后缀)+v u+v<(u的后缀)+v
所以 u + v u+v u+v是最小的
所以LW可以递归定义:
- 单个字符是LW
- 多个字典序递增的LW顺次拼接后是LW
性质2 一个LW将最后一个字符变大后仍是LW
只有最后一个只包含一个字符的后缀变大,前面大小关系不变
性质3 任意字符串 S S S存在且仅存在一种分解方式 S = s 1 + s 2 + . . . + s n S=s_1+s_2+...+s_n S=s1+s2+...+sn,使得所有 s i s_i si均为LW且单调不增
证明是不可能的,这辈子都是不可能的
把性质3中的分解称为Lyndon分解
接下来要讲的就是线性求Lyndon分解的Duval算法
首先三个指针 i , j , k i,j,k i,j,k,表示 i i i以前的分解已经固定,现在处理第 k k k个字符, j j j一会儿说
即 [ 1 , i ) [1,i) [1,i)为 s 1 + s 2 + . . . + s n s_1+s_2+...+s_n s1+s2+...+sn,其中 s i s_i si为LW且单调不增
[ i , k ) [i,k) [i,k)为 t + t + . . . + t + t 1 t+t+...+t+t_1 t+t+...+t+t1,其中 t t t是LW, t 1 t_1 t1是 t t t的可空前缀
也就是一个LW不断循环,最后一个循环节可以不完整。注意这不一定是 [ i , k ) [i,k) [i,k)的Lyndon分解,因为 t 1 t_1 t1不一定是LW
别问为啥,问就是归纳法
现在把 S k S_k Sk加在后面,如果要继续循环,应该加的是 S k − 循 环 节 长 度 S_{k-循环节长度} Sk−循环节长度,我们把这个 k k k应该跟的位置记为 j j j
如果 S j = S k S_j=S_k Sj=Sk,说明循环正常,继续往后
如果 S j < S k S_j<S_k Sj<Sk,根据性质1,最后一个不完整的循环节 t 1 t_1 t1加上 S k S_k Sk是个LW并且比前面的 t t t都大,不断向前合并发现整段都是LW。所以将 [ i , k ] [i,k] [i,k]一长串合并成新的 t t t,即令 j = i j=i j=i
如果 S j > S k S_j>S_k Sj>Sk 不管 t 1 t_1 t1和 S k S_k Sk大小关系,反正后面怎么加怎么都会小于 t t t,所以没 t t t啥事了,把所有 t t t固定下来, t 1 t_1 t1作为新的循环节。然后 t 1 t_1 t1这个地方,我们之前以为它会进入循环,然而它没有,这里面漏了一些信息,所以需要从 t 1 t_1 t1的开头重新分解
#include <iostream>
#include <cstdio>
#include <cstring>
#include <cctype>
#define MAXN (1<<20)+5
using namespace std;
char s[MAXN];
int main()
{
scanf("%s",s+1);
int n=strlen(s+1);
for (int i=1;i<=n;)
{
int j=i,k=i+1;
while (s[j]<=s[k])
{
if (s[j]==s[k]) ++j;
else j=i;
++k;
}
while (i<=j)
{
printf("%d ",i+k-j-1);
i+=k-j;
}
}
return 0;
}
我 华 灯 宴 呢

















 9539
9539

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









