






 本文介绍了一种使用Scrapy爬取贴吧中关于Python问题的精品回答的方法,并将数据存入MongoDB。利用Pandas进行数据读取与处理,实现问与答的文字云展示。详细步骤包括数据库连接、数据读取、分词处理及词云生成。
本文介绍了一种使用Scrapy爬取贴吧中关于Python问题的精品回答的方法,并将数据存入MongoDB。利用Pandas进行数据读取与处理,实现问与答的文字云展示。详细步骤包括数据库连接、数据读取、分词处理及词云生成。
爬取了贴吧中python问题的精品回答,是使用scrapy写了一个程序,爬取了一点信息,存入MongoDB数据库中,代码就不上了,今天主要是通过pandas库读取数据,做问与答的文字云。
读取数据库
pandas库读取文件很方便,基本的文件都是能够用读取的,主要是运用dataframe(类似于excel表格),首先导入需要的模块;
import pandas as pdimport pymongoimport jieba.analyse
然后连接数据库,读取数据;
client = pymongo.MongoClient('localhost',port = 27017)test = client['test']tieba = test['tieba']data = pd.DataFrame(list(tieba.find()))data
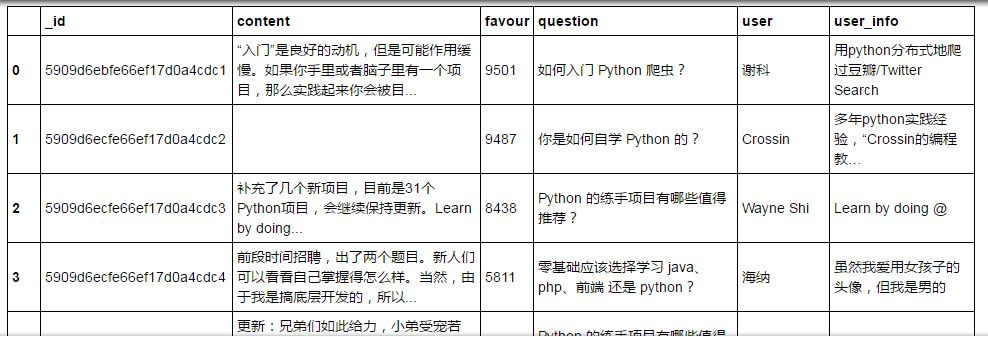
获取question列
我们知道分词需要的是字符串格式的数据,所以需要通过dataframe的切片提取question这列的数据,并转化为字符串格式。
question_data = '' #初始化字符串for i in range(563): #数字为数据的行数index = data.ix[i,:] #取每行question = index['question'] #取每行的questionquestion_data = question_data + questionprint(question_data)

分词
这部分以前讲过,贴上代码。
jieba.analyse.set_stop_words('停用词表路径')tags = jieba.analyse.extract_tags(question_data, topK=50, withWeight=True)for item in tags:print(item[0]+'\t'+str(int(item[1]*1000)))

词云
类似,也可以做出回答的词云。
问: 答:
答:

















 1510
1510

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









