



 Meta发布的新AI模型ImageBind能处理视觉、温度、文本、音频、深度和运动等六种模态信息,无需针对每种组合单独训练。它通过统一的联合嵌入空间理解和转换模态间的关系,展示了在多感官数据处理上的潜力。尽管目前仍处于研究阶段,但ImageBind预示着更沉浸式虚拟世界和多模态AI应用的可能性,如在虚拟现实、通用机器人领域的未来应用。
Meta发布的新AI模型ImageBind能处理视觉、温度、文本、音频、深度和运动等六种模态信息,无需针对每种组合单独训练。它通过统一的联合嵌入空间理解和转换模态间的关系,展示了在多感官数据处理上的潜力。尽管目前仍处于研究阶段,但ImageBind预示着更沉浸式虚拟世界和多模态AI应用的可能性,如在虚拟现实、通用机器人领域的未来应用。
Meta在当地时间5月9日宣布,他们开源了一种新的AI模型ImageBind,该模型可以跨越6种不同的模态,包括视觉、温度、文本、音频、深度信息和运动读数。
ImageBind是一种突破性的多模态AI模型,与以往只支持一个或两个模态的模型不同,ImageBind能够理解和转换6种不同模态之间的关系。
Meta展示了一些案例,如听到狗叫画出一只狗,同时给出对应的深度图和文字描述;如输入鸟的图像+海浪的声音,得到鸟在海边的图像。
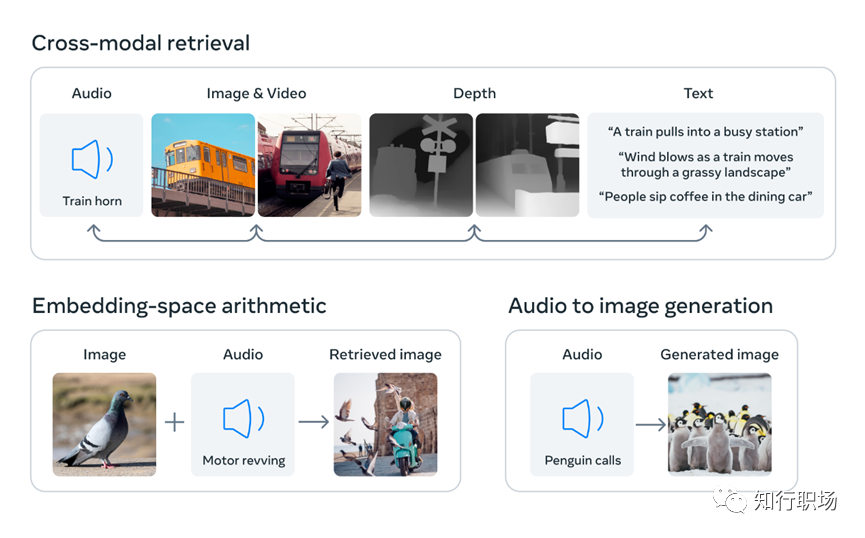
ImageBind的核心方法是将所有模态的数据放入统一的联合嵌入空间,而不需要使用每种不同模态组合对数据进行训练。利用最近的大型视觉语言模型,ImageBind将零样本能力扩展到新的模态,例如视频-音频和图像-深度数据。通过这种方式,ImageBind可以处理6种不同的感官数据。
虽然目前ImageBind还只是研究项目,没有直接的消费者用户或实际应用,但Meta表示该模型为设计和体验身临其境的虚拟世界打开了大门。未来,Meta还计划加入触觉、语音、嗅觉和大脑功能磁共振信号,进一步探索多模态大模型的可能性。
随着ImageBind模型逐步完善,AI应用场景将进一步拓展,比如当ImageBind融入虚拟现实设备,使用者能获得更沉浸式的体验。国盛证券分析师刘高畅预测,随着多模态的发展带来AI泛化能力提升,通用视觉、通用机械臂、通用物流搬运机器人、行业服务机器人、真正的智能家居等领域也将进入生活。在未来5-10年内,结合复杂多模态方案的大模型有望具备完备的与世界交互的能力,在通用机器人、虚拟现实等领域得到应用。
AI开放交流群



















 63
63

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









