




 本文介绍了如何在PlantUML中自定义连接线的风格。通过设置不同的参数,可以将默认的曲线连接线调整为直线或者虚线,从而在绘制图表时提供更多的视觉效果选择。
本文介绍了如何在PlantUML中自定义连接线的风格。通过设置不同的参数,可以将默认的曲线连接线调整为直线或者虚线,从而在绘制图表时提供更多的视觉效果选择。
原文地址:https://www.lujun9972.win/blog/2020/04/22/plantuml-tips之设置连接线风格/index.html
花图时,PlantUML默认使用曲线连接元素,不过我们可以通过 skinparam 的 linetype 参数对连接线的风格进行修改。
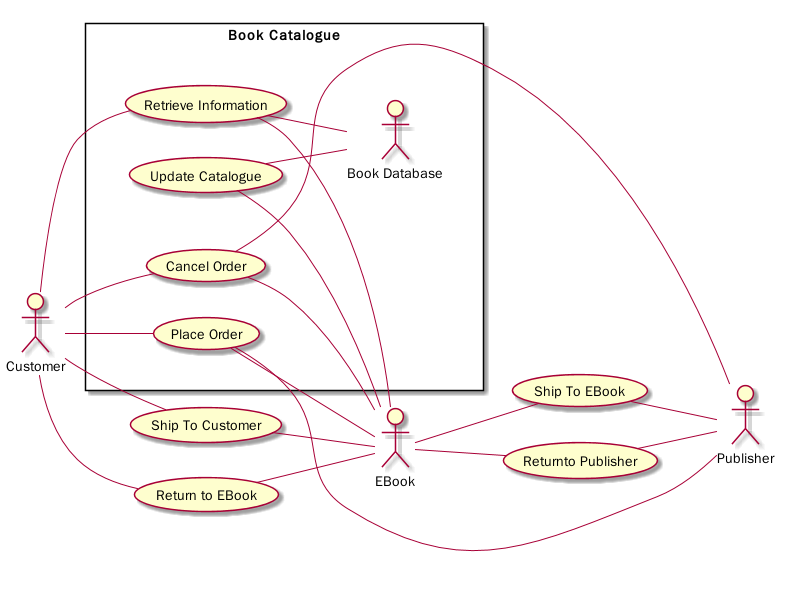
例如下面是默认的连接风格:
@startUML EBook Use Case Diagram
left to right direction
Actor Customer as customer
Actor EBook as ebook
Actor Publisher as publisher
rectangle "Book Catalogue" {
together {
Actor "Book Database" as bookLog
(Retrieve Information) as getBook
customer -- getBook
getBook -- ebook
getBook -- bookLog
(Update Catalogue) as updateCatalogue
ebook -- updateCatalogue
updateCatalogue -- bookLog
}
together {
(Place Order) as order
customer -- order
order -- ebook
order--publisher
(Cancel Order) as cancelOrder
customer -- cancelOrder
cancelOrder -- ebook
cancelOrder--publisher
}
}
(Ship To EBook) as shipEBook
shipEBook -- publisher
(Ship To Customer) as shipCustomer
customer -- shipCustomer
ebook -- shipEBook
shipCustomer -- ebook
(Return to EBook) as returnCustomer
(Returnto Publisher) as returnPublisher
customer -- returnCustomer
returnCustomer -- ebook
ebook -- returnPublisher
returnPublisher -- publisher
@endUML
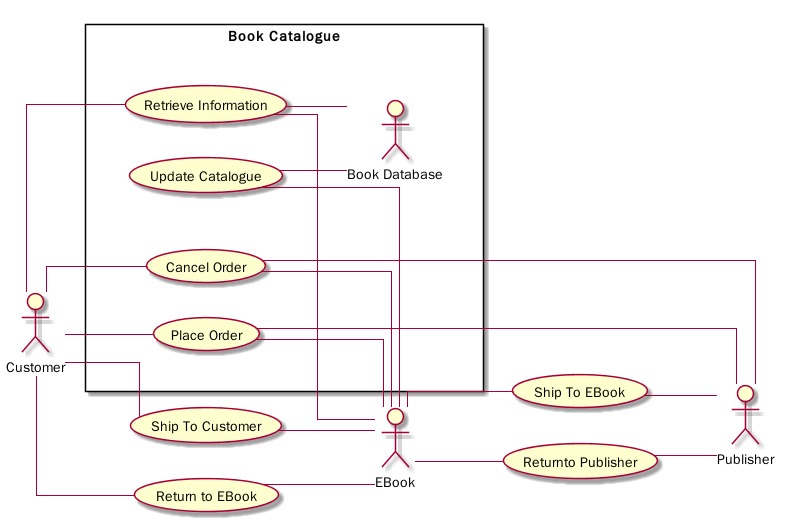
下面是设置了 skinparam linetype ortho 的样子
@startUML EBook Use Case Diagram
skinparam linetype ortho
left to right direction
Actor Customer as customer
Actor EBook as ebook
Actor Publisher as publisher
rectangle "Book Catalogue" {
together {
Actor "Book Database" as bookLog
(Retrieve Information) as getBook
customer -- getBook
getBook -- ebook
getBook -- bookLog
(Update Catalogue) as updateCatalogue
ebook -- updateCatalogue
updateCatalogue -- bookLog
}
together {
(Place Order) as order
customer -- order
order -- ebook
order--publisher
(Cancel Order) as cancelOrder
customer -- cancelOrder
cancelOrder -- ebook
cancelOrder--publisher
}
}
(Ship To EBook) as shipEBook
shipEBook -- publisher
(Ship To Customer) as shipCustomer
customer -- shipCustomer
ebook -- shipEBook
shipCustomer -- ebook
(Return to EBook) as returnCustomer
(Returnto Publisher) as returnPublisher
customer -- returnCustomer
returnCustomer -- ebook
ebook -- returnPublisher
returnPublisher -- publisher
@endUML
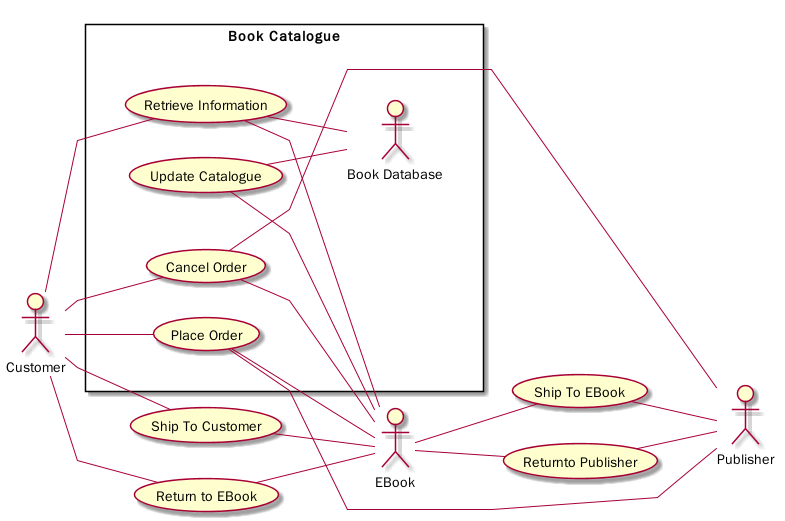
下面是设置了 skinparam linetype polyline 的样子
@startUML EBook Use Case Diagram
skinparam linetype polyline
left to right direction
Actor Customer as customer
Actor EBook as ebook
Actor Publisher as publisher
rectangle "Book Catalogue" {
together {
Actor "Book Database" as bookLog
(Retrieve Information) as getBook
customer -- getBook
getBook -- ebook
getBook -- bookLog
(Update Catalogue) as updateCatalogue
ebook -- updateCatalogue
updateCatalogue -- bookLog
}
together {
(Place Order) as order
customer -- order
order -- ebook
order--publisher
(Cancel Order) as cancelOrder
customer -- cancelOrder
cancelOrder -- ebook
cancelOrder--publisher
}
}
(Ship To EBook) as shipEBook
shipEBook -- publisher
(Ship To Customer) as shipCustomer
customer -- shipCustomer
ebook -- shipEBook
shipCustomer -- ebook
(Return to EBook) as returnCustomer
(Returnto Publisher) as returnPublisher
customer -- returnCustomer
returnCustomer -- ebook
ebook -- returnPublisher
returnPublisher -- publisher
@endUML

















 26万+
26万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









