



他的生活状态无疑是许多人梦寐以求的。拥有两套无贷款的房产,家庭和睦,两台车价值约50万元。现金资产高达1800万元,家庭年收入约150万元,职业稳定,属于中层管理阶层。

重要的是,孩子们的成绩优异,985高校的录取通知书对他们来说只是保底选择。
这是这两天某论坛上一个网友的故事。
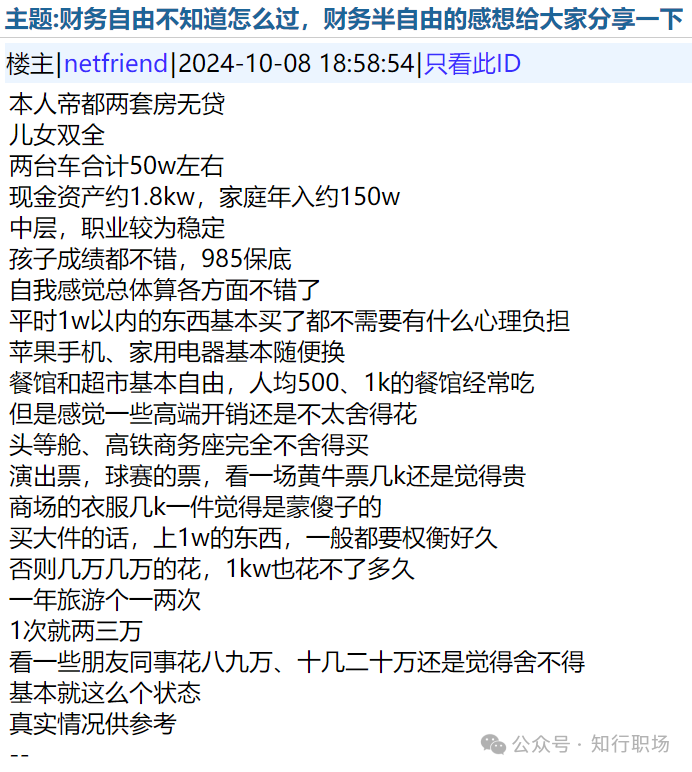
尽管已经达到他的生活似乎已经达到了许多人梦寐以求的财务半自由状态,但他发现自己在面对一些高端消费时仍然会感到犹豫。他可以轻松购买价值1万元以内的物品,无需承受任何心理负担。苹果手机、家用电器对他来说,更换起来轻而易举。在餐馆和超市,他可以随心所欲地消费,即使是人均500元、1000元的餐厅,他也能经常光顾。
然而,对于头等舱机票、高铁商务座,他却始终舍不得购买。面对演出票、球赛票,即使是黄牛票,他也觉得价格不菲。商场里几千元一件的衣服,在他看来就像是在欺骗消费者。每当他考虑购买价值超过1万元的大件物品时,他总是需要权衡很久,因为他知道,如果这样挥霍无度,即使是1000万元的资产,也经不起多久的消耗。
每年,他都会安排一两次旅行,每次花费两三万元。他看着周围的朋友和同事花费八九万、甚至十几二十万元去旅行,心中不禁感到不舍。他的生活状态,虽然在物质上已经相对自由,但在精神上,他仍然在寻找着某种平衡。
其实吧,他就是想太多。钱是有了,可心里还是不踏实。这就像吃东西一样,你吃第一口的时候特别香,可你一直吃,吃到撑了,也就没啥感觉了。而且,总想得到更多。看到别人过的比自己好,难免会有点攀比心理。
人啊,总是这样,当你拥有了更多,反而会更担心失去。他就像站在山顶上的人,虽然风景很美,但总担心会摔下去。
当然,不同的阶段有不同的困惑,如果你现在:
职业规划迷茫?
简历屡被拒?
面试频频挂?
想转行却不知从何下手?
副业想做却无从开启?
个人IP打造不得要领?
如果你也遇到以上问题,可以参考《Raymond使用指南》,找到属于你的职业新方向!


















 1897
1897

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









