







提到人工智能算法,人工神经网络(ANN)是一个绕不过去的话题。但是对于新手,往往容易被ANN中一堆复杂的概念公式搞得头大,最后只能做到感性的认识,而无法深入的理解。正好最近笔者本人也在经历这个痛苦的过程,本着真理越辩越明的态度,索性坐下来认真的把这些头大的问题梳理一番,试试看能不能搞清楚ANN背后的数学原理。
其实ANN 的流程概括来说倒不是很复杂,以最简单的前馈神经网络为例,无非就是
搭建网络架构(含有待定参数) ---> 通过比较输出与标签的差值定义损失函数(自变量为待定参数的函数) ---> 随机给出一组初始参数 ---> [给出一个(sgd)/一批(Minibatch)训练样例(包括ANN的输入值和输出值) ---> 前向传播得到预测标签和损失 ---> [ 利用梯度下降算法从后往前调整网络参数(误差反向传播,BP)] ] ---> 得到所有参数值 ---> 得到ANN并使用
其中大括号 [] 里的内容是需要反复迭代的(注意有一部分是双重循环)。
在ANN的一堆操作里,梯度下降算法是一个相对独立的过程,不妨就让我们从梯度下降算法开始吧。
一、梯度下降到底在干什么
其实这个问题非常简单,只是大家被梯度下降复杂的过程搞蒙了,忘记了它的本质。梯度下降算法自始至终都在干一件事——就是找到函数的极值点,当然确切的说是极小值点。但是,这种方法不同于以往我们在高等数学里学到的找极值点的方法。那么我们首先就要问,求极值的经典方法不香吗?
1.求极值:传统的方法不香吗?
要回答这个问题,让我们先快速回顾一下在中学和大学里学到的传统的求极值点的方法。
对于一元函数来说,极值可能出现在一阶导函数为0的点(驻点)或是导数不存在的点。
例如要找到 f(x) = x^2 + 3x 的极值点
求导得 dy/dx = 2x + 3
令 dy/dx = 0
就得到 x = -1.5 时,导函数为0。
注意,上面找到的只是可能的极值点,也就是极值存在的必要条件。还需要验证一下充分条件,才能确定极值。这时,可以判断二阶导的正负性、或是判定一阶导在可能的极值点两边的正负情况。回到我们的例子
当 x < -1.5 时,2x + 3 < 0
当 x > -1.5 时,2x + 3 > 0
说明函数在x = -1.5 附近先下降、后上升
该点是一个极小值点对于二元函数,情况更复杂一些。首先要找出该函数的驻点和偏导数不存在的点,这些点仍然只是可能的极值点。而二元函数的驻点需要同时满足两个偏导数为0的条件,即
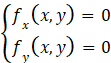
显然,这里的驻点是需要解这样一个二元方程才能求得的。对于驻点分别求出其3个二阶偏导数的值,再根据一些规则才能判断是不是极值点。
还需注意这个判断规则是不同于一元函数的,因为一元函数极值的充分条件只需要考察一个二阶偏导数,而这里则需要综合考察二元函数的3个二阶偏导数,计算量明显增大了。对于偏导数不存在的情形还需要特判。
综合以上,我们可以看出使用经典方法虽然能准确的解出极值点,但当函数自变量的个数很多时,用这种方法求解极值点还真的不香。比如:
- 该方法方法不具有普适性。所谓普适性,就是不能简单的向多元推广。从一元到二元的例子可以看出,函数的自变量个数每增加一元,就要研究新的求解方案。可以想象如果是三元函数,其二阶偏导数的个数更多,则判断极值的充分条件还要来的更加复杂。而ANN中可能会求解上亿元函数的极值点。
- 其次,这种方法需要解多元方程组,而且这些方程还不一定都是线性的。对于这种多元的非线性方程组,我们的直观感受就是很难解出。事实上,虽然存在一些可供编程的数值计算解法,但计算量大,且求出的是近似解,具有一定的局限性。
基于此,为了找出多元函数的极值点,我们还需另寻他法。这种方法要简单易行,特别是要能简单的向任意元函数推广,而且这种方法要能够适应计算机数值计算的特点,毕竟我们这套程序肯定是要放在电脑上跑的。而这就是传说中的梯度下降算法。
2.什么是梯度?
梯度的概念其实也不难,但为了让尽可能多的人明白这一概念,我们还是从一元函数开始吧。不过现在我们的目标是——用纯粹数值计算的方法,从函数上的某一点出发,找到函数的极值。这里我们只考察极小值。
2.1一元函数找极值:从枚举试探法到梯度下降法
以函数为例,让我们看看如何找到极值。
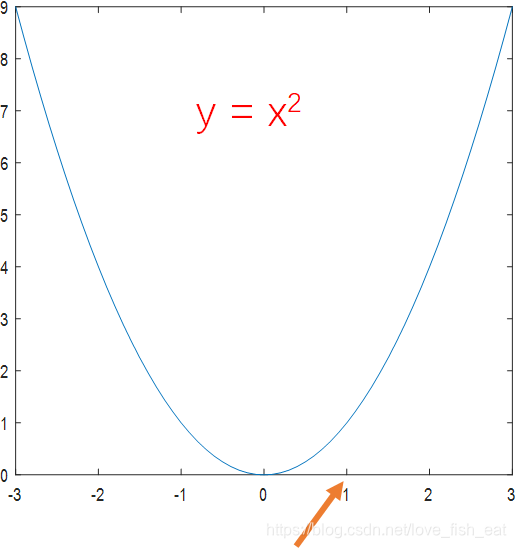
既然是从函数上的某一点出发,那么不妨设想我们在x = 1 的地方,这个地方是不是极小值点呢,我们可以试探一下。
向右走0.5,发现f(1.5) > f(1),说明这个方向是上升的方向,不应该选择这个方向;
向左走0.5,发现f(0.5) < f(1),说明这个方向是下降的方向,选择这个方向;
再向左走0.5,发现f(0) < f(0.5),说明这个方向是下降的方向,选择这个方向;
再向左走0.5,发现f(-0.5) > f(0),说明这个方向是上升的方向,不应该选择这个方向。
至此,我们可以将x = 0作为极小值点。回顾这个过程,我们将寻找极小值点的过程抽象如下:
- 首先,选择一个方向
- 试着沿该方向走一小步,并据此判断该方向是否合理。如果合理,则走这一步;如果不合理,换一个方向
- 反复重复第二步,直到找到极小值点
当然这里还有几点值得注意
- 第一,对于一元函数来说我们只有向左走或向右走两个选项。换句话说,每一步我们的选择是有限的,是可以枚举的。因此,这个方法我把它称之为枚举试探法。
- 第二,判断方向其实不必这样试错,直接求导就好。如果某点的导数值 > 0,说明在该点处函数是递增的,为了找到极小值,应该向左走;而如果导数值 < 0,则反之向右走即可。
- 第三,这种方法是不一定能找到极小值的,能不能找到极值点受选择的起始点以及每次前进的步长这两个因素影响。
对于第二点,我们可以引出梯度的定义了。
梯度是一个向量,它总指向当前函数值增长最快的方向。而它的模长则是这个最快的增长率(导数)的值。想要得到梯度向量,也很简单,它在x, y, z……等方向上的分量(坐标)就是相应的导数值。于是我们求导就可以了。
对于一元函数,函数变化的方向只有两个,我们定义一种一维的向量来表示梯度,比如5i,-5i。i前的数为正时,代表向量指向x轴正向;i前的数为负时,代表向量指向x轴负向。由下图可以看出,按照上述定义规定的梯度向量自然的指向了函数增长的方向,是不是很神奇。
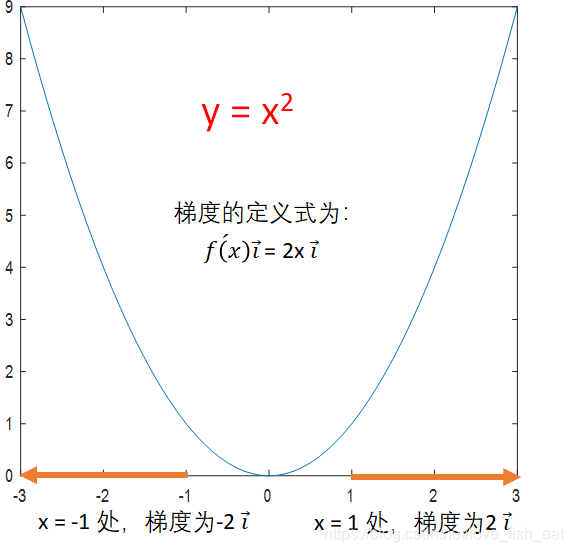
由于梯度的方向正是函数增长最快的方向,所以
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









