




 本文探讨了强化学习中基于值函数逼近和确定性策略搜索的方法,如DQN、DoubleDQN、DuelingDQN及DDPG算法,并讨论了深度学习在推荐系统中的挑战,特别是在构造状态、动作及回报函数方面。
本文探讨了强化学习中基于值函数逼近和确定性策略搜索的方法,如DQN、DoubleDQN、DuelingDQN及DDPG算法,并讨论了深度学习在推荐系统中的挑战,特别是在构造状态、动作及回报函数方面。
强化学习常用的方法有基于值函数逼近的强化学习和基于确定性策略搜索的强化学习;
基于值函数逼近的强化学习主要解决状态空间很大或者连续情况下的强化学习问题;包括DQN,double DQN,dueling DQN等;
DQN:Human-level control through deep reinforcement learning

Double DQN:Deep Reinforcement Learning with Double Q-learning

Dueling DQN:Dueling Network Architectures for Deep Reinforcement Learning
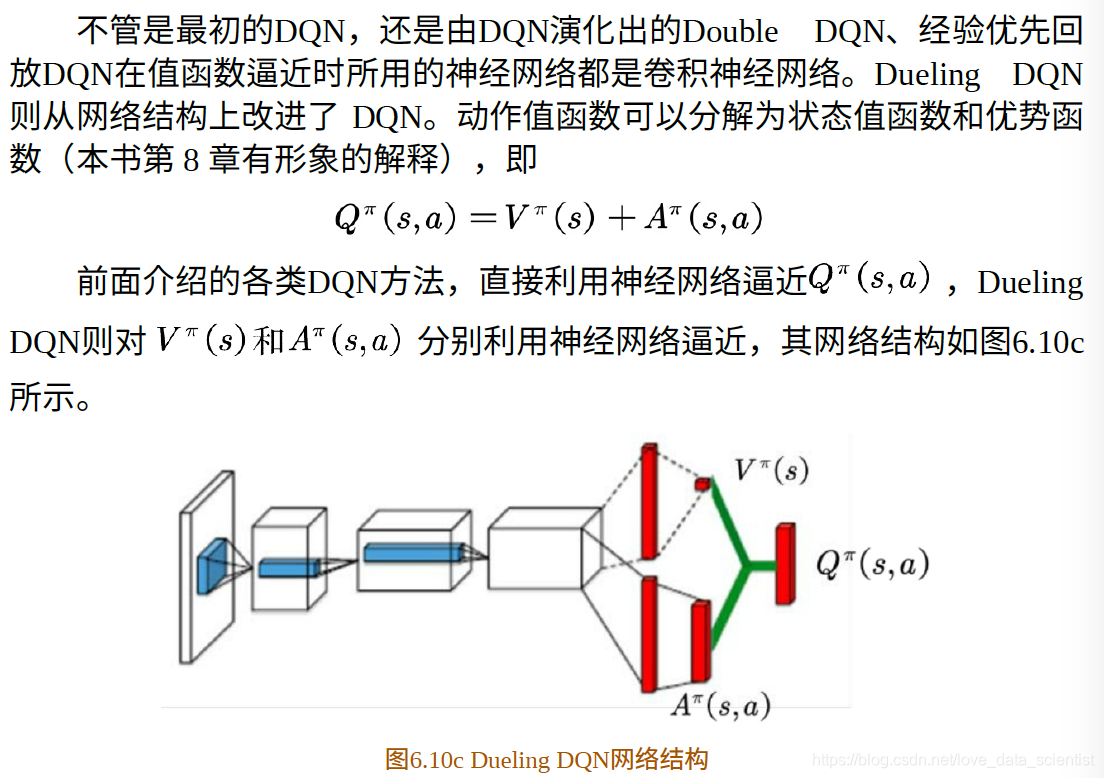
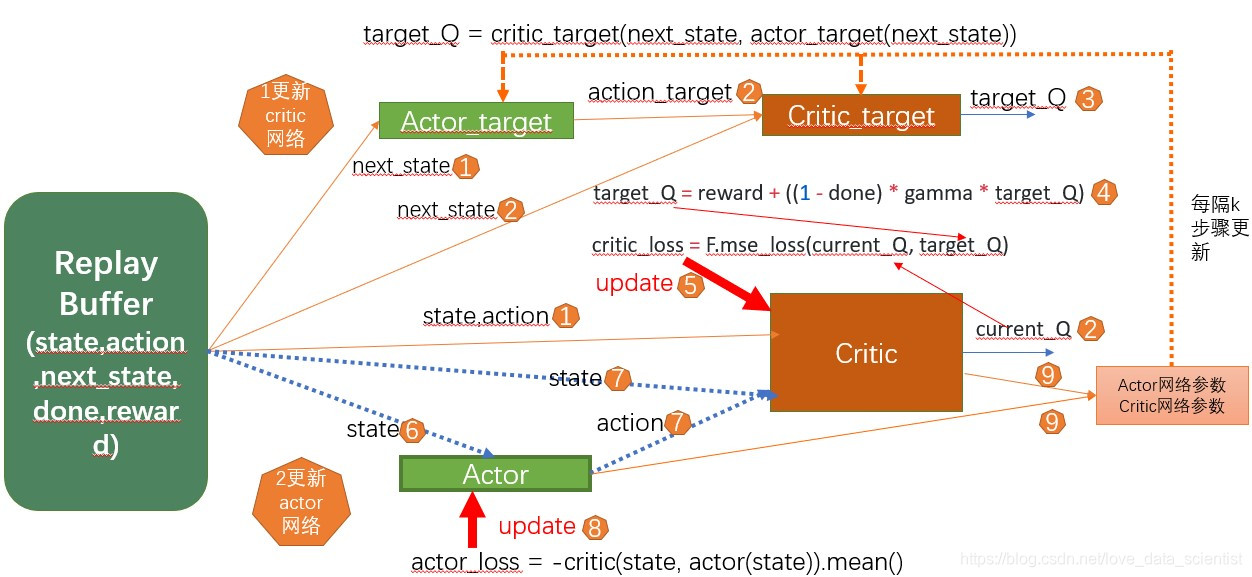
基于确定性策略搜索的强化学习主要解决动作空间或者状态-动作空间比较大或者连续情况下的强化学习问题;对应的算法是DDPG;
DDPG:CONTINUOUS CONTROL WITH DEEP REINFORCEMENT LEARNING

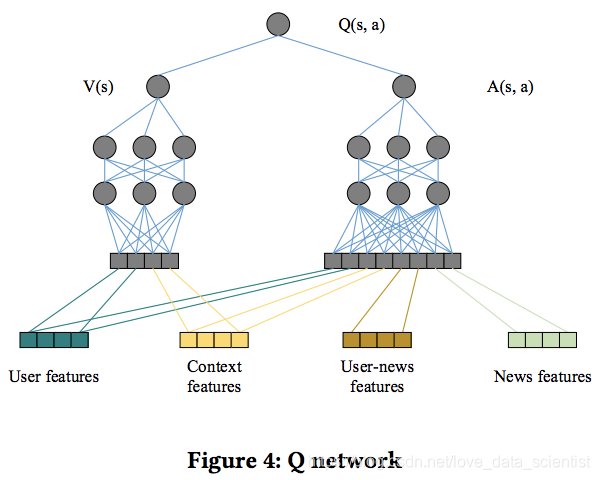
深度学习在推荐系统的应用的难点在于状态S和动作a以及回报函数的构造
DRN: A Deep Reinforcement Learning Framework for News Recommendation




















 1893
1893

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









