







 本文介绍如何使用nnUNet框架进行医学图像预处理及肺结节分割。包括LUNA16数据集的处理流程,如生成mask、凸起膨起处理、强度归一化等,以及nnUNet的具体配置与训练步骤。
本文介绍如何使用nnUNet框架进行医学图像预处理及肺结节分割。包括LUNA16数据集的处理流程,如生成mask、凸起膨起处理、强度归一化等,以及nnUNet的具体配置与训练步骤。
任务一:CSD2017:
一.数据集:
来自LUNA16
· annotation.csv:包含注解的csv文件,注解用作“结节检测”轨道的参考标准,每行包含一个发现。每行都包含扫描的SeriesInstanceUID,每个发现在世界坐标中的x,y和z位置;以及相应的直径(毫米)。注释文件包含1186个结节。
· subset0.zip 到 subset9.zip:包含所有CT图像的10个zip文件
· seg-lungs-LUNA16:在每个子集中,CT图像以MetaImage(mhd / raw)格式存储。每个.mhd文件都与单独的.raw二进制文件(图片信息)存储在一起。
LUNA16数据集将切片厚度(slice thickness)大于3mm的CT去除,同时将切片space不一致以及缺失部分切片的CT也去除,最后产生了888张CT,构成了LUNA16
https://blog.youkuaiyun.com/PRINCE2327/article/details/105655644
二.预处理:
基于三维卷积神经网络对图像进行肺结节的目标检测与识别。
所有数据首先转变为Hounsfiel单元。
1.生成mask
高斯模糊,设置阈值分离不同密度组织,处理一些过小的连接等,应该是为了模糊或去除过多的杂小血管组织。
得到的肺部图像相比原来的:
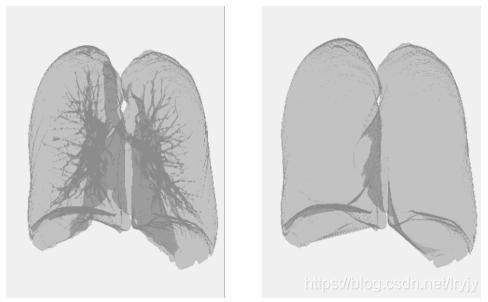
2.凸起膨起处理
对肺部的两部分肺片进行放大到平衡大小的处理
3.强度归一化
将Hounsfield单元中的数据转换为Integer,对于原始数据矩阵它用的是一个窗口[-1200,600]剪裁,然后线性转换为[0,255]
4.这是对kaggle提供的数据集进行预处理的过程,为stage2数据,DSB2017中具体生成的mask的文件是preprocessing/step1.py。作者还采用了LUNA16的stage1数据,这个数据是提供mask的。由于kaggle数据失效,而且kaggle数据需要进一步加工,这里只采用LUNA16的数据以减少训练时间。
5.LUNA数据预处理
具体而言,整个数据集是十份的,每份CT数相等,针对该数据集要执行10折交叉验证,总共可以分为四步
(1)取一份做测试集,其余九份做训练集
(2)在训练集上训练算法
(3)在测试集上测试,并生成结果文件
(4)完成10折交叉验证后,将所有结果融合为一份
总结:
由于任务有变,转入到nnunet的学习中,但是感觉入门医学图像分割学会医学图像到预处理是很重要到一步。
任务二:入门nnUNet:
1.下载nnUNet框架先跑起来
windous下(记录保存一下步骤方便以后看)
理论认识nnUNet:
· 动机:医学领域数据集之间的数据规模、图像维度、图像大小、体素灰度范围和灰度表示方面差别很大。许多新的设计概念并没有提升分割性能,有时甚至损害了基线的性能。我们假定通过给定的一组系统且谨慎选择的超参数的分割方法仍将产生有竞争力的性能,于是提出nnunet。
·预处理:Resampling/Normalization
·训练流程:所有模型都是从头开始训练,并在训练集上使用五重交叉验证进行评估
·推理(Inference):可以获得每个体素的决策。 对于测试案例,我们使用从训练集交叉验证中获得的五个网络作为整体,以进一步提高模型的鲁棒性。
·后处理:对训练数据进行所有地面真相分段标签的关联组件分析。
·组装与提交:为了进一步提高分割性能和鲁棒性,我们为每个数据集整合了三个模型中两个模型的所有可能组合。 对于最终提交,将自动选择在训练集交叉验证中达到最高平均前景dice得分的模型。
数据预处理:
把Laun16里的mhd和raw格式的医疗图像转换成nnUNet能识别到nii.gz格式。
① nnUNet需要你把你要训练的数据做一个好好的整理,nnU-Net提取数据集指纹(一组特定于数据集的属性,例如图像大小,体素间距,强度信息等)。此信息用于创建三个U-Net配置:一个2D U-Net,一个以全分辨率图像运行的3D U-Net以及一个3D U-Net级联,其中第一个U-Net在其中创建一个粗略的分割图下采样的图像,然后由第二个U-Net进行细化。:
第一步:进入你之前创建的nnUNetFrame文件夹里面,创建一个名为DATASET的文件夹,现在你的nnUNetFrame文件夹下有两个文件夹,nnUNet是代码源,另一个DATASET就是我们接下来用来放数据的地方;
第二步:进入创建好的DATASET文件夹下面,创建下面三个文件夹

第二个用来存放原始的你要训练的数据,第一个用来存放原始数据预处理之后的数据,第三个用来存放训练的模型结果。
第三步:进入上面第二个文件夹nnUNet_raw,创建下面两个,右边为原始数据,左边为crop(剪枝)以后的数据。

第四步:进入右边文件夹nnUNet_raw_data,创建一个名为Task08_HepaticVessel的文件夹(解释:这个Task08_HepaticVessel是nnUNet的作者参加的一个十项全能竞赛的子任务名,你可以对这个任务的数字ID进行任意的命名,比如你要分割心脏,你可以起名为Task01_Heart,比如你要分割肾脏,你可以起名为Task02_Kidney,前提是必须按照这种格式)
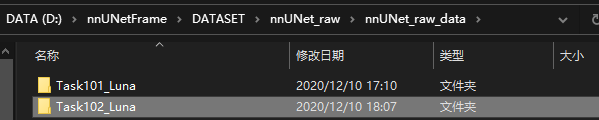
第五步:将下载好的公开数据集或者自己的数据集放在上面创建好的任务文件夹下,下面还以作者参加的Task08_HepaticVessel竞赛为例,解释下数据应该怎么存放和编辑:

你会发现目录是这个样子的:json文件是对三个文件夹内容的字典呈现(关乎你的训练),imagesTr是你的训练数据集,打开后你会发现很多的有序的nii.gz的训练文件,而labelsTr里时对应这个imagesTr的标签文件,同样为nii.gz。目前只能是nii.gz文件,nii文件都不行。训练阶段的imageTs文件夹先不管,其实这个文件夹出现在任何位置都可以。(解释:nnUNet使用的是五折交叉验证,并没有验证集)
参考:https://blog.youkuaiyun.com/weixin_42061636/article/details/107623757
最后:转换训练集让它变成nnUNet可识别到文件名,这里主要是变成xxx_0000.nii.gz模式,0000表示ct模式。
预处理结果
运行experiment_planning/nnUNet_plan_and_preprocess.py文件对nii.gz训练集和标签进行预处理,生产json文件
step1:
· 这是json.py文件指定一些需要到参数模式以及路径:
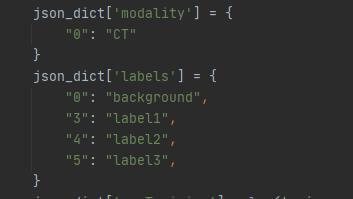
· 在3dslicer中可以看到label值,这里是345,需要修改
· 配置路径:可以配置环境变量为程序找到指定文件夹里面的训练集以及标签
· crop:放在文件夹nnUNet_cropped_data下
nnUNet_raw文件夹下的差不多作用就这些,然后被调用到后面的预处理中
step2:
· nnUNet_preprocessed\Task102_Luna里面生成第二步的处理结果
· gt_segmentations里面存放的还是标签
· 用2dunet会生成nnUNetData_plans_v2.1_2D_stage0文件(具体是怎么预处理步骤后面详细看)记录一下生成到数据
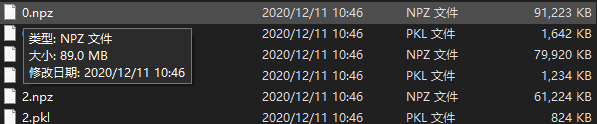
· 3dunet的话有两步处理过程分别生成nnUNetData_plans_v2.1_stage0和nnUNetData_plans_v2.1_stage1(归一化重采样等操作后面具体看)
还会生成json文件(训练集对应标签的列表,标签的字典等)和pkl文件(作用可能是保存一些关于调用这个文件夹下预处理好的数据的参数以及方法),它还将为2D和3D配置创建“计划”文件(带有ending.pkl)这些文件包含生成的分段管道配置,并且将由nnUNetTrainer读取。
step3:
·nnUNet_trained_models文件下nnUNet_trained_models\nnUNet\3d_lowres\Task102_Luna存放训练的模型以及训练的参数等,用多个模型训练之后会自动选择最好到训练策略。
(支线)任务三:深度学习课程大作业
任务四:linux服务器
终端是指硬件设备(只有输入输出没有处理器),shell是一个命令解释器,用户和系统的交互界面。
通过ssh协议(非对称密钥加密)登录服务器,ssh是建立在应用层上的安全协议,分享主机的计算能力,服务器类型有限度开放,工作站类型只对内网开放。

问题:
1.自己的电脑跑不了,搭建了服务器还没开始跑,但是对于liunx的用法等还需要熟悉。
2.关于一个模型训练到参数量以及需要用多少cuda内存需要有清晰的理解。
3.现在只是初略理论上了解了nnUNet的作用和一些原理,还需要对框架代码有更清晰的认识。
计划:
1.在服务器上跑通nnUNet,训练出来结果(用2d和3d的都跑跑看看)
2.第一步当做工程跑一下代码熟悉流程,再把它当做框架安装后熟悉其运行过程。
3.逐步看懂框架的所有代码。

















 9452
9452

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









