






他来了他来了,终于来了一个深入理解了。
**
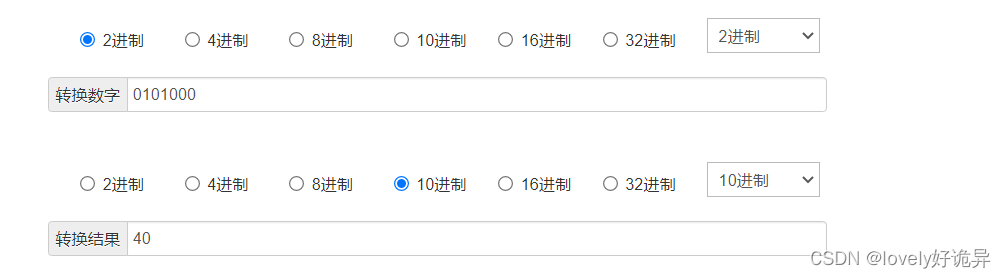
1、Hash计算
文章开始之前先理解一下<< >> >>>的含义
<<:左移 x<<y的含义为:x*2^y (x乘以2的y次方),比如2<<2结果是8
计算过程如下
#2的二进制为10 我们补成8位来计算
0000 0010
#2的二进制左移两位,左边移动后的去掉,右边补零,所以得到此结果
#该结果转换为十进制就是8,其他数的计算方法也是如此
0001 000
比如5<<4
#5的二进制为101 同样补成8位计算
0000 0101
#左移四位,去掉左边的四个零 右边再补上四个零
#0101 0000转十进制为80 也可以用公式计算5*2^4 =80
0101 0000
>>右移 x>>y的含义为 x/(2^y) (x除以2的y次方)但是有结果有正负之分,按照类似上面的推理可得:比如8>>2结果应该为2 ,-8>>2结果就为-2
>>>右移这个和上面一个类似,但是没有正负之分8>>>2的结果是2 -8>>>2的结果也是2
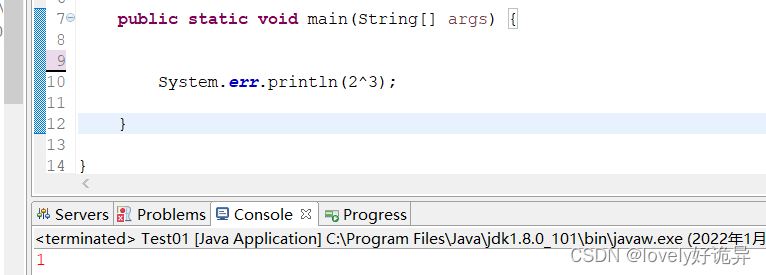
^相同为0,不同为1
这里以2^3为例
0010 #2的二进制 为0010
0011 #3的二进制为0011
所以2^3的结果是 0001 也就是1
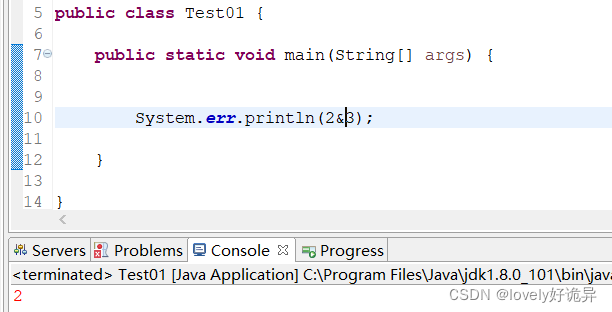
&都为1为1,其他为0
这里还是以2^3为例
0010 #2的二进制 为0010
0011 #3的二进制为0011
所以2^3的结果是 0010 也就是2
正文开始了,基本上一说hashmap底层源码都知道是数组加链表加红黑树,那么我们先从细节开始吧,文章可能一次写不完,以后慢慢补充。
put方法开始:
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
我们来看一下如何计算hash值,我们点击hash(key)进去可以看到如下代码:key==null的情况则默认为数组的第一个位置,否则就通过key的hashcode值进行^ 和>>>操作计算hash值
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
获取到hash值之后开始计算存放位置tab[i = (n - 1) & hash])
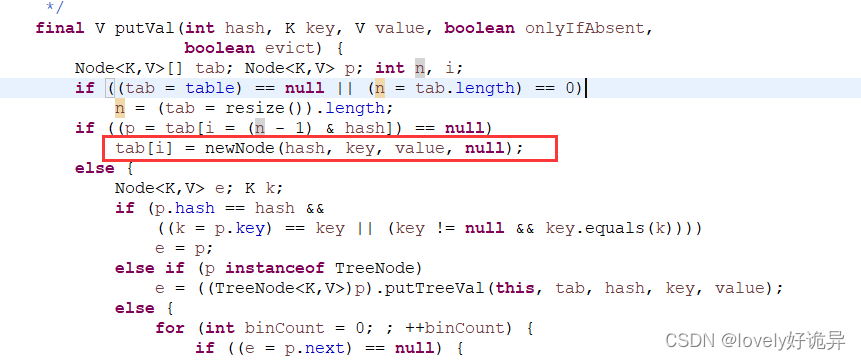
这个n就是数组的长度,存放的索引位置是(n - 1) & hash,那这里为什么是n-1呢,这个当然是为了防止hash降低hash冲突,为什么这么说呢,首先都知道数组的长度是2^n次方,这里我们以数组长度为16 key="a"和key="b"以及key="c"做测试,a的hash值为97 b的hash值为98 c的hash值为99
我们通过a、b、c三个key分别计算索引位置发现都存在第0个位置
0110 0001 #97的二进制
0001 0000 #16的二进制
0000 0000 #97&16结果转换为十进制为0
0110 0010 #98的二进制
0001 0000 #16的二进制
0000 0000 #98&16结果转换为十进制为0
0110 0011 #99的二进制
0001 0000 #16的二进制
0000 0000 #99&16结果转换为十进制为0
那么我们用15&key计算呢?
0110 0001 #97的二进制
0000 1111 #15的二进制
0000 0001 #97&15结果转换为十进制为1
0110 0010 #98的二进制
0000 1111 #15的二进制
0000 0010 #98&15结果转换为十进制为2
0110 0011 #99的二进制
0000 1111 #15的二进制
0000 0011 #99&15结果转换为十进制为3
用n-1来进行计算的分别得到的索引位置是1、2、3 这样就降低了冲突问题,那么为什么要降低冲突呢,当然是为了查找的时候快啊。假如abc分别存放了在123的位置,你查询的时候根据索引位置就能直接获取到,但是假如像上面一样都得到索引位置为0,那我获取到第0个索引的时候是不是还要遍历第0个索引的所有节点去获取,是不是就比较慢了。
2、扩容源码解读
首先使用一个变量获取原来的数组以及数组的容量和扩容的阈值
Node<K,V>[] oldTab = table;//旧数组,第一次初始化进来的时候肯定为null
int oldCap = (oldTab == null) ? 0 : oldTab.length;//第一次进来的时候默认为0
int oldThr = threshold;//默认为0
int newCap, newThr = 0;
第一次进来的时候要初始化数组,所以这也属于一个懒加载,所以第一次进来的时候,肯定会走到这个地方,在这里设置了新容量newCap =16、新阈值 newThr =12
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
初始化完成之后,将数组重新赋值,最后返回table
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
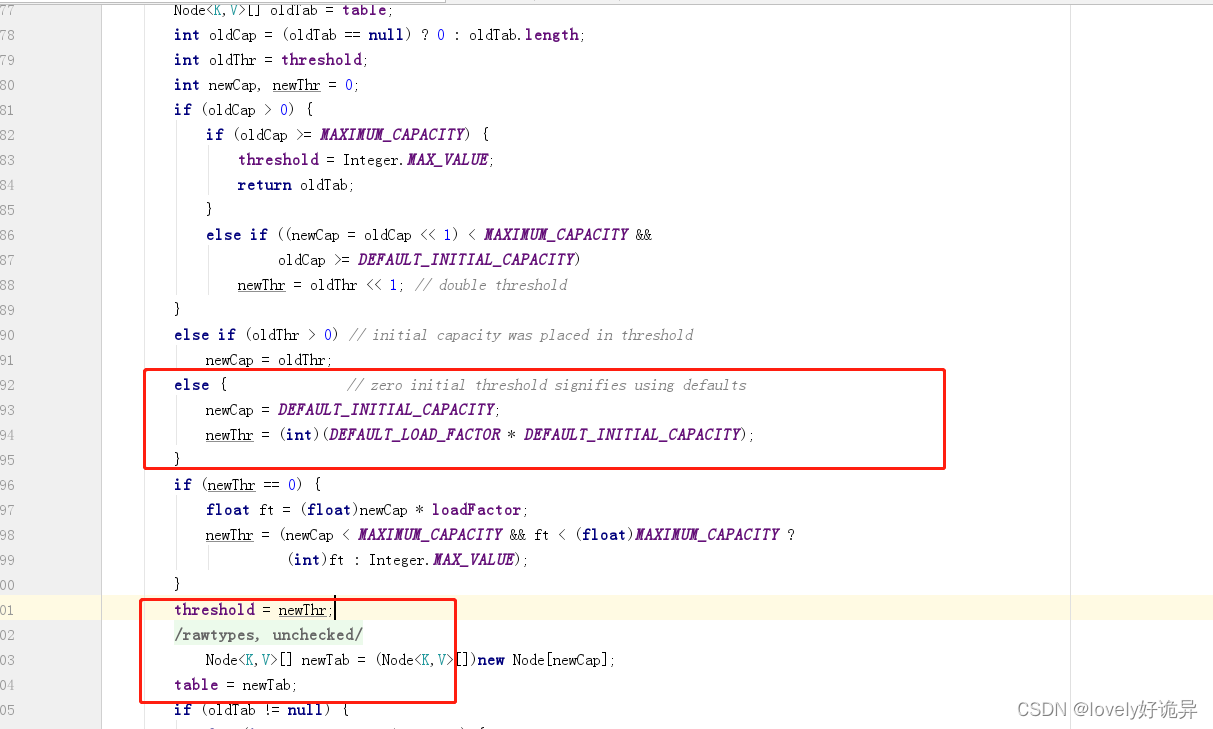
第一次初始化完成之后,主要做了两件事,初始化容量为16,计算了扩容的阈值为12。假设说现在要进行第二次扩容了。这个时候oldTable就是new HashMap<>(16)了 oldCap=16 oldThr=12。
这个时候就要走这一段代码了。oldCap=16>0,他在这里判断一下值是不是大于MAXIMUM_CAPACITY= 1 << 30 如果大于等于的话,就将阈值threshold设置为Integer的最大值,直接返回oldTab,也就说无法再扩容了。
如果oldCap没有大于MAXIMUM_CAPACITY 那么就将newCap = oldCap << 1 也就是newCap = oldCap *2=16*2,新的扩容阈值newThr = oldThr << 1;即newThr =oldThr *2=12*2

再把全局的阈值和table赋值一下
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
这一步走完之后,由于oldtable肯定不为空了,所以要将oldtable的数组内容放到新的数组上面去,也就该走下面这一段逻辑代码了。
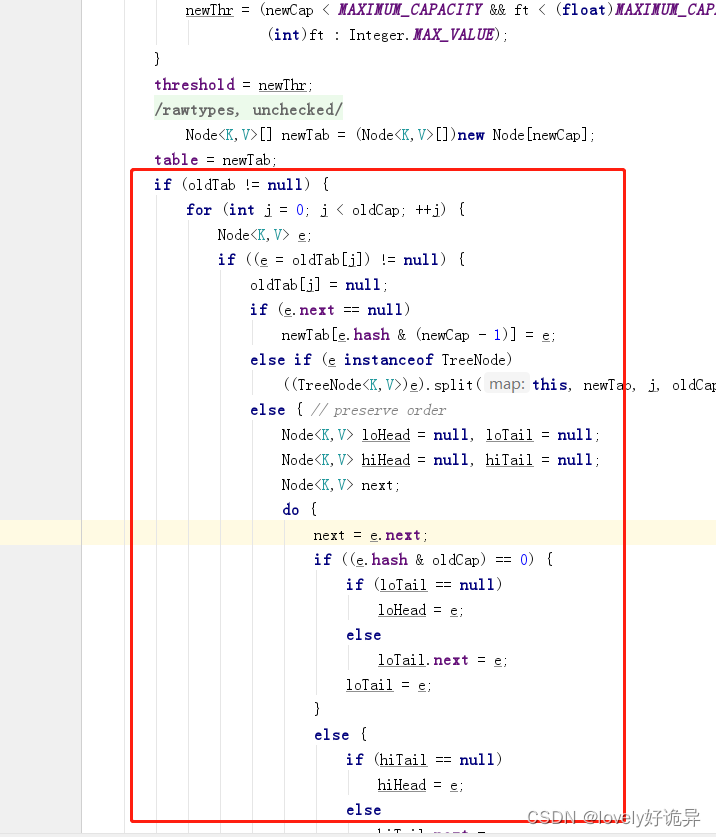
这一段代码的大致逻辑是先遍历oldTab,获取到每个节点不为空的链表,获取到该链表的时候,用一个新变量 Node<K,V> e;存放了一下,然后将oldTable对应节点的数据清空了(这点暂时没明白为啥)。
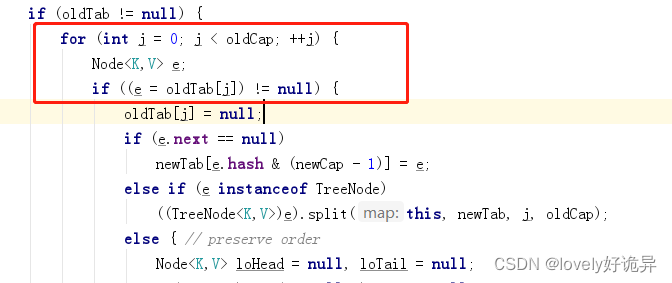
继续往下走,判断该节点下面是否还有节点,没有的话说明之前对应索引的位置没有发生hash冲突,只有一个key,这个时候直接重新利用hash去计算新数组的位置即可。
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
再下一步,判断这个节点是不是一个红黑树,是的话就进行红黑树的处理(红黑树我不咋理解里面的具体实现)
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
最后一种情况:该节点是个链表,这里设计的我感觉比较巧妙了。巧妙之处就在于他用了两个新链表将原来的旧链表拆开了,然后将两个新链表放在了新的数组位置上。那他是怎么做的呢。
他将节点的hash值和旧数组的容量做&操作,判断结果是不是0,为0的在一个链表中,不为零的在一个链表中 然后将这两个链表再分别存放在新数组位置上。
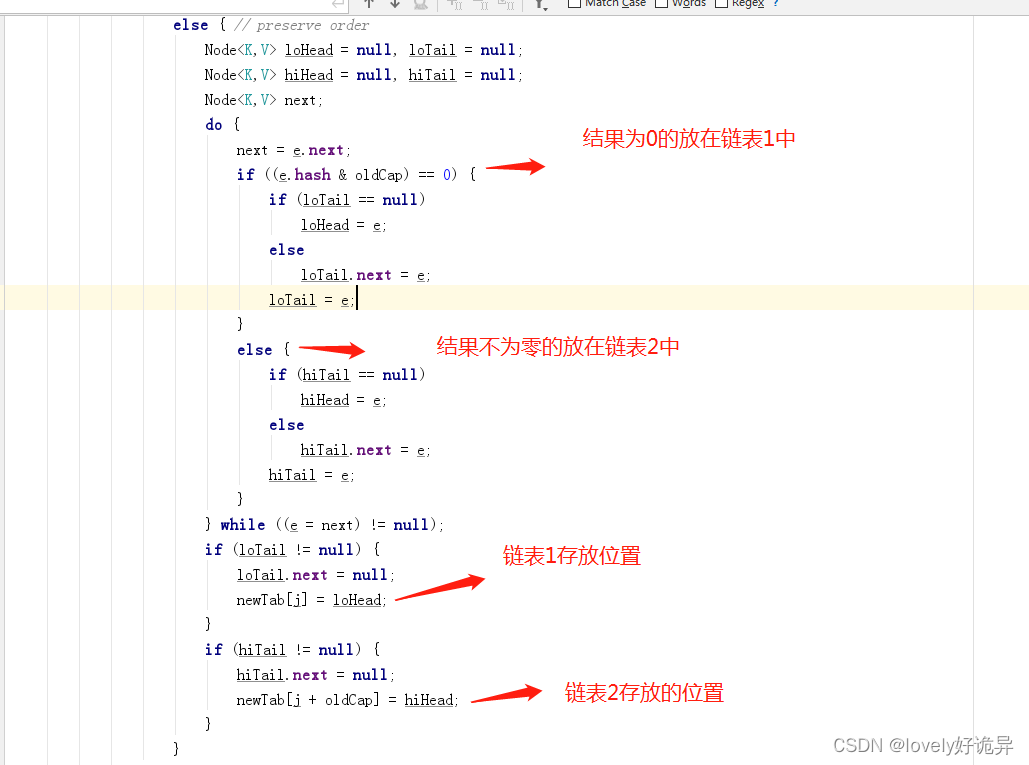
通过代码发现链表1存放在 newTab[j] = loHead; 链表2存放在 newTab[j + oldCap] = hiHead;
我当时就有疑问了,这样计算的结果存放正确吗,取的时候能取到值吗?
现在我们来进行验证一下。
以初始化容量为16,扩容后容量为32进行测试,首先我找到了在容量为16的时候索引在1的四个hash值,这个时候他应该是个链表。
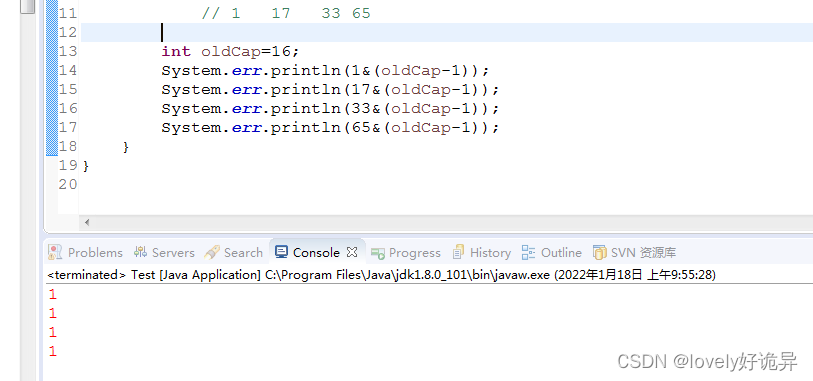
我们来进行扩容操作中的计算判断 if ((e.hash & oldCap) == 0) {,结果如下
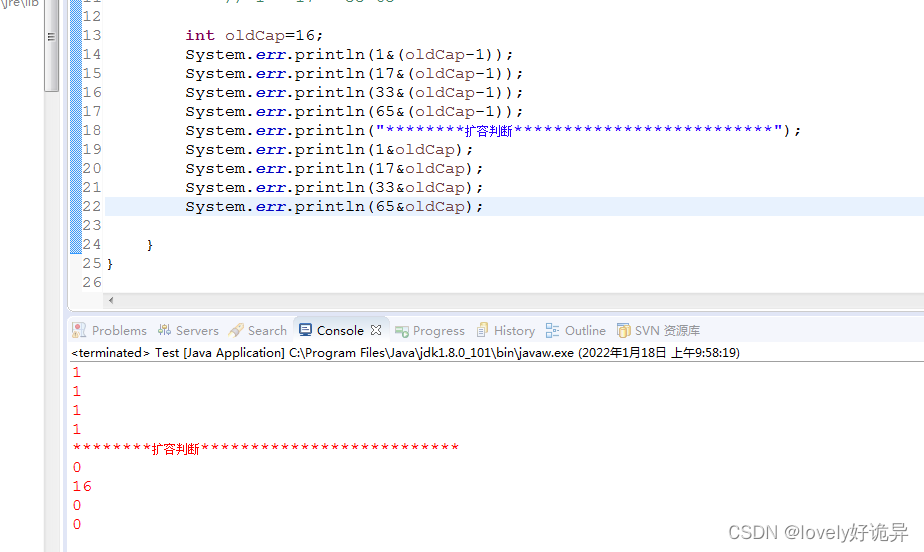
此时该链表分为了两个链表,一个存放结果是0的,存放位置应该是newTab[j] = loHead;,一个存放结果是16的newTab[j + oldCap] = hiHead; 我们再继续校验一下这样是否对呢。

通过实验,发现结果正是他那样的,巧妙之处就在于 这里是 if ((e.hash & oldCap) == 0) {
是通过hash值和旧容量值做&运算的,注意这里不是oldCap-1了,正是由于这一点,odCap是2的幂次方,所以你无论是16,32,64,得到的结果要么是0 要么是oldCap。
数据都放到新数组上之后完成扩容操作。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









