



 本文详细介绍了Spark SQL的基础用法,包括SQLContext、HiveContext、SparkSession的使用,以及如何通过spark-shell、spark-sql和thriftserver/beeline进行交互。内容涵盖了数据源的读取、Spark程序的打包部署以及各种工具的执行示例。
本文详细介绍了Spark SQL的基础用法,包括SQLContext、HiveContext、SparkSession的使用,以及如何通过spark-shell、spark-sql和thriftserver/beeline进行交互。内容涵盖了数据源的读取、Spark程序的打包部署以及各种工具的执行示例。
概述:本文主要介绍SQLContext、HiveContext、SparkSession、spark-sql、spark-shell及thriftserver/beeline的简单使用。
1、SQLContext的使用
使用SqlContext可以从多种数据源中创建DataFrame,包括json、parquet、csv(2.x)、hive、jdbc等,使用参考图示:
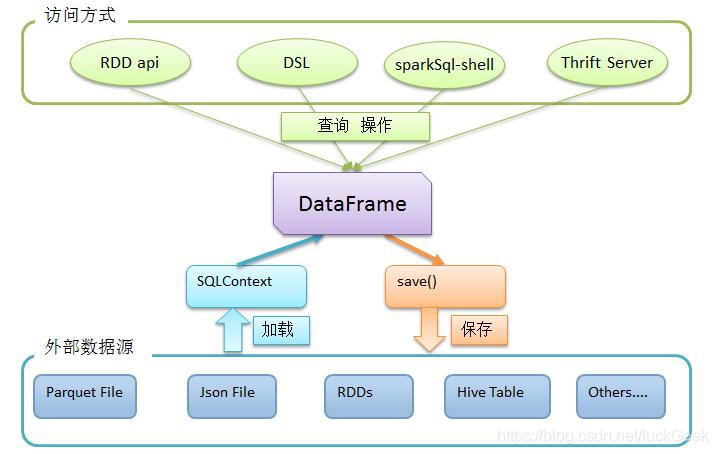
(1)加载依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>2.4.2</version>
</dependency>(2)编程
SparkConf->SparkContext->读取数据->关闭资源
def main(args: Array[String]): Unit = {
val path=args(0)
//1、创建Context
val sparkConf=new SparkConf();
sparkConf.setAppName("SQLContextApp").setMaster("local[2]")//设置本地模式,部署时要注释掉
val sc=new SparkContext(sparkConf)
val SQLContext=new SQLContext(sc)
//2、业务相关处理
val people=SQLContext.read.format("json").load(path);//处理json格式的数据
people.printSchema()
people.show()
//3、关闭资源
sc.stop()
}本地json数据如下:
vi app/spark-2.4.2-bin-hadoop2.6/examples/src/main/resources/people.json
{"name":"Michael"}
{"name":"Andy", "age":30}
{"name":"Justin", "age":19}Windows下使用IDEA以local模式运行spark程序报错:
ERROR Shell: Failed to locate the winutils binary in the hadoop binary path
java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries.(1)下载并解压https://github.com/srccodes/hadoop-common-2.2.0-bin
(2)配置环境变量
HADOOP_HOME
C:\Program Files\SoftWare\hadoop2.62、HiveContext的使用
(1)引入jar
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-hive -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.12</artifactId>
<version>2.4.2</version>
<scope>provided</scope>
</dependency>
(2)编程
SparkConf->SparkContext->HiveContext->读取表数据->关闭资源
def main(args: Array[String]): Unit = {
val sparkConf=new SparkConf()
//创建HiveContext
val sc=new SparkContext(sparkConf);
val hc=new HiveContext(sc);
//读取表数据
hc.table("emp").show
//关闭资源
sc.stop()
}3、SparkSession的使用
(1)编程
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().appName("SparkSessionApp").master("local[2]").getOrCreate();
val people = spark.read.json("file:///F:/people.json")
people.show()
spark.stop()
}4、Spark程序打包部署
mvn clean package -DskipTests
#上传服务器
scp sql-1.0-SNAPSHOT.jar root@hadoop:~/lib
#使用脚本运行jar包
vi ~/app/spark-2.4.2-bin-hadoop2.6/sqlContext.sh
#可以先在spark路径下直接执行
cd ~/app/spark-2.4.2-bin-hadoop2.6/
#测试通过后写入脚本
./bin/spark-submit \
--name SQLContextApp \
--class com.inspur.spark.SQLContextApp \
--master local[2] \
/root/lib/sql-1.0-SNAPSHOT.jar \
/root/app/spark-2.4.2-bin-hadoop2.6/examples/src/main/resources/people.json
#为sqlContext.sh添加执行权限
chmod u+x ~/app/spark-2.4.2-bin-hadoop2.6/sqlContext.sh5、spark-shell/spark-sql和thriftserver/beeline的使用
(1)spark-shell的使用
#启动 设置运行模式、加载mysql驱动
./app/spark-2.4.2-bin-hadoop2.6/bin/spark-shell --master local[2] --jars /root/software/mysql-connector-java-5.1.47-bin.jar
#查看数据库表
spark.sql("show tables").show
#关联查询
spark.sql("select * from emp e join dept d on e.deptno=d.deptno").showspark-shell在服务器上的执行结果如图:
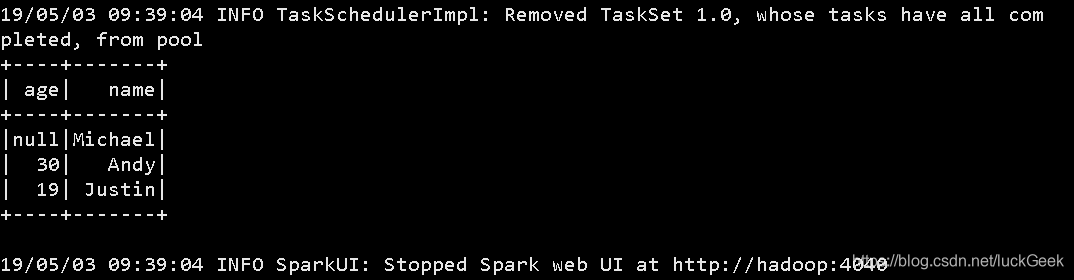
(2)spark-sql的使用
#以spark-sql方式执行 该方式下可以使用HQL命令操作数据库
./app/spark-2.4.2-bin-hadoop2.6/bin/spark-sql --master local[2] --jars /root/software/mysql-connector-java-5.1.47-bin.jar
#创建表
create table t(key string,value string);
#查看执行计划
explain select a.key*(3+9),b.value from t a join t b on a.key=b.key and a.key>5;
explain extended select a.key*(3+9),b.value from t a join t b on a.key=b.key and a.key>5;Spark架构:
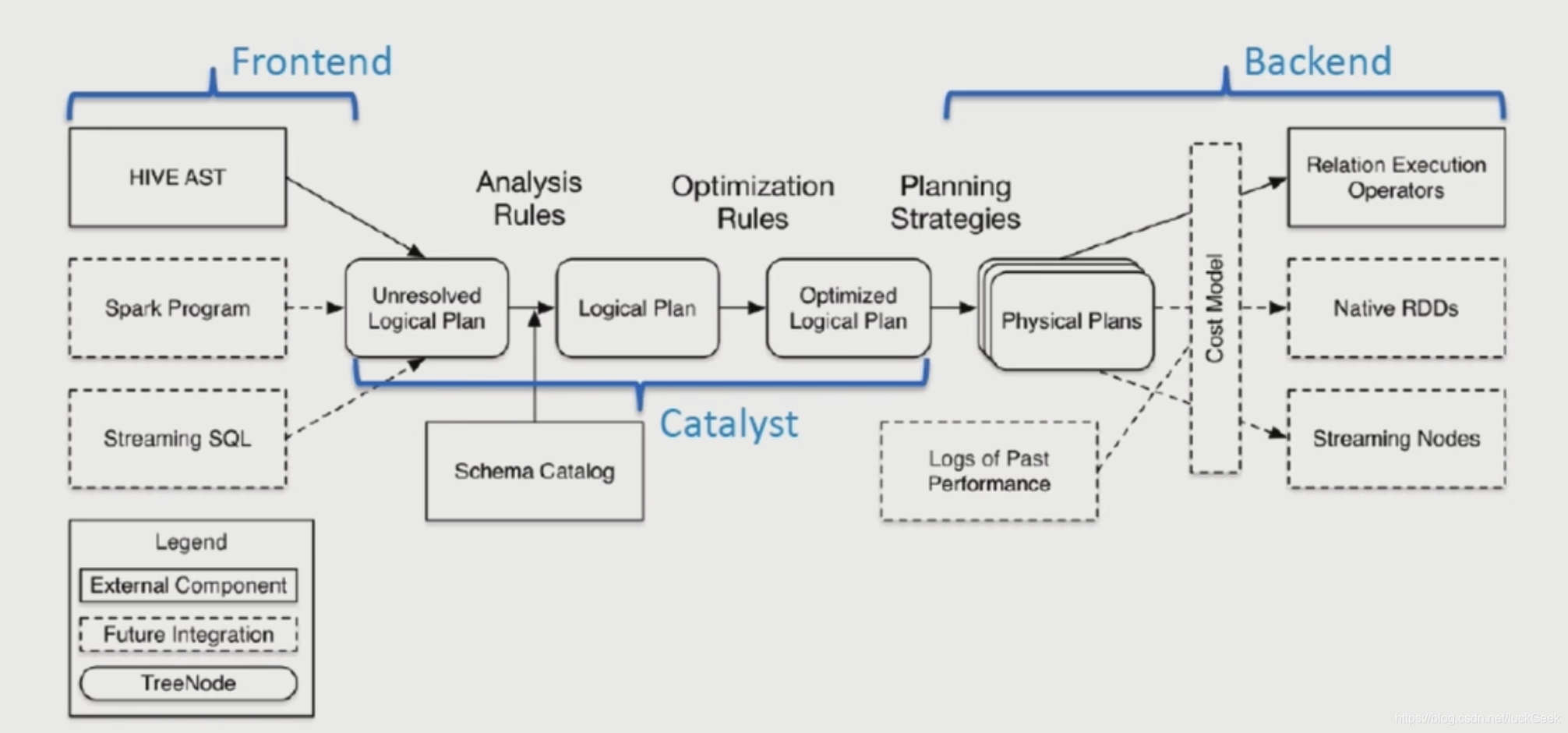
(3) thriftserver/beeline
#启动thriftserver 修改默认端口
./sbin/start-thriftserver.sh \
--hiveconf hive.server2.thrift.port=20000 \
--master local[2] \
--jars /root/software/mysql-connector-java-5.1.47-bin.jar
#启动beeline 其中 -n 后为系统用户名
启动: -n 后为系统用户名 端口与thriftserver一致
./bin/beeline -u jdbc:hive2://localhost:20000 -n root(4)编程方式访问thriftserver
a、引入jar
<!-- https://mvnrepository.com/artifact/org.spark-project.hive/hive-jdbc -->
<dependency>
<groupId>org.spark-project.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<version>1.2.1.spark2</version>
</dependency>
b、编程
object SparkSQLThriftServerApp {
def main(args: Array[String]): Unit = {
Class.forName("org.apache.hive.jdbc.HiveDriver");
//任意指定一个访问用户
val conn = DriverManager.getConnection("jdbc:hive2://hadoop:10000", "myHadoop", "");
val pstmt = conn.prepareStatement("select empno,ename,sal from emp");
val rs = pstmt.executeQuery();
while (rs.next()) {
println("empno:" + rs.getInt("empno") + "\tename:" + rs.getString("ename") + "\tsal:" + rs.getString("sal"))
}
}
}(5)比较
spark-shell、spark-sql都是一个spark application,thriftserver解决了数据共享问题,无论启动多少个客户端(beeline/code),都是一个spark application.

















 3603
3603

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









