




 本文介绍了用于文档关键信息抽取的SDMGR模型。该模型基于CNN+LSTM+GNN,通过Kronecker product算子融合视觉与文本模态特征,并进行计算量和内存占用优化。在SROIE和WildReceipt数据集上实验效果良好,不过作者认为其抽取性能或不如transformer - based模型。
本文介绍了用于文档关键信息抽取的SDMGR模型。该模型基于CNN+LSTM+GNN,通过Kronecker product算子融合视觉与文本模态特征,并进行计算量和内存占用优化。在SROIE和WildReceipt数据集上实验效果良好,不过作者认为其抽取性能或不如transformer - based模型。
文章目录
Spatial Dual-Modality Graph Reasoning for Key Information Extraction
基本信息
- 论文链接:arxiv
- 发表时间:2021
- 应用场景:文档关键信息抽取
摘要
| 存在什么问题 | 解决了什么问题 |
|---|---|
| 1. 先前的文档关键信息抽取大都不鲁棒(新的模板或者ocr识别结果错误),导致了其泛化性不高的缺陷。 | 1. 提出了一个端到端文档关键信息抽取模型SDMGR,将文档图像看做成一个双模态图网络,该网络融合了visual以及text信息,进而完成关键信息抽取功功能。并且该网络在泛化性很高,能够直接用于没见过的文档版式的关键信息抽取任务。 2. 提出了一个新的且更具挑战性的用于关键文档信息抽取数据集WildReceipt,包含25中kv,这其中包括了一些易混淆kv对。并且数据量是SROIE的两倍。 3. SDMGR在SROIE以及WildReceipt数据集上均取得了SOTA。 |
模型结构
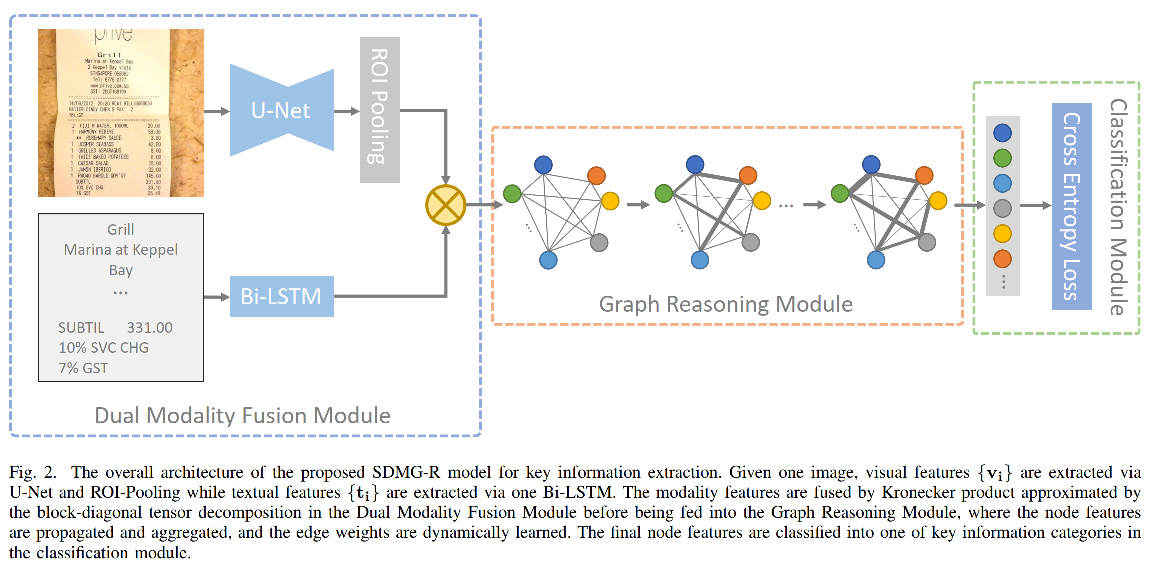
背景
对于一个OCR输出框,可以用 r i = < x i , y i , h i , w i , s i > r_i=<x_i,y_i,h_i,w_i,s_i> ri=<xi,y
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2652
2652

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









