




 本文介绍了传统单一节点存储在性能、可用性和运维成本方面的问题,阐述了数据分片(垂直和水平分片)的概念和作用。重点讲解了ShardingSphere-JDBC数据分片的核心概念、原理,并给出了在spring-boot项目中的实现示例,包括数据库表创建、依赖引入、参数配置和代码示例。
本文介绍了传统单一节点存储在性能、可用性和运维成本方面的问题,阐述了数据分片(垂直和水平分片)的概念和作用。重点讲解了ShardingSphere-JDBC数据分片的核心概念、原理,并给出了在spring-boot项目中的实现示例,包括数据库表创建、依赖引入、参数配置和代码示例。
文章目录
ShardingSphere 数据分片模块的主要设计目标是尽量像使用一个数据库表一样使用 水平分片之后的数据库表集群。
原文链接,点击跳转
文中示例源码请关注 “Qin的学习营地”,回复:【ShardingShpere-JDBC之数据分片】
单一节点存储问题
传统数据存储方案是将数据集中存储至单一节点,在性能、可用性和运维成本这三方面已经难于满足海量数据的场景。
- 从性能方面来说,由于关系型数据库大多采用 B+ 树类型的索引,在数据量超过阈值的情况下,索引深度的增加也将使得磁盘访问的 IO 次数增加,进而导致查询性能的下降;同时,高并发访问请求也使得集中式数据库成为系统的最大瓶颈。
- 从可用性的方面来讲,服务化的无状态性,能够达到较小成本的随意扩容,这必然导致系统的最终压力都落在数据库之上。 而单一的数据节点,或者简单的主从架构,已经越来越难以承担。数据库的可用性,已成为整个系统的关键。
- 从运维成本方面考虑,当一个数据库实例中的数据达到阈值以上,对于 DBA 的运维压力就会增大。 数据备份和恢复的时间成本都将随着数据量的大小而愈发不可控。一般来讲,单一数据库实例的数据的阈值在 1TB 之内,是比较合理的范围。
数据分片
数据分片指按照某个维度将存放在单一数据库中的数据分散地存放至多个数据库或表中以达到提升性能瓶颈以及可用性的效果。 数据分片的有效手段是对关系型数据库进行分库和分表。分库和分表均可以有效的避免由数据量超过可承受阈值而产生的查询瓶颈。
- 分库是按照一定规则将整个数据库中的数据划分到不同的物理数据库中。分库能够有效的分散对数据库单点的访问量,提高数据库的性能和扩展性。
- 分表是按照一定规则将一张表中的数据划分到不同的物理表中(分表都在同一个物理数据库中),分表的目标是通过将大表拆分成多个小表,以便更容易地管理和维护索引,提高索引的效率,减轻单一表的负担,优化对大表的查询性能,提高数据库查询性能。
通过分库和分表进行数据的拆分来使得各个表的数据量保持在阈值以下,以及对流量进行疏导应对高访问量,是应对高并发和海量数据系统的有效手段。 数据分片的拆分方式又分为垂直分片和水平分片。
垂直分片
按照业务拆分的方式称为垂直分片,又称为纵向拆分,它的核心理念是专库专用。 在拆分之前,一个数据库由多个数据表构成,每个表对应着不同的业务。而拆分之后,则是按照业务将表进行归类,分布到不同的数据库中,从而将压力分散至不同的数据库。 下图展示了根据业务需要,将用户表和订单表垂直分片到不同的数据库的方案。
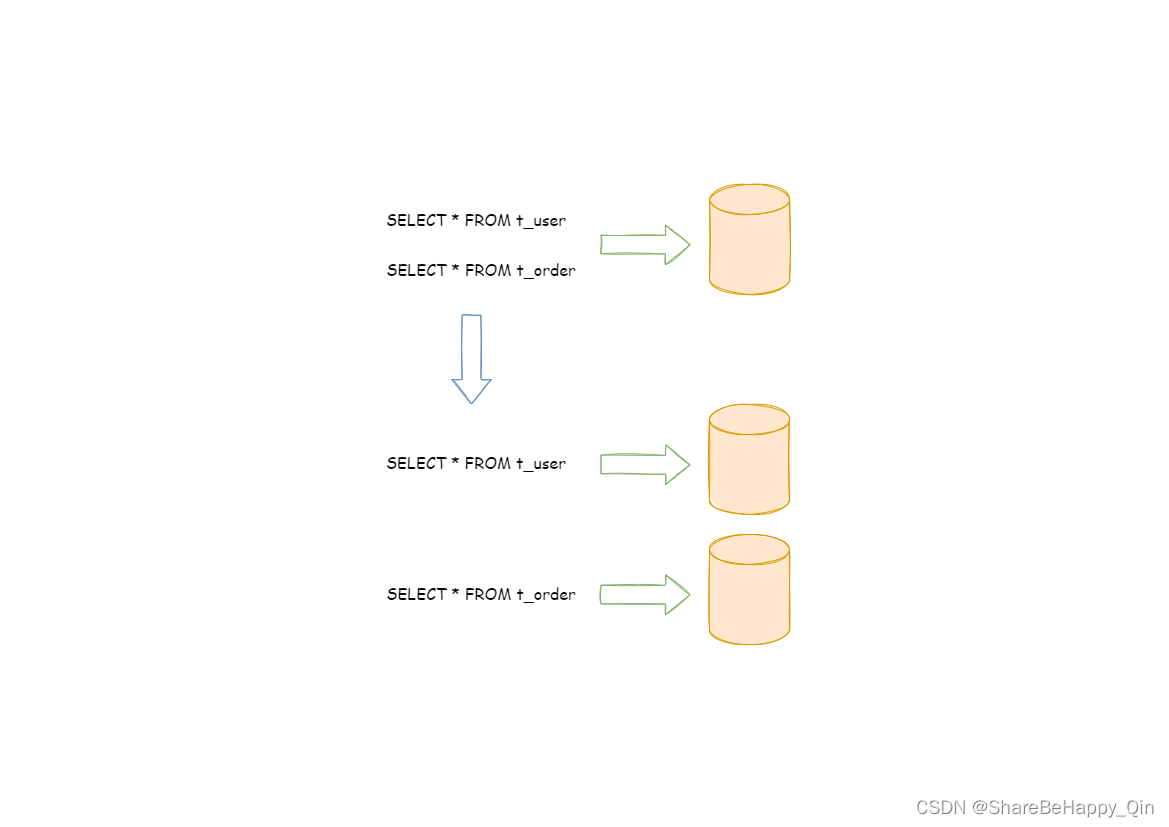
垂直分片往往需要对架构和设计进行调整。通常来讲,是来不及应对互联网业务需求快速变化的;而且,它也并无法真正的解决单点瓶颈。 垂直拆分可以缓解数据量和访问量带来的问题,但无法根治。如果垂直拆分之后,表中的数据量依然超过单节点所能承载的阈值,则需要水平分片来进一步处理。
水平分片
水平分片又称为横向拆分。 相对于垂直分片,它不再将数据根据业务逻辑分类,而是通过某个字段(或某几个字段),根据某种规则将所有数据分散至多个库或表中。 例如:根据主键分片,偶数主键的记录放入 0 库(或表),奇数主键的记录放入 1 库(或表),如下图所示。
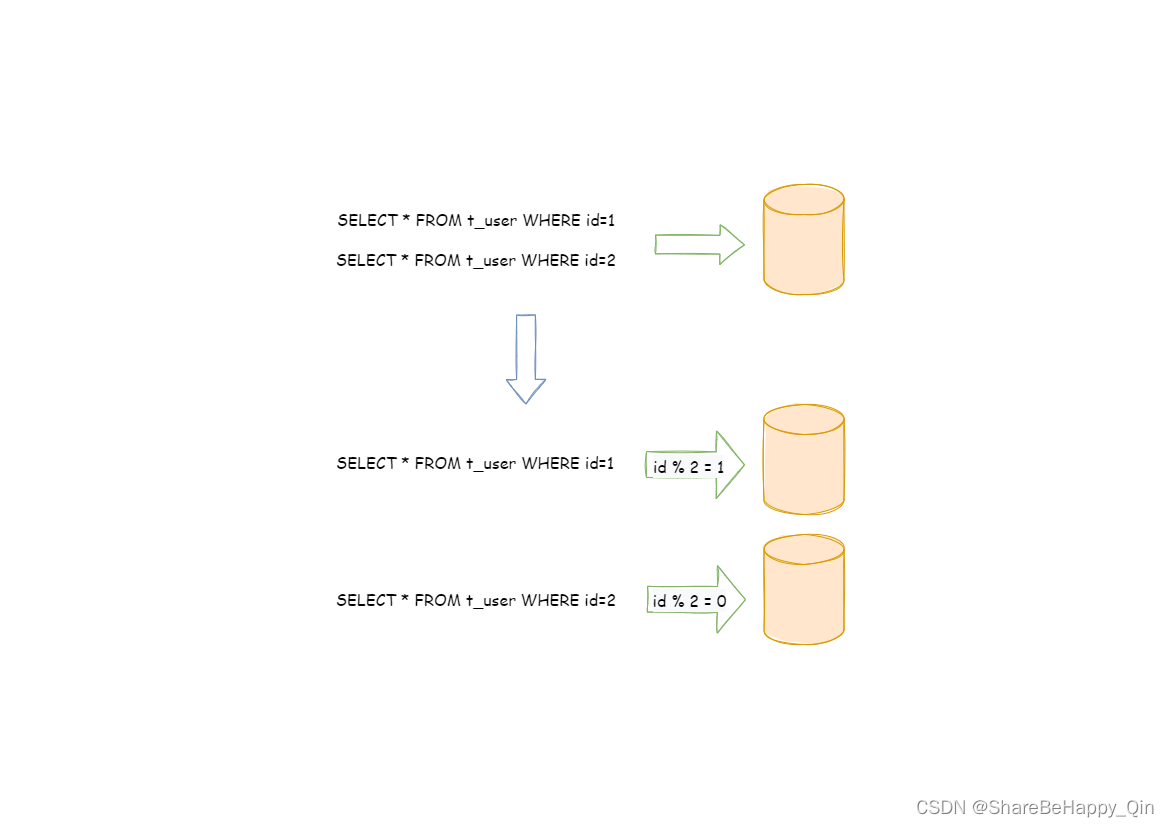
水平分片从理论上突破了单机数据量处理的瓶颈,并且扩展相对自由,是数据分片的标准解决方案。
ShardingSphere-JDBC 数据分片核心概念
表相关概念
逻辑表
- 单表水平拆分后的所有分表的逻辑名称,是 SQL 中表的逻辑标识。 例:订单数据根据主键尾数拆分为 10 张表,分别是
t_order_0到t_order_9,他们的逻辑表名为t_order。
真实表
- 数据库中在水平拆分后的真实存在的物理表。 上述示例中的
t_order_0到t_order_9就是真实表。
绑定表
- 指分片规则一致的一组分片表。 使用绑定表进行多表关联查询时,必须使用分片键进行关联,否则会出现笛卡尔积关联或跨库关联,从而影响查询效率。 例如:
t_order表和t_order_item表,均按照order_id分片,并且使用order_id进行关联,则此两张表互为绑定表关系。 绑定表之间的多表关联查询不会出现笛卡尔积关联,关联查询效率将大大提升。 - 比如两张主表 t_order_0 和 t_order_1 表,两张子表 t_order_item_0 和 t_order_item_1。绑定之后关联只会出现 t_order_0 和 _order_item_0 关联,t_order_1 和 t_order_item_1 关联,不会出现 t_order_0 和 _order_item_1 关联,t_order_1 和 t_order_item_0 关联的情况。
广播表
- 指所有的数据源(库)中都存在的表,表结构及其数据在每个数据库中均完全一致。 适用于数据量不大且需要与海量数据的表进行关联查询的场景,例如:字典表。
单表
-
指所有的分片数据源中仅唯一存在的表。 适用于数据量不大且无需分片的表。
-
注意:符合以下条件的单表会被自动加载:
-
数据加密、数据脱敏等规则中显示配置的单表
-
用户通过 ShardingSphere 执行 DDL 语句创建的单表
-
-
其余不符合上述条件的单表,ShardingSphere 不会自动加载,用户可根据需要配置单表规则进行管理。
数据节点
数据节点是数据分片的最小单元,由数据源(库)名称和真实表组成。 例:ds_0.t_order_0。可分为均匀分布和自定义分布两种形式。
均匀分布:
-
指数据表在每个数据源内呈现均匀分布的形式, 例如:
db0 ├── t_order0 └── t_order1 db1 ├── t_order0 └── t_order1 -
数据节点的配置如下:
db0.t_order0, db0.t_order1, db1.t_order0, db1.t_order1
自定义分布:
-
指数据表呈现有特定规则的分布, 例如:
db0 ├── t_order0 └── t_order1 db1 ├── t_order2 ├── t_order3 └── t_order4 -
数据节点的配置如下:
db0.t_order0, db0.t_order1, db1.t_order2, db1.t_order3, db1.t_order4
分片
分片规则中配置的真实表、分片列和分布式序列需要和数据库中的列保持大小写一致。
分片键
- 用于将数据库(表)水平拆分的数据库字段。 例:将订单表中的订单主键的尾数取模分片,则订单主键为分片字段。 SQL 中如果无分片字段,将执行全路由,性能较差。 除了对单分片字段的支持,Apache ShardingSphere 也支持根据多个字段进行分片。
分片算法
用于数据分片的算法,支持 =、>=、<=、>、<、BETWEEN 和 IN 进行分片。 分片算法可由开发者自行实现,也可使用 Apache ShardingSphere 内置的分片算法语法糖,灵活度非常高。
-
自动化分片算法
分片算法语法糖,用于便捷的托管所有数据节点,使用者无需关注真实表的物理分布。 已实现的分片算法包括取模、哈希、范围、时间等常用分片算法。
-
自定义分片算法
提供接口让应用开发者自行实现与业务实现紧密相关的分片算法,并允许使用者自行管理真实表的物理分布。 自定义分片算法又分为:
- 标准分片算法:用于处理使用单一键作为分片键的
=、IN、BETWEEN AND、>、<、>=、<=进行分片的场景。 - 复合分片算法:用于处理使用多键作为分片键进行分片的场景,包含多个分片键的逻辑较复杂,需要应用开发者自行处理其中的复杂度。
- Hint 分片算法:用于处理使用
Hint行分片的场景。
- 标准分片算法:用于处理使用单一键作为分片键的
分片策略
- 包含分片键和分片算法,由于分片算法的独立性,将其独立抽离。 真正可用于分片操作的是分片键 + 分片算法,也就是分片策略。
强制分片路由
- 对于分片字段并非由 SQL 主键而是其他外置条件决定的场景,可使用 SQL Hint 注入分片值。 例:按照员工登录主键分库,而数据库中并无此字段。 SQL Hint 支持通过 Java API 和 SQL 注释两种方式使用。
行表达式
- 行表达式是为了解决配置的简化与一体化这两个主要问题,通过行表达式可以有效地简化数据节点配置工作量。
- 行表达式作为字符串由两部分组成,分别是字符串开头的对应 SPI 实现的 Type Name 部分和表达式部分。 以
<GROOVY>t_order_${1..3}为例,其被<>符号包裹GROOVY为 Type Name,字符串t_order_${1..3}为表达式部分。当行表达式不指定 Type Name 时,例如t_order_${1..3},行表示式默认将使用InlineExpressionParserSPI 的GROOVY实现来解析表达式。 - 行表达式的使用非常直观,只需要在配置中使用
${ expression }或$->{ expression }标识行表达式即可。 目前支持数据节点和分片算法这两个部分的配置。行表达式的内容使用的是 Groovy 的语法,Groovy 能够支持的所有操作,行表达式均能够支持。
分布式主键
- 传统数据库软件开发中,主键自动生成技术是基本需求。而各个数据库对于该需求也提供了相应的支持,比如 MySQL 的自增键,Oracle 的自增序列等。 数据分片后,不同数据节点生成全局唯一主键是非常棘手的问题。同一个逻辑表内的不同实际表之间的自增键由于无法互相感知而产生重复主键。 虽然可通过约束自增主键初始值和步长的方式避免碰撞,但需引入额外的运维规则,使解决方案缺乏完整性和可扩展性。
- 目前有许多第三方解决方案可以完美解决这个问题,如 UUID 等依靠特定算法自生成不重复键,或者通过引入主键生成服务等。为了方便用户使用、满足不同用户不同使用场景的需求, Apache ShardingSphere 不仅提供了内置的分布式主键生成器,例如 UUID、SNOWFLAKE,还抽离出分布式主键生成器的接口,方便用户自行实现自定义的自增主键生成器。
ShardingSphere-JDBC 数据分片原理
ShardingSphere 的 3 个产品的数据分片主要流程是完全一致的,按照是否进行查询优化,可以分为 Standard 内核流程和 Federation 执行引擎流程。 Standard 内核流程由 SQL 解析 => SQL 路由 => SQL 改写 => SQL 执行 => 结果归并 组成,主要用于处理标准分片场景下的 SQL 执行。 Federation 执行引擎流程由 SQL 解析 => 逻辑优化 => 物理优化 => 优化执行 => Standard 内核流程 组成,Federation 执行引擎内部进行逻辑优化和物理优化,在优化执行阶段依赖 Standard 内核流程,对优化后的逻辑 SQL 进行路由、改写、执行和归并。
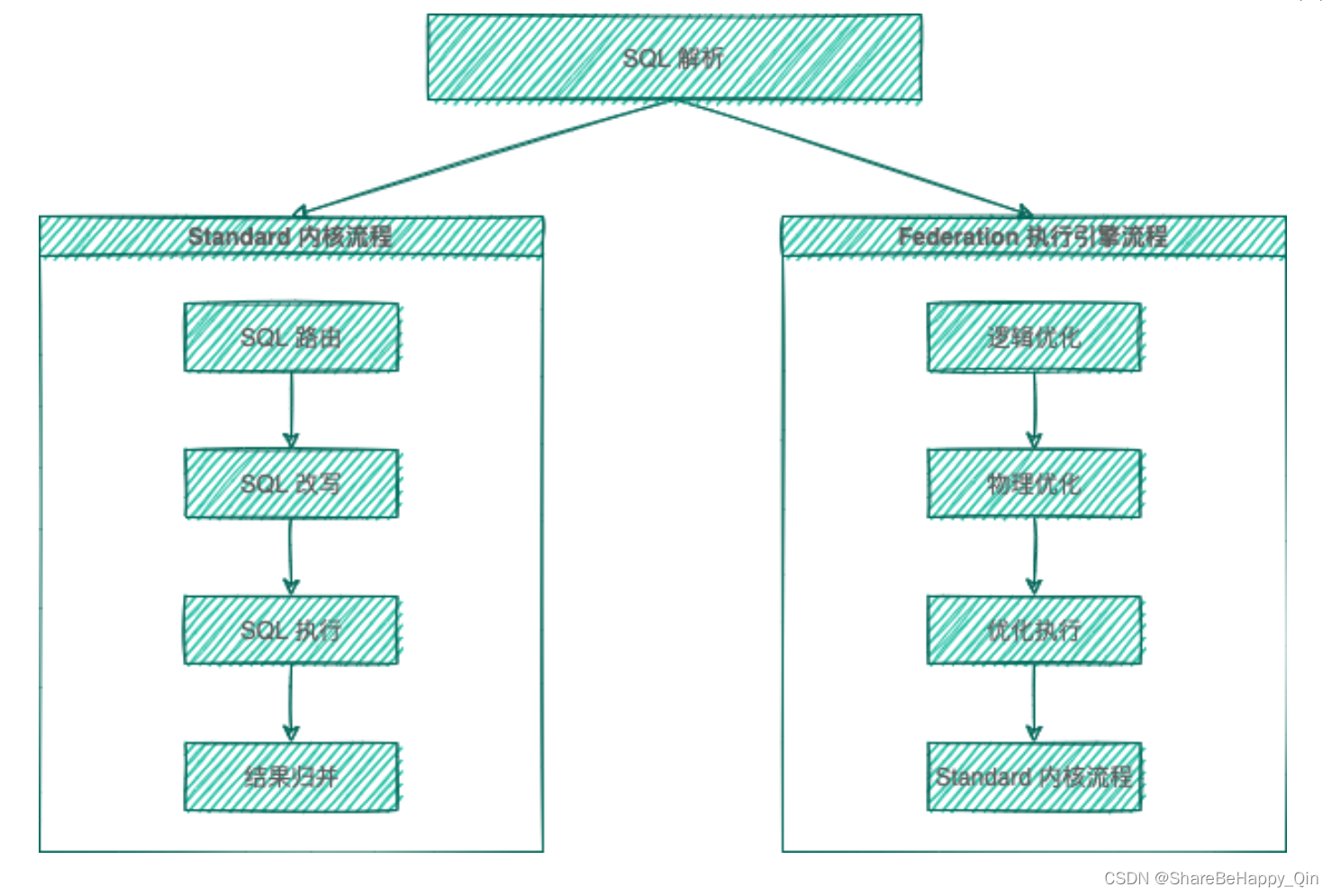
SQL 解析
- 分为词法解析和语法解析。 先通过词法解析器将 SQL 拆分为一个个不可再分的单词。再使用语法解析器对 SQL 进行理解,并最终提炼出解析上下文。 解析上下文包括表、选择项、排序项、分组项、聚合函数、分页信息、查询条件以及可能需要修改的占位符的标记。
SQL 路由
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









