




目录
1、关系模式
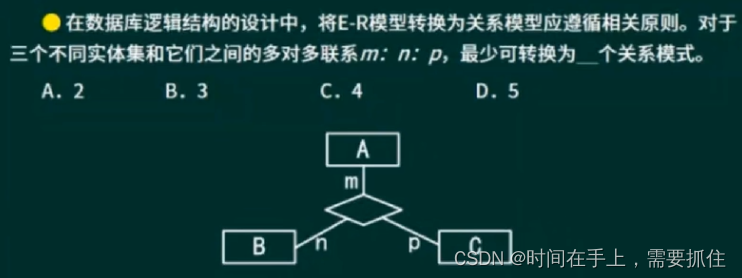 题解:这里三个实体都有多对多联系,因此关系有:A-B、A-C、B-C、A-B-C。可以转化出4个关系模式。
题解:这里三个实体都有多对多联系,因此关系有:A-B、A-C、B-C、A-B-C。可以转化出4个关系模式。
2、求候选键
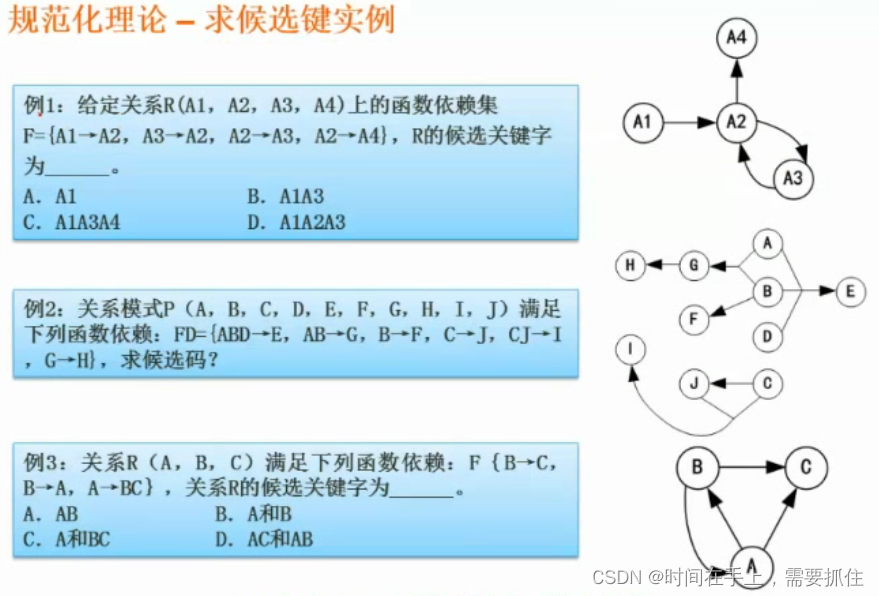 题解:候选键为能唯一标识元组的键,可以是多个属性,但没有冗余属性。可以先画出这些属性的函数关系,找到入度为0的属性,若这些属性能根据箭头遍历所有属性,则这些属性为候选键,若不能,则需要找其他中间属性,直到它们能遍历所有属性。则这些属性就是候选键。
题解:候选键为能唯一标识元组的键,可以是多个属性,但没有冗余属性。可以先画出这些属性的函数关系,找到入度为0的属性,若这些属性能根据箭头遍历所有属性,则这些属性为候选键,若不能,则需要找其他中间属性,直到它们能遍历所有属性。则这些属性就是候选键。
第一题:A1的入度为0(没有箭头指向它),且它顺着箭头能遍历其他属性,因此候选键为A1。
第二题:ABCD出发能遍历所有属性,因此候选键是ABCD。
第三题:A和B都能遍历所有属性,因此候选键为A和B。注意不能是AB,这代表AB的组合键,有冗余,不是候选键,是超键了。
3、无损分解

题解:这里关系R(A,B,C),依赖关系为A->B。相当于候选键是(A,C)。
分解1就是把R分成R1(A,B),R2(A,C)。这里分解1显然是无损分解。R2(A,C)和依赖A->B(该依赖在R1中保存),可以推出(A,C,B)。
分解2把R分成R1(A,B),R3(B,C),这里无法反推出(A,B,C),因为对于R1来讲,无法根据A或B推出C,对于R2来讲,无法根据B或C推出A,因此分解2是有损分解。
这里也可以用公式判断:R1∩R2=A,而函数关系里有A->的函数依赖,因此是无损分解。而R1∩R3=B,函数关系里没有B->的函数依赖,因此是有损分解。
4、数据库设计阶段和步骤

题解:数据库设计阶段有:需求分析->概念设计->逻辑设计->物理设计。
概念设计步骤为:数据抽象、设计各个局部ER模型、解决冲突合并局部ER模型、重构优化消除冗余。
逻辑设计步骤为:转化数据模型、关系规范化(范式)、模式优化、设计用户模式(视图)。逻辑设计第一步就是将ER模型转化为特定DBMS的数据模型,接着是范式优化、模式优化(暴露给应用程序的视图)、最后设计暴露给用户的视图。因此选B。
需求分析输出物是:数据流图、数据字典、需求说明书。
概念设计输出物是:ER模型(与DBMS无关的概念模型)。
逻辑设计输出物是:关系模式(视图、完整性约束以及应用处理说明书)。
物理设计输出物是:数据库物理存储结构以及存取方式等。uhao
5、自然连接与笛卡尔积


题解:上面给相等的列做笛卡尔积并投影去重列相当于自然连接,选择A。B写法错误,C中直接笛卡尔积投影去重列,这里没有筛选显然错误。D中错误,应该筛选笛卡尔积中两列同时相等的数据。 这里π表示投影,相当于sql中的select。![]() 表示选择,相当于sql中的where。这里×表示笛卡尔积,
表示选择,相当于sql中的where。这里×表示笛卡尔积,![]() 表示自然连接。
表示自然连接。
6、冗余和异常分析
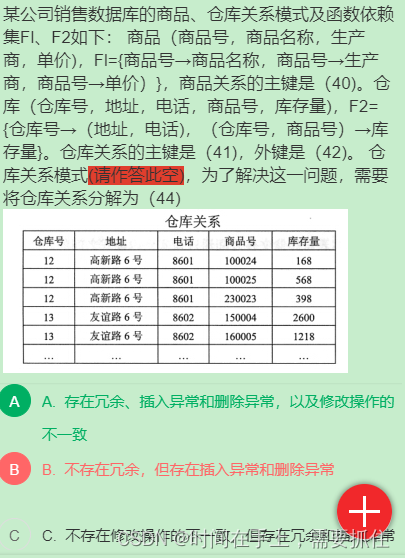
题解:这里仓库关系的主键是(仓库号,商品号),而仓库号可以直接决定地址和电话,存在部分依赖,因此不满足2NF,存在冗余字段(地址和电话),看表数据也可知地址和电话的数据大量重复,地址和电话会导致插入和删除修改异常。
7、环型候选键

题解: 画图如下:
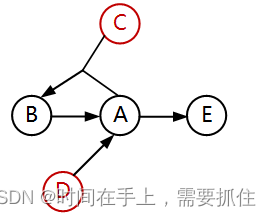
这里A可以由D决定,因此(C,A)->B可以变成(C,D)->B,看出也可以看出,D可以推出A和E,而C和A可以推出B,因此主键为CD。
8、有损分解和函数依赖保持

题解:这里可以用公式判断,即取两个关系的交集得到公共字段,若函数关系里有该公共字段的依赖关系则为无损判断。即:R1∩R2=C,函数关系里无 C-> 的依赖,因此这两个为有损分解(有损连接)。这里D和A不在同一张表,因此D->A函数关系没有保留,因此没有保持函数依赖。
9、并发控制完整性保证

题解:安全、可靠、兼容都不是,完整数据一致才是并发控制的目标。
10、UML的功能与设计阶段

题解:UML需要将实体类具体化为数据库表结构,因此为逻辑设计阶段,需要将模型具体化为某个数据库的关系模型。概念设计仅仅是设计出ER模型,不需要具体到数据库表结构,物理设计是精确到存储文件。
11、数据采集的纠正数据

题解:采集数据的纠正数据叫做数据清洗。
12、分布式事务

题解:站点有问题,应该向协调器问询最终结果再进行相应的处理。
13、索引创建影响的模式

题解:建立索引不会影响外模式(视图)、表结构(模式)、会影响物理文件(会有索引文件),选B。另外内模式主要是定义内部记录类型、索引和文件的组织方式以及数据控制的细节。
14、数据挖掘的分析方法

题解:这里输入集是已标识的记录集,因此选C,具体分析方法如下:
关联分析:目的是为了挖掘隐藏在数据间的相互关系,需要设置规则矩阵以及计算参数(最小置信度和最小支持度)。
序列模式分析:目的也是挖掘数据间的关系,其侧重点在于分析数据间的前后关系,也要计算置信度和支持度。
分类分析:为每个记录赋予一个标识,然后检查这些标识的记录,描述这些记录的特征。这些描述可能是显示的,比如规则定义,也可以是隐式的,比如一个数据公式或模型。
聚类分析:它是分类分析的逆过程,先数据一组未标定的记录(记录未被做任何处理),然后根据一定的规则合理的划分记录集合。并用隐式或显式的方法描述不同的类别。
15、数据仓库的特点

题解:数据的特点具体如下:
面向主题:数据仓库的数据按照一定主题域进行组织。主题是一个抽象概念,可以是某个业务或用户关注的方面。即这些数据是和某些业务(主题)相关。
集成性:数据仓库的数据都是对各系统分散的数据进行抽取清洗,然后再加工、汇总、整理而来。即这些数据由不同分散的库数据通过数据仓库集成在了一起。
相对稳定性:数据仓库的数据主要给企业决策分析用,一般情况下数据会被长期保留,提供各种查询操作,增删比较少,只是定期加载刷新数据。
反映历史变化:数据库数据通常包含历史信息,记录了企业过去某一时间点到目前各阶段的信息,通过这些信息,可以对企业的发展历程和未来趋势做出定量分析和预测。
显然,这里提供各种查询,增删少是数据相对稳定的特点。
16、除与连接

题解:R和S的自然连接,公共列的值都相同才匹配然后去重组成新关系,这样的话,会造成R或S的某些行数据(元组)被舍弃了。为此,加入了左外联接、右外联接和完全外联接。左外联接则是把左边比如R的舍弃的元组加入到新关系中,右外联接类似,把右边舍弃的元组加入到新关系中,没有值的补空数据。完全外连接则是把舍弃的元组都加入到新关系中。
这里R和S进行自然连接,只有两行元组能匹配上,即新关系只有2行元组数据,R和S分别舍弃2行元组。左外和右外分别补上2个舍弃的元组,因此都是4,而完全外联接需要4行舍弃的元组都加入到新关系里,因此完全外连接有6个元组。选D。
17、分布式数据库系统的特性

题解:“数据在不同场地存储”体现了分布性,“某地瘫痪可以使用其它副本”体现了可用性。选D。



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











