




论文原文:Spatial Dual-Modality Graph Reasoning for Key Information Extraction
1.网络结构
一种端到端的空间双模态图推理方法。将非结构化的文档图像建模为空间双模态图,其中图节点作为检测到的文本框,图边作为这些节点之间的空间关系。

A. 特征提取
使用U-Net作为CNN的特征提取网络,获得特征viv_ivi。
- 使用字符级的BiLSTM提取文字特征,获得特征tit_iti。
多模态特征用矩阵内积(Kronecker product)融合。
ni=P(ti⨂vi) n_i = P(t_i\bigotimes v_i) ni=P(ti⨂vi)
B.图卷积
在图卷积部分,G={N,E},N={nin_ini},nin_ini代表text节点rir_iri的特征向量,由A中特征提取得到,包含视觉和文字特征;E={eije_{ij}eij} ,eije_{ij}eij代表rir_iri和 rjr_jrj 节点之间边的权值。
rijr_{ij}rij定义了两个节点rir_irirjr_jrj 的距离。(5)(6)中的x和y表示两个节点空间上的水平距离和垂直距离,(7)中的rijPr_{ij}^PrijP编码了两个节点的空间位置关系(d是一个归一化常数),rijSr_{ij}^SrijS编码了相对长宽比。

如下(10),E是将空间关系信息嵌入去维表示的线性变换的函数,rijr_{ij}rij,Nl2是l2正则化,(11)把节点表示和边的表示concat起来,然后送到(12)的三层感知机M中,将eij转换为标量eije_{ij}eij 。这样e就结合了节点信息和空间信息。

niln_i^lnil 代表了在时间为l的时候,第i个节点的特征表示,α\alphaα是可学习的归一化权重,由(14)得到;e是i节点和j节点的线性关系,w代表线性变换,σ\sigmaσ 是ReLU激活函数。这样,在l+1时刻,nil+1n_i^{l+1}nil+1 就结合了l时间i节点的的特征niln_i^lnil ,以及l+1时间的i节点特征和该节点对不同个j节点eije_{ij}eij的总和。


C.损失函数
最后将迭代推理模块的最终输出nLn^LnL输入给分类模块,对每个文本区域进行分类,loss采用交叉熵损失函数。
2.训练结果
使用了自己收集的 WildReceipt数据集。
我们在搜索引擎上搜索带有相关关键词的收据图像,如收据、发票等。我们下载了大约4300张文档图片。我们删除了里面有多个收据,不是收据,不可读,不完整或非英文的图像。我们首先标记文本边界框及其相应的文本,然后将每个边界框标记为25个关键信息类别中的一个
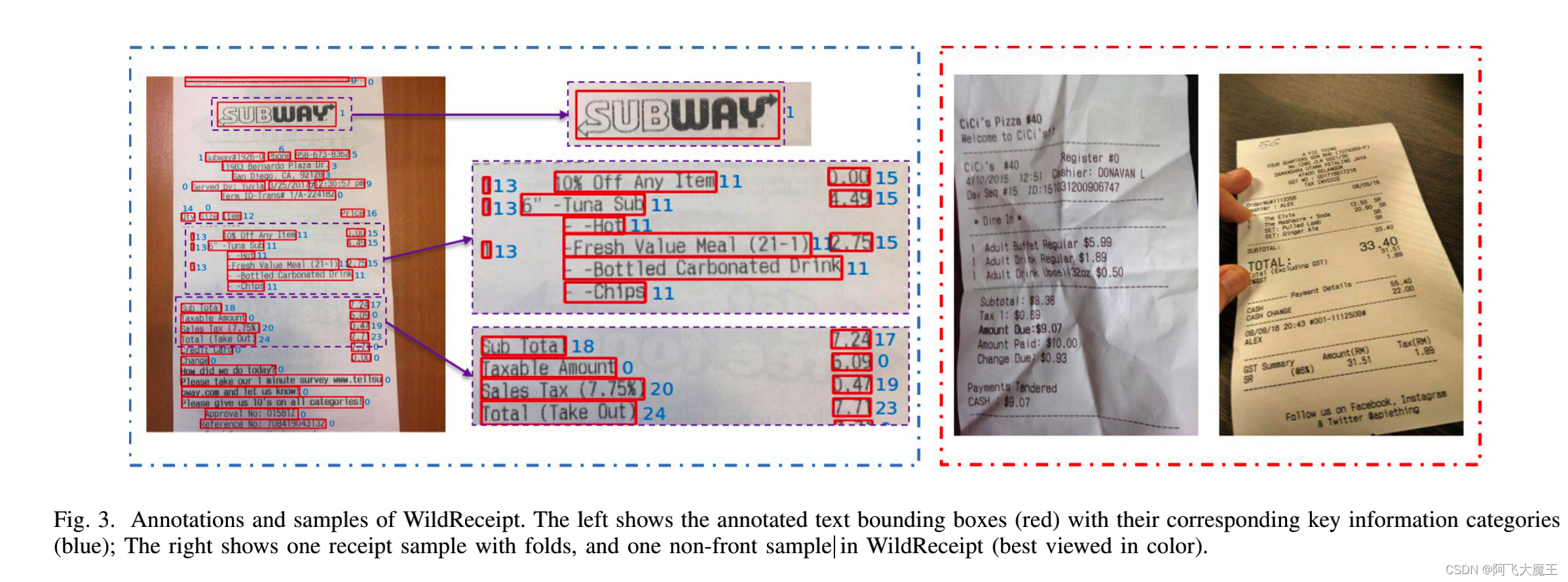
论文将SDMG-R与Chargrid、Chargrid-UNet、VRD等sota算法相对比。

3.模型训练
在paddleOCR上集成了训练代码。
在wildreceipt的数据集上,训练44epoch效果最好为87.7。
在自己的数据集上,准确率为92.4。标注的时候使用k-v标注,转一下数据格式就可用。

















 608
608

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









