



在 AI 中,视觉(图像)和语言(文本)往往是分开的:CV 模型能分类图像,但只能预测在训练集里的类别;NLP 模型能理解文本,但和图像没有直接联系。CLIP的目标是:让图像和文本嵌入到同一个语义空间,从而实现 “看到图像就能用语言描述,读到语言就能和图像对应”。
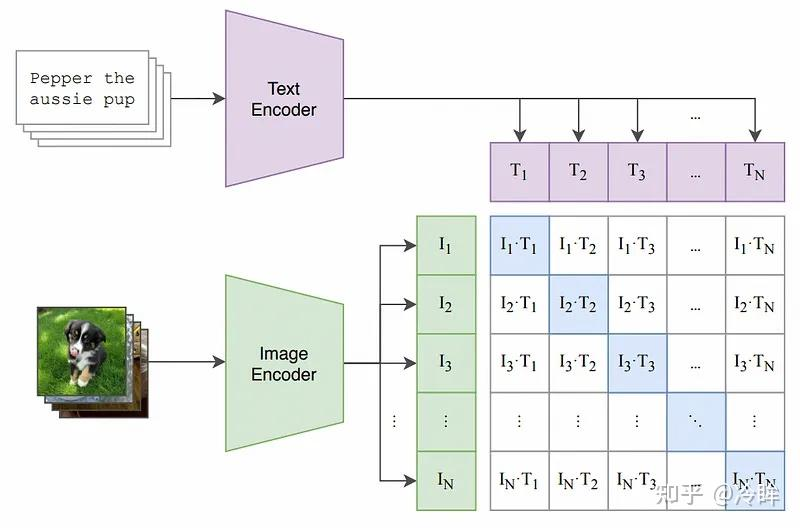
该模型的核心思想是使用大量图像和文本的配对数据进行预训练,以学习图像和文本之间的对齐关系。CLIP(Contrastive Language–Image Pretraining)模型有两个模态,一个是文本模态,一个是视觉模态,包括Text Encoder和Image Encoder。
图像编码器Image Encoder
Image Encoder有两种架构。
1. 改进的Resnet-D:ModifiedResNet
1. 替换输入层:把原来一个大的 7×7, stride=2 卷积改成三个串联的 3×3 卷积(有时前两个带 stride=2)。理由:相同感受野下参数更少、表达更深、计算效率更好。
2. 调整捷径分支布局:将捷径分支中 1×1, stride=2的卷积替换为先进行2×2, stride=2的平均池化,再 1×1 conv,以减少因 stride/1×1 conv 导致的信息丢失。
上面的两个改动都是Resnet-D相对Resnet的。
3. rect-2 blur pooling(抗锯齿rect-2模糊池化):当对图像特征做下采样(stride>1 的卷积或池化)时,如果不先去掉高频分量(比如锐利边缘),高频会“折叠”到低频,造成输出对小幅平移不稳定(shift-variance),模型对图像微小位移敏感。CLIP在下采样前先用一个小的低通滤波器(blur)对特征做平滑,然后再降采样,这样就能减少 aliasing,提高平移稳定性和鲁棒性。
4. 把全局平均池(GAP)换成“注意力池化(attention pooling)”: 用一层 transformer 风格的多头 QKV 注意力来做池化,查询(Q)不是一个固定的 learnable token,而是“基于图像的全局平均池化表示”来构造的(即 query 会依据这张图的全局 summary 生成)。其它的 key/value 则来自空间网格上的局部特征。

为什么要这么做呢?ViT在输入序列前额外加了一个可学习的特殊 token([CLS]),最后用 [CLS] 对应的 hidden state 作为整张图像的“全局表征”;而CLIP中,Q 是单个向量,代表全图的 summary,它去跟所有位置的 K 对比,得到注意力权重,最后加权求和 V。这样用整张图像的全局语义去指导如何聚合局部特征相比固定 [CLS],它更适合特征处理,更语义相关。
2. 改进的ViT
CLIP的ViT只做了小的工程化修改:
1. 在 patch+pos 之后 额外加了一层 LayerNorm,作为输入正则化。它可以在大规模对比学习里,保证图像编码的数值范围稳定,减少与文本编码器的分布偏差。
2. 调整了初始化方案,让图像编码器的输出尺度与文本编码器对齐。
3. 输出处理:
ViT:取 [CLS] token → 接分类头(MLP head)
CLIP:取 [CLS] token → LayerNorm → 线性投影到对比空间(如 512 维) → L2 归一化,使输出与文本 encoder 在同一嵌入空间
文本编码器Text Encoder
文本编码器也是在基于Transformer的架构上做了一些改变:
1. CLIP的输入是 小写字节对编码 (BPE) token;用 [SOS] 和 [EOS] 包裹序列,表示句子的开始和结束,最终只取 [EOS] 作为句子特征。
2. CLIP的架构是 GPT 式的 decoder-only transformer,它的注意力是掩码注意力,q、k、v 均来自当前序列本身(即输入的 [SOS] ... tokens ... [EOS]);Mask保证第 i 个 token 只能看到 ≤ i 的位置。
3. CLIP不做预测,它把句子编码成一个向量,再通过线性投影到多模态共享空间,用对比学习目标训练。
———————————————————————————————————————————
双向注意力(BERT、Encoder)和掩码注意力(GPT、Decoder-only)的区别在于:
1. 双向注意力是 非因果 (non-causal) 的,可以整体理解整个句子;它适合做 理解类任务:分类、句子匹配、填空 (Masked LM)。
2. 掩码注意力是 单向 (unidirectional) 的,只能利用过去上下文;它适合做 生成类任务:语言建模、文本续写、翻译中的目标端预测。
———————————————————————————————————————————
模型训练思路
1. 构建相似度矩阵:将图像编码器输出与文本编码器输出
做L2归一化,这样两向量的内积等于 余弦相似度:
然后把所有图像向量和文本向量做矩阵乘法:
表示图像
与文本
的相似度。
在 CLIP 中常在相似度上乘以一个 可学习的标量(称为 logit scale,写成 ,实际用
去缩放),得到 logits:
这个缩放控制 softmax 的“温度”(越大会使 softmax 更陡峭、概率更集中)。
2. 交叉熵损失
取第1行(图像文本)表示:第 1 张图片与 batch 中所有 N 条文本的相似程度。这一行的 logits 通过 softmax 转成概率分布,模型把概率集中到正确的文本。同理,CLIP 的训练既做 image→text 的交叉熵,也做 text→image 的交叉熵(双向),二者的平均作为最终损失。
模型预测过程(zero-shot分类)
1. 把每个类别转换成一句自然语言描述,并通过文本编码器转成向量;同样,把待分类图像转成向量。
2. 计算余弦相似度,取相似度最高(或概率最大的)类别作为预测结果。

















 3151
3151

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









