







YOLO 顾名思义: You Only Look Onece。你只需要看一次,对比与fasterrcnn先提取前景(Proposal),再对前景进行分类和回归两步走,YOLO 意思就是一步到位,直接是backbone之后就进行分类和回归。
YOLO的目的就是要追求速度。
核心思想
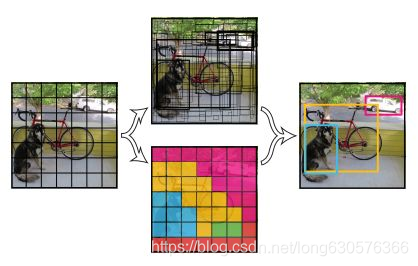
如何一步到位?最简单的就是图像网格化。如果某个object 的中心点落在这个网格,这个网格就负责预测这个object。
如何预测呢?一个网格预测B个bbox, 每个bbox 预测本身的位置回归还要预测一个confidence值。
confidence 代表了这个bbox含有object的置信度和这个bbox预测多准。计算如下:
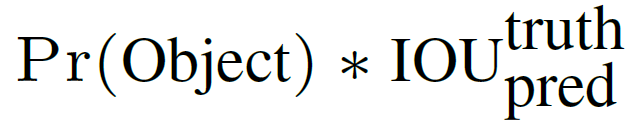
如果有object落在格子里面,第一项取1,否则取0;第二项为bbox与groundtrue 之间的IOU。
一个grid有B个bbox。每个bbox 预测5个值(x,y,h,w,confidence),每个grid 预测C个类别概率。一张图有S x S 的grid:
那么预测输出就是S x S x (5*B + C)的tensor。
因为一个grid 只有一个类别信息。所有在test 阶段,bbox 的类别置信度是将bbox的confidence * 类别信息。
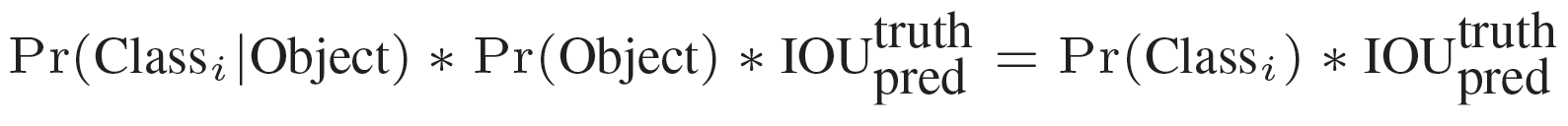 得到每个box的class-specific confidence score以后,设置阈值,滤掉得分低的boxes,对保留的boxes进行NMS处理,就得到最终的检测结果。
得到每个box的class-specific confidence score以后,设置阈值,滤掉得分低的boxes,对保留的boxes进行NMS处理,就得到最终的检测结果。
具体实现
1、监督信号构建
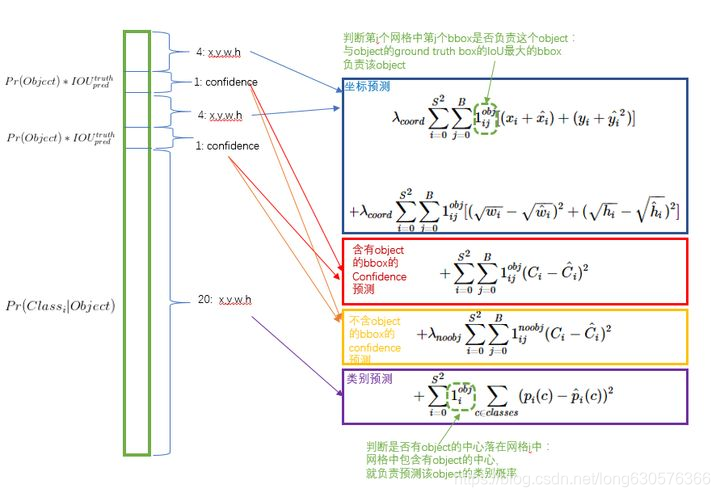
yolo 预测输出S x S x (5B + C) 。那么构建监督信号的gt shape 应该也是 S x S x (5B + C)。假设B = 2,C=20。
1、坐标归一化:其中坐标的x,y用对应网格的offset归一化到0-1之间,w,h用图像的width和height归一化到0-1之间。注意w,h是归一化到全图scale上,因为w,h大小相对原图是不限制的,而 x,y 中心点只能在grid里活动。
2、LOSS 设计
在实现中,最主要的就是怎么设计损失函数,让这个三个方面得到很好的平衡。原文用简单粗暴全部用 sum-squared error loss。但是存在问题:
第一,8维的localization error和20维的classification error同等重要显然是不合理的。
第二,如果一个网格中没有object(一幅图中这种网格很多),那么就会将这些网格中的box的confidence push到0,相比于较少的有object的网格,这种做法会导致网络不稳定甚至发散。
解决办法:
更重视8维的坐标预测,给这些损失前面赋予更大的loss weight;
对没有object的box的confidence loss,赋予小的loss weight;
有object的box的confidence loss和类别的loss的loss weight正常取1。
为了缓和大物体目标和小物体目标相同位置偏差所带来的影响。将box的width和height取平方根代替原本的height和width。也就是小物体小变化的影响要比大物体同等变化所造成的影响要大。
3、最后LOSS:

1、只有当某个网格中有object的时候才对classification error进行惩罚
2、只有当某个box predictor对某个ground truth box负责的时候,才会对box的coordinate error进行惩罚,而对哪个ground truth box负责就看其预测值和ground truth box的IoU是不是在那个cell的所有box中最大
思考
1、一个grid cell 分类预测共享,使得一个cell 不能预测多个目标。那么一个cell中多个bbox,能否将类别预测分开?
这个问题就涉及到预测分工的问题,如果一个cell 有多个目标,那么B个bbox 如何分工预测对应的目标,在yolo是无法确定的。在使用anchor 的算法里,anchor与ground truth的IOU大小来安排anchor负责预测哪个物体。
2、 既然一个gird cell 只能预测一个目标,为什么还要用B个bbox进行预测?
这个还是要从训练阶段怎么给两个predictor安排训练目标来说。在训练的时候会在线地计算每个predictor预测的bounding box和ground truth的IOU,计算出来的IOU大的那个predictor,就会负责预测这个物体,另外一个则不预测。这么做有什么好处?我的理解是,这样做的话,实际上有两个predictor来一起进行预测,然后网络会在线选择预测得好的那个predictor(也就是IOU大)来进行预测。通俗一点说,就是我找一堆人来并行地干一件事,然后我选干的最好的那个。
只选择与ground truth的IOU最大的那个边界框来负责预测该目标,而其它边界框认为不存在目标。这样设置的一个结果将会使一个单元格对应的边界框更加专业化,其可以分别适用不同大小,不同高宽比的目标,从而提升模型性能
3、confidence 如何理解?
1、训练阶段,confidence 为:
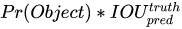
也就是:
有目标,confidence 为预测框与真值框的IOU。
无目标,confidence 直接为0。
为什么不直接取IOU呢,要乘以Pr(object)?
因为在训练过程,有些cell并没有object中心点落入,但是也会预测bbox,且与object真值IOU并不为0。而网络希望通过这种约束,使得这个cell预测的值与中心点不落在此区域的object无关。
这也就是 grid cell 只负责预测中心点落入到此处的object。中心点落入到其他grid cell 的object一律不管。
任何一个预测都要对应一个object。
为什么label不直接是1, 而是预测与真值的 IOU?
首先confidence 是针对bbox的,并不是针对grid cell。反应的是这个预测的bbox包含物体的置信度——包括是否包含物体(P(object)) + 这个bbox预测得有多准(IOU)。
目标是使训练出的模型输出的confidence无限接近真实的P(object) * iou。
如果这个栅格中不存在一个 object,即Pr(Object)=0,既然都不存在物体,自然也不存在什么IOU了,则confidence score应该为0;如果存在物体的话,则Pr(Object)=1,此时confidence score则为 predicted bounding box与 ground truth box之间的IOU(intersection over union)
如果训练过程中预测的confidence为当前的iou = 1,可是这样的话,其实训练confidence的结果就相当于边框回归了。
测试阶段:
测试阶段输出的confidence 已经隐含包含了。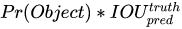
3、类别预测如何理解?
1、对于训练阶段,也就是打label阶段,怎么打label呢?对于一个cell,如果物体的中心落在了这个cell,那么我们给它打上这个物体的类别label,并设置概率为1。换句话说,这个概率是存在一个条件的,这个条件就是cell存在物体。
2、对于测试阶段来说,网络直接输出 [公式] ,就已经可以代表有物体存在的条件下类别概率。但是在测试阶段,作者还把这个概率乘上了confidence。
总结:
YOLO V1 是一阶段的开篇。主要是为了提高速速而生的,也必然舍弃了精度和准召。
缺点:
1、因为边框 h,w 在全图上回归,精度较差;V2 上用anchor解决。
2、由于一个cell 只负责预测一个物体,对于小目标和密集小物体检测不是很好,例如群鸟;
3、YOLO 格子中大部分是背景类,可以降低误检,但是召回率比较低;
后续针对YOLO V1的优化继续更新 YOLO V2 YOLO V3 等。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









