







valse 2019
简单记录一下valse2019的一些内容
写在前面
今年的valse志愿者们都很辛苦,刚到出站口就有志愿者指路,每隔几十米就有一个志愿者,一步步带你到大巴的位置~超级贴心
所有Workshop分为两个部分,首先每个老师轮流进行30分钟的报告以及五分钟的提问,最后30分钟Panel环节老师们坐在一起回答问题
我只记录了其中我感兴趣的和来得及记录的一些内容
弱监督视觉理解简介
弱监督是相对于强监督的,开头简介的时候他们将弱监督学习分为了三类
- 不完备监督,标签不完备
- 不准确监督,标签不准确
- 不确切监督,标签不确切(精确)
另外,有一位老师简单阐述了弱监督的含义,大致是说,弱监督给出的标签会在某种程度上弱于我们面临的任务所要求的输出。

面向开放环境的自适应视觉感知
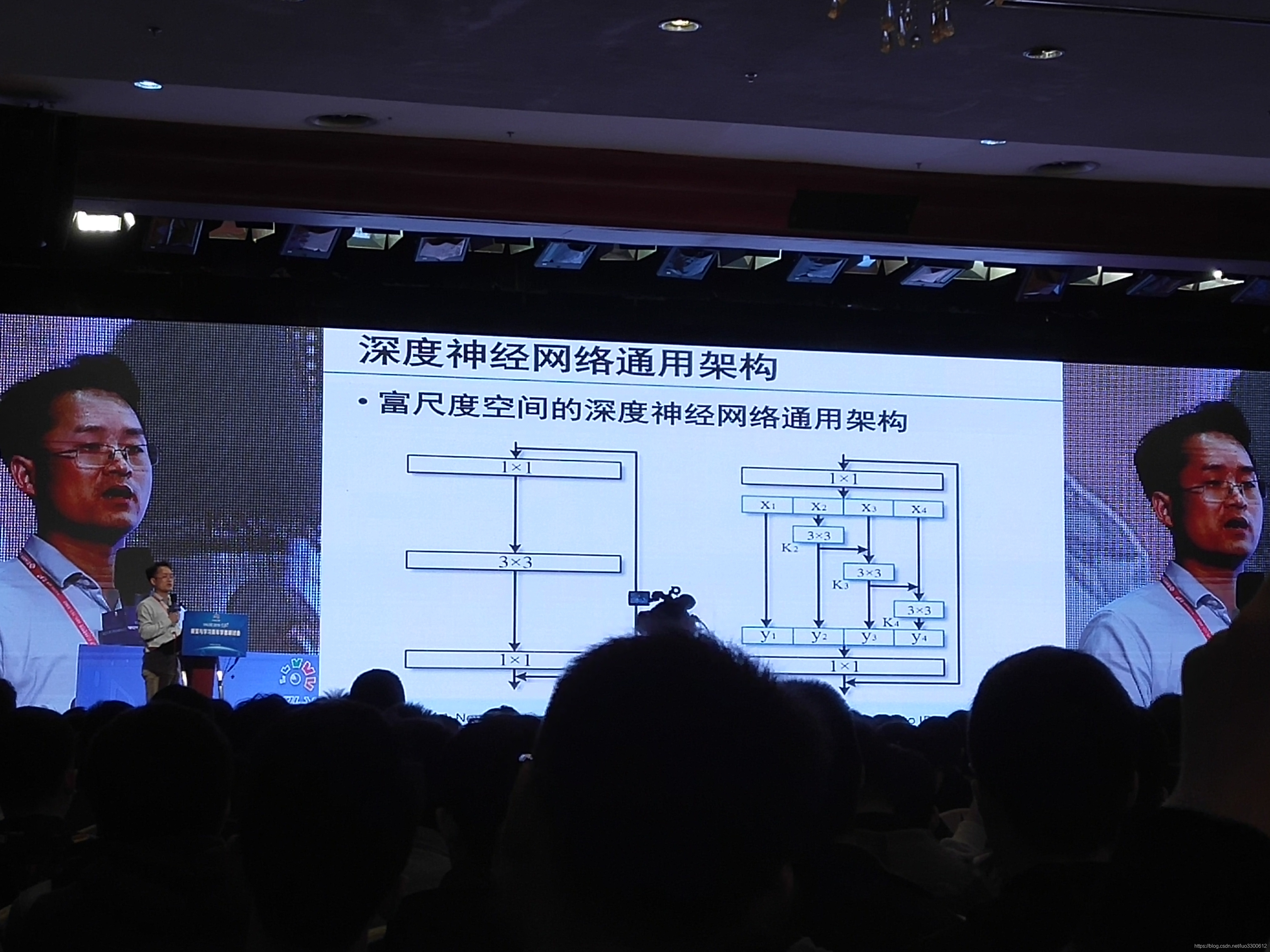
程明明教授提出,当前各种深度网络的进步(Alex-Net LeNet ResNet)得益于网络多尺度信息综合能力的提升,基于这个motivition,他们团队提出了一个富尺度空间的深度神经网络通用架构,在每一个backbone上,对图像进行深度层上的分割,然后通过不同尺度的处理再结合到输出
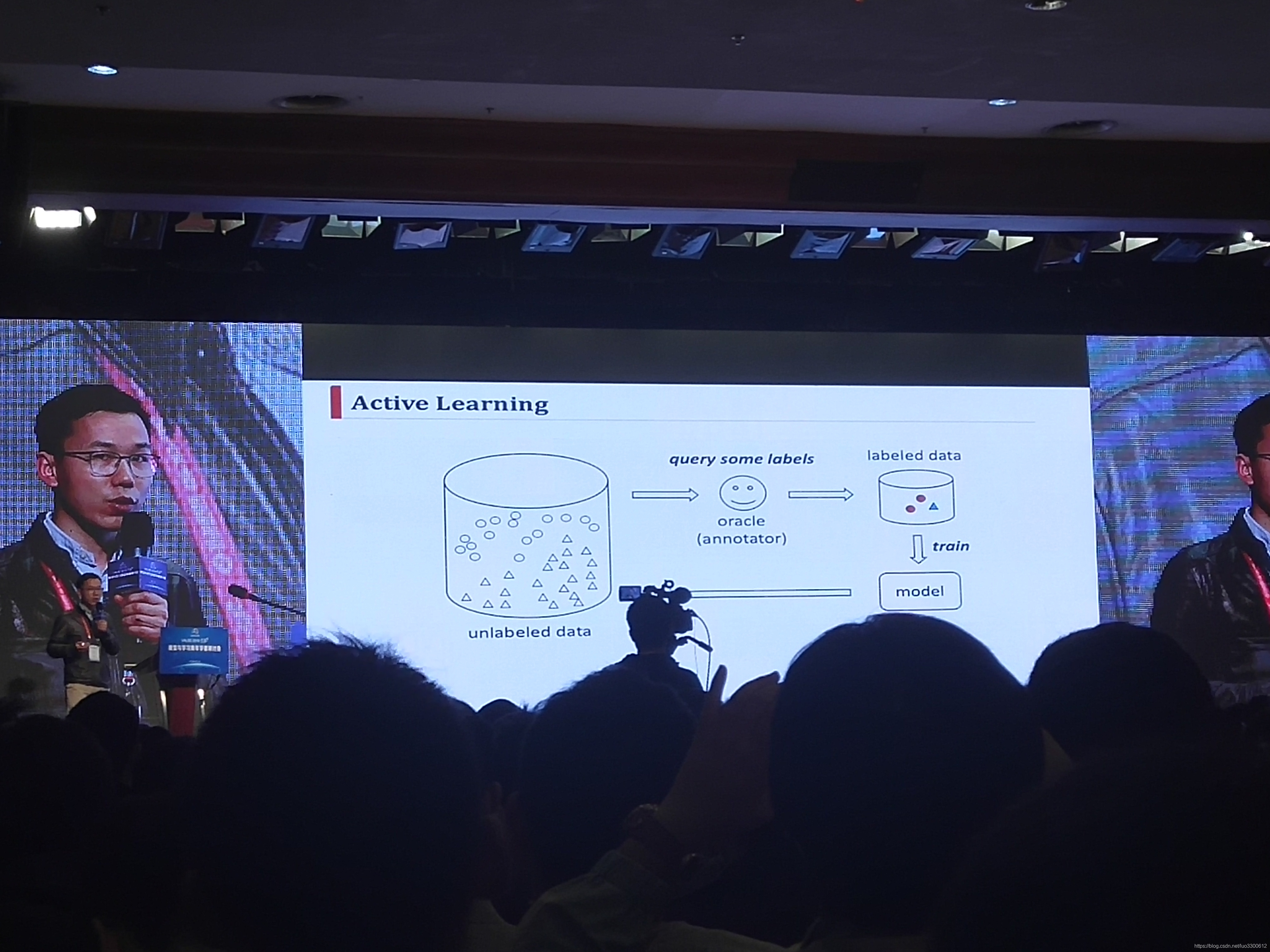
Cost-Sensitive Active Learning
南航的黄圣军老师的报告是围绕Active Learning(主动学习) ,关于主动学习,大致的意思是,我们有一堆没有标签的数据,和一个oracle,通过询问oracle,我们可以得知数据的标签进而进行模型的训练,然而这个询问oracle的过程被视作是需要一定代价的,主动学习的目标是:用尽可能少的标注代价得到更好的模型
黄老师给出了标注代价的定义,并说明标注代价并不等于标注的数据量的多少,因为不同数据的标注代价可能不同,比如标注一个蛋白质的功能的代价可能因为需要专业人才而很高。
接着黄老师就label的标注代价和缺失feature的标注代价两个方面进行了讨论,通过在主动学习中设置一些query的机制,来实现标注代价的最小化的同时模型效果的最大化
各种天秀打标签方法
- 只给目标物体上画一条线
- 只在目标物体上打一个点
- 仅仅告诉模型一系列图片中包含什么而不给位置,让模型自己学习找到这些目标

pre-trained model
有一位老师报告了他们进行弱监督学习的主要方法,就是使用各种pre-trained model,利用模型强大的特征提取能力,进行弱监督的目标检测。
其中比较有趣的一个就是,他们尝试直接使用pre-trained model,找原图使得pre-trained model最后一个卷积层激活较大的区域,然后发现在Image-Net上pre-trained的模型虽然有很好的分类能力,但是他们最后的激活往往来自于原图中最discriminative的部分而不是全部物体,举个例子,虽然pre-trained model能将狗分类成狗,但是使得最后输出“狗”这个维度的激活最大的可能仅仅是狗头、狗腿这些比较discriminative的区域,而不是整个狗的instance segmentation,于是他们提出,将原图中最disciminative的区域擦掉(erase),然后再训练模型,如此反复,直到模型最后的激活来源于整个狗,但这样会出现over erasing的情况,过犹不及,使得模型将输出归因到背景上,所以他们还采用了更精细的方法来处理这个问题,具体我也没有记录了。

refer and query
为了让模型识别某个物体,比方说猫,给模型两张猫的图片,一张图片给出猫的位置(referring),然后询问(query)另一张图片中猫的位置
idea
一些idea的概括
- 卷积激励的显著分布估计,与前文所说的pre-trained model一样,对原图使得最后激活大的区域进行分析
- 通过对抗生成网络生成边界周围的样本来得到更细粒度的分类边界
- 为了衡量图像和文本的相似度,将图像编码到文本的特征空间中,或者将文本编码到图像的特征空间中,以此衡量,而不是将二者编码到第三个特征空间中衡量
- 设计好的loss是发表论文的好方法
一些术语
- co-localization,共定位
- 凸正则化,用来对非凸函数寻找更优的极小值点的方法
- incremental learning,增量学习
- 细粒度,fine-grained,指的是对图像更细致的信息的研究,比如狗的品种的分类,难点是类间差异大,类内差异小
- 孪生网络
- 度量学习
- dense net
- shuffle net(v2)
一些研究的热点
- derain
- super resolution
- image attr edition
- 各种segmentation
- image caption
- 3d reconstruction
- zero shot learning
- 多模态
- cross model
- tracking
- 人脸检测
- re-identification
- Auto ML (NAS)

















 539
539

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









