




 本文介绍了一个使用Python和Selenium从指定网站爬取小说内容的案例。案例详细展示了如何定位小说章节URL、抓取章节标题与正文,并将其保存到本地文件的过程。此外,还提供了在CentOS 7上安装Chrome浏览器及Chromedriver的方法。
本文介绍了一个使用Python和Selenium从指定网站爬取小说内容的案例。案例详细展示了如何定位小说章节URL、抓取章节标题与正文,并将其保存到本地文件的过程。此外,还提供了在CentOS 7上安装Chrome浏览器及Chromedriver的方法。
python3免费下载小说案例
说明:本案例使用selenium爬取“www.50331.net”网站小说,小说内容定位通过xpath。利用centos7安装google浏览器,通过selenium调用无痕界面模式抓取
一、代码内容
from selenium import webdriver
import time
import re
class Biquge(object):
def __init__(self,url,book_menu_url_xpath,book_name_xpath,body_xpath,title_xpath):
self.url = url
# self.driver = webdriver.PhantomJS(executable_path='/usr/local/bin/phantomjs')
self.options = webdriver.ChromeOptions() # 创建一个配置对象
self.options.add_argument("--headless") # 开启无界面模式
self.options.add_argument('--no-sandbox')
self.options.add_argument("--disable-gpu")
self.options.add_argument('--disable-dev-shm-usage') # linux上需要设置上面四项内容。
# self.options.add_argument('--proxy-server=http://190.97.226.49:8888') # 利用IP代理模式
self.options.add_argument('--user-agent=Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10.5; en-US; rv:1.9.1) Gecko/20090624 Firefox/3.5') # 修改user-agent
# self.driver = webdriver.Chrome(executable_path='/home/worker/Desktop/driver/chromedriver')
self.driver = webdriver.Chrome(chrome_options=self.options,executable_path='/usr/bin/chromedriver') # centos7系统的配置方式
# self.driver = webdriver.Chrome(chrome_options=self.options,executable_path='C:\chromedriver.exe') # windows系统的配置方式
self.book_menu_url_xpath = book_menu_url_xpath
self.book_name_xpath = book_name_xpath
self.book_body_xpath = body_xpath
self.book_title_xpath = title_xpath
def __book_name__(self):
‘’‘
获取小说名字
’‘’
try:
self.driver.implicitly_wait(10)
self.driver.get(self.url)
book_name = self.driver.find_element_by_xpath(self.book_name_xpath).text
# book_name = self.driver.find_element_by_xpath("书名的xpath").text
except Exception as f:
print(f)
print("书名获取失败")
#print(book_name)
return book_name
def book_url_path(self):
# 获取小说章节的url
book_url_list = []
try:
self.driver.implicitly_wait(10)
self.driver.get(self.url)
book_menu_url_path = self.driver.find_elements_by_xpath(self.book_menu_url_xpath)
# book_menu_url_path = self.driver.find_elements_by_xpath("获取书章节的定位xpath")
for book_menu_list in book_menu_url_path:
menu_url = book_menu_list.find_element_by_xpath('./a').get_attribute('href')
book_meun_text = book_menu_list.text
if book_meun_text.find("第") != -1:
if book_meun_text.find("章") != -1:
book_url_list.append(menu_url)
print(book_meun_text,": ",menu_url)
except Exception as e:
print(e)
print("获取小说章节路径失败")
# print(book_url_list)
return book_url_list
def __dingwei_zong__(self,book_menu_url):
try:
self.driver.implicitly_wait(10) # 最多等待10秒
self.driver.get(book_menu_url)
except Exception as f :
print(f)
print("定位出现错误")
self.driver.get(book_menu_url)
def dingwei_bady(self):
# 定位章节正文
try:
ele = self.driver.find_element_by_xpath(self.book_body_xpath).text
except Exception as f :
print(f)
print("获取章节正文出现错误")
ele = False
return ele
def dingwei_title(self):
# 定位章节标题
try:
ele_litle = self.driver.find_element_by_xpath(self.book_title_xpath).text
except Exception as f :
print(f)
print("获取章节标题出现错误")
ele_litle = False
return ele_litle
def save_data(self,data_body,data_title,bookname):
body = data_body.split('小说这里都有哦!')[1].split('本书最新章节内容未完')[0] # 保存章节正文
litle = data_title # 保存章节标题
with open('/data/feilutest/pacong_new1/selenium_data/book/'+ bookname+'.txt','a+') as f:
f.write(litle)
f.write('\n\n')
f.write(body)
f.write('\n')
#print(litle+'\n')
#print(body)
def read_run(self):
bookname = self.__book_name__()
for book_url_menu in self.book_url_path():
self.__dingwei_zong__(book_url_menu)
respons_body = self.dingwei_bady() # 获取正文
if respons_body == False:
respons_body = self.dingwei_bady()
time.sleep(2)
respons_title = self.dingwei_title() # 获取章节标题
if respons_title == False:
respons_title = self.dingwei_title()
time.sleep(2)
self.save_data(respons_body,respons_title,bookname)
self.driver.quit()
print("已写入完成")
# self.driver.close() # 关闭网页
if __name__ == '__main__':
url_book = 'https://www.50331.net/book/1/'
# url_book = 'https://www.50331.net/book/84196692/'
book_menu_url_xpath = '/html/body/div[5]/dl/dd[624]/following-sibling::*'
book_name_xpath = '/html/body/div[4]/div[2]/h2'
body_xpath = '//*[@id="content"]'
title_xpath = '//*[@id="wrapper"]/div[4]/div[2]/h1'
read_data = Biquge(url_book,book_menu_url_xpath,book_name_xpath,body_xpath,title_xpath)
read_data.read_run()
二、linux安装chrome浏览器
1. 配置yum源
在目录 /etc/yum.repos.d/ 下新建文件 google-chrome.repo
vim /ect/yum.repos.d/google-chrome.repo
写入如下内容:
[google-chrome]
name=google-chrome
baseurl=http://dl.google.com/linux/chrome/rpm/stable/$basearch
enabled=1
gpgcheck=1
gpgkey=https://dl-ssl.google.com/linux/linux_signing_key.pub
保存退出
按 ESC 退出编辑模式(回到命令模式)
输入 :wq! 保存并退出
2.安装google chrome浏览器
Google官方源安装:
yum -y install google-chrome-stable
Google官方源可能在中国无法使用,导致安装失败或者在国内无法更新,可以添加以下参数来安装:
yum -y install google-chrome-stable --nogpgcheck
3.检查是否安装成功
google-chrome --version # 输入此条命令,查看安装的版本
Google Chrome 88.0.4324.182
三、安装chromedriver
1、下载地址
http://npm.taobao.org/mirrors/chromedriver/
2、windows安装
查看windows上的chrome浏览器的版本
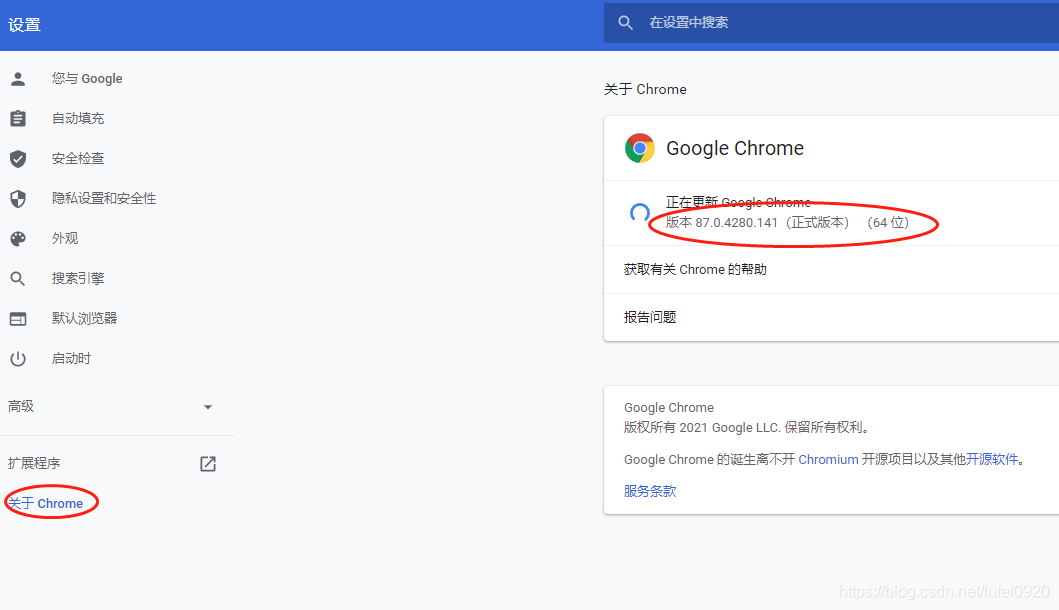
在网站中找到相应的下载版本

下载后放置在备及的某个目录中
3、linux下载安装chromedirver
上文已查看chrome的版本,需要在下载网站查看指定版本的chromedirver即可,然后放置在服务器的/use/bin下即可

添加执行权限:
chmod + x /usr/bin/chromedriver



















 855
855

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











