




 本周笔记涵盖了C/C++基本类型、Python列表操作、Pandas实用技巧、内存管理、二叉搜索树、Colab与Github优化、算力租赁、Python表达式、Jupyter快捷键、word2vec与embedding、Gensim、面向对象编程、Sklearn库、数据处理与竞赛技巧,还包括matplotlib、热力图、特征选择与评估等多个主题。
本周笔记涵盖了C/C++基本类型、Python列表操作、Pandas实用技巧、内存管理、二叉搜索树、Colab与Github优化、算力租赁、Python表达式、Jupyter快捷键、word2vec与embedding、Gensim、面向对象编程、Sklearn库、数据处理与竞赛技巧,还包括matplotlib、热力图、特征选择与评估等多个主题。
周学习笔记(2021.7.12-2021.7.18)
7.12
1. typedef
用途:声明新的类型名,来代替原有类型名,但不生成新的类型
(1)C
typedef struct node{
int a;
}Node;
表示Node可以替代 struct node 声明变量
Node node1 <=> struct node node1
也可以不写 node
typedef struct{
int a;
}Node;
声明变量只能是Node node1
(2)C++
结构体定义
struct Student{
int a;
};
声明变量 Student stu1
如果使用typedef
struct Student{
int a;
}stu1;//结构体变量
typedef struct Student{
int a;
}stu2;//结构体类型,即别名
2. python 列表
1.列表去重可直接变成集合,但是集合变成列表不能直接list()
list_unique=set(list)
2.添加元素
拿新元素类型为列表举例
list.append() #直接添加
list.expend() #扩展列表

3.列表生成式
先写新列表中元素的格式
然后写for循环对元素施加限制
也可以有if 或者双层循环,先写的是外循环,后写的是内循环
list2 = [x for x in list1 if x != []] #删除列表中的空列表元素
4.其他
生成指定个数的全零列表
values=[0]*len(keys)
两个列表生成字典
dic=dict(zip(keys,values))
拓:zip()的用法
参数iterable为可迭代的对象,并且可以有多个参数。该函数返回一个以元组为元素的列表,其中第 i 个元组包含每个参数序列的第 i 个元素。返回的列表长度被截断为最短的参数序列的长度。只有一个序列参数时,它返回一个1元组的列表。没有参数时,它返回一个空的列表。
import numpy as np
a=[1,2,3,4,5]
b=(1,2,3,4,5)
c=np.arange(5)
d="zhang"
zz=zip(a,b,c,d)
print(list(zz))
输出:
[(1, 1, 0, 'z'), (2, 2, 1, 'h'), (3, 3, 2, 'a'), (4, 4, 3, 'n'), (5, 5, 4, 'g')]
import numpy as np
zz=zip()
print(list(zz))
输出:[]
import numpy as np
a=[1,2,3]
zz=zip(a)
print(list(zz))
输出:[(1,), (2,), (3,)]
import numpy as np
a=[1,2,3]
b=[1,2,3,4]
c=[1,2,3,4,5]
zz=zip(a,b,c)
print(lits(zz))
输出:[(1, 1, 1), (2, 2, 2), (3, 3, 3)]
5.删除元素
del 按下标删除
li = [1, 2, 3, 4]
del li[3]
print(li)
# Output [1, 2, 3]
list.pop()按值删除,无参数则默认删除最后一个值
li = [1, 2, 3, 4]
li.pop(2)
print(li)
# Output [1, 2, 4]
切片删除
li = [1, 2, 3, 4]
li = li[:2] + li[3:]
print(li)
# Output [1, 2, 4]
删除首个出现的数字
li = [3,1, 2, 3, 4]
li.remove(3)
print(li)
# Output [1, 2, 3,4]
3. pandas 操作
-
pd.describe()时会出现科学计数法,加一行
pd.set_option('display.float_format', lambda x: '%.2f' % x) #保留两位小数,直观显示数字 -
读写文件
df=pd.read_csv('test.csv','r',encoding=utf-8) #.txt文件也可 df.to_csv('文件名') -
涉及 dataframe
a=pd.Series(len_list) b=pd.Series(count_para) c=pd.DataFrame({'各段句数':a,'各段词数':b}) -
iloc 和 loc
-
df.info() 中当没有明确指定类型的话,所有的数据都可以是object类型,object类型也可看作是catogory类型
-
series变为list
sentences = data['tagid'].values.tolist() -
读入无表头的文件,并自定义表头
headers=['','','','','']
df=pd.read_csv('.csv',header=None,names=headers)
-
“如果只关注category 类型的数据,其实根本没有必要拿到这些全部数据,只需要将object类型的数据取出,然后进行后续分析即可”
obj_df = df.select_dtypes(include=['object']).copy()感慨怎么这么多封装好的API,方便但是记不住呀(抱头
DataFrame.select_dtypes(include=None, exclude=None)
4. python 其他
-
变量命名规则
数字、字母、下划线,不能以数字开头
驼峰式
-
.copy()
在python中,对象赋值实际上是对象的引用。当创建一个对象,然后把它赋给另一个变量的时候,python并没有拷贝这个对象,而只是拷贝了这个对象的引用。若对初始变量进行改变,普通的等号会让关联的变量发生相同的改变,所以要使用.copy()
-
无 ++ 和 – 符号
C++中的自增自减操作本质是改变的对象本身
但是,在python中规定数值对象是不可改变的也就是说在进行 i = i + 1 操作时,相当于创建了一个新的 i , 而不是改变 i 中的值。
5. malloc() & new()
(1)malloc() C
头文件 malloc.h
用途:动态内存分配
申请一块连续的指定大小的内存块区域以void*类型返回分配内存区域地址
任何指针都可以赋值给void指针,但void指针赋值给其他类型的指针时都要进行转换
申请的内存需要free,否则会造成内存泄漏
malloc 只管分配内存,并不能对所得的内存进行初始化,所以得到的一片新内存中,其值将是随机的
typedef struct LNode *List;
struct LNode {
ElementType Data[MAXSIZE];
Position Last; /* 保存线性表中最后一个元素的位置 */
};
p = (List)malloc(sizeof(struct LNode));
//同 p=(struct LNode*)malloc(sizeof(struct LNode));
补充 sizeof() 不是函数
#include<stdio.h>
int main(){
int a = 10; //4
char b = 'b'; //1
short c = 2; //2
long d = 9; //4
float e = 6.29f; //4
double f = 95.0629; //8
int arr[] = { 1,2,3 }; //12 (3x4)
char str[] = "hello"; //6(包括换行符)
double *p=&f; //8
int *i=&a; //8
//分别对各个变量使用sizeof运算
printf("a=%d,b=%d,c=%d,d=%d,e=%d,f=%d,arr=%d,str=%d point_p=%d,point_i=%d\n",
sizeof(a), sizeof(b), sizeof(c), sizeof(d), sizeof(e), sizeof(f),
sizeof(arr), sizeof(str), sizeof(p), sizeof(i));
return 0;
}
指针变量,本身存储大小,32位环境4位,64位则8位,与指针类型无关
(2)new() C++
无需头函数,需要delete()
包括评论区的一些点
“malloc是面向内存的,你要开多大,就给你开多大,开了就不管了。new是面向对象的,根据你指定的数据类型来申请对应的空间,并且能够直接内部调用构造函数生成对象。”
“有了malloc,为什么还要有new?设计者设计new的原因是为什么?——因为对于非内部数据类型而言,malloc/free无法满足动态对象的要求。对象在创建时需要自动执行构造函数,在消亡之前需要自动执行析构函数。由于malloc/free是库函数而不是操作符,不在编译器控制权限之内,不能把执行的构造函数和析构函数强加于malloc/free,所以有了new/delete。”
“堆是一个实际的区域,而自由存储区是一个更上层的概念。通常new确实是在堆上申请内存,但是程序员可以自己重载new操作符,使用其他内存来实现自由存储(这并不常见)。另外,c++ primer plus这本书上有提到布局new,可以为对象在栈上分配内存。总的来说,自由存储区是new申请的区间的概念。”
6. 二叉搜索树
左结点的值<根结点的值<右结点的值
可以关联到二分查找
7.13
1. Colab
为啥会有两只柯基乱入==


为了保证计算资源的自动分配,Colab 中的可用 GPU 类型是动态变化的,通常包括 Nvidia K80(3.7)、T4(7.5)、P4 (6.1)和 P100(6.0)。
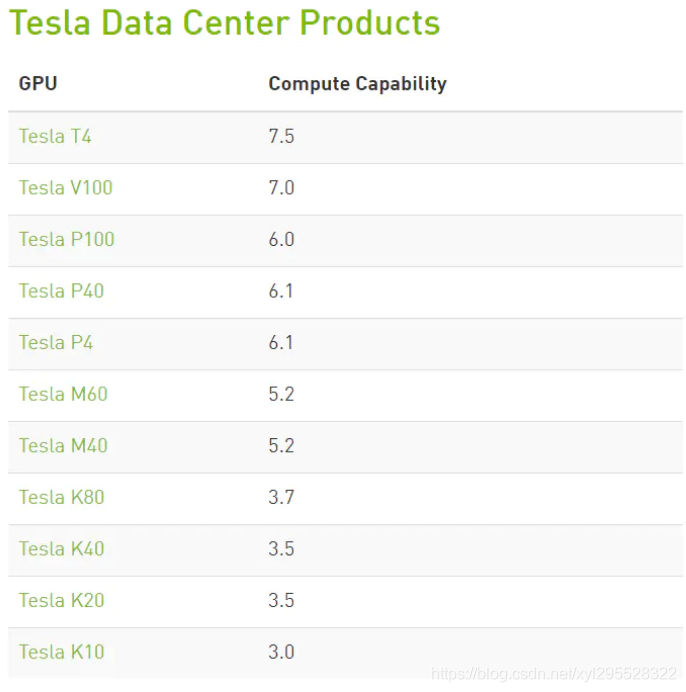
查看显卡驱动信息
! nvidia-smi
科普
显卡接在电脑主板上,它将电脑的数字信号转换成模拟信号让显示器显示出来。
Nvidia 是一家人工智能计算公司
CPU适合串行计算,擅长逻辑控制
GPU擅长并行高强度并行计算,适用于AI算法的训练学习
CUDA 是NVIDIA专门负责管理分配运算单元的框架
cuDNN是用于深层神经网络的gpu加速库
重点
不要直接上传文件
将数据文件上传到Google Drive中,使用如下代码挂载Google Drive读取数据,这样不会存在数据丢失的情况。
from google.colab import drive
drive.mount('/content/gdrive')
!ls
代码运行后在下方会出现链接,点击链接登录会出现验证码,复制粘贴到方框内便能在文件目录下挂载Google Drive文件夹,读取数据。
以下from 机器之心

2. github 访问慢可以加速
添加插件解决——github加速
3. 算力租赁
发现一个可以租算力的网站https://featurize.cn/?s=727e6c813a9c44dfb8fd8db7981c373a,有需要再说吧
4. python eval()
将字符串对象转换为具体对象,也可以进行计算
a = "[[1, 2], [3, 4], [5, 6]]"
b = eval(a)
print(b) #[[1,2],[3,4],[5,6]]
type(b) #list
a = "{1: 'a', 2: 'b'}"
b = eval(a)
print(b) #{1:'a',2:'b'}
type(b) #dict
a = "11 + 12"
b = eval(a) #23
print(b)
5. jupyter notebook 快捷键
参考:Jupyter Notebook 快捷键 - 朱卫军的文章 - 知乎 https://zhuanlan.zhihu.com/p/72845636
命令模式,键盘输入运行程序命令;这时的单元框线是灰色。
esc 转命令模式
YM互相转化,Y代码模式,M注释模式
ctrl+enter运行代码框
enter 转编辑模式
shift+K 扩大选中上方单元
shift+J 扩大选中下方单元
A 在上方插入新单元
B 在下方插入新单元
D 删除选中的单元
编辑模式,允许你往单元中键入代码或文本;这时的单元框线是绿色的。
附:anaconda &jupyter notebook 科普
6.lambda()
lambda 是python 中预留的关键字
lambda[arg1[,arg2,…argn]]:expression 参数列表和参数表达式
输入是传入到参数列表argument_list的值,输出是根据表达式expression计算得到的值
拥有自己的命名空间
7.14
1. word2vec
将某个单词用特定的向量来表示,词向量主要有两种形式,稀疏向量和密集向量
(1)稀疏向量one-hot representation
用一个很长的向量来表示一个词,向量的长度为词典的大小N,向量的分量只有一个1,其他全为0,1的位置对应该词在词典中的索引
优点:不需要繁琐的计算,简单易得
缺点:长度过长,会引发维数灾难;无法表示出近义词之间的关系(任意向量正交结果为0)
博客中提到“用这种稀疏向量求和来表示文档向量效果还不错,清华的长文本分类工具THUCTC使用的就是此种表示方法”
THUCTC(THU Chinese Text
Classification)是由清华大学自然语言处理实验室推出的中文文本分类工具包,能够自动高效地实现用户自定义的文本分类语料的训练、评测、分类功能。文本分类通常包括特征选取、特征降维、分类模型学习三个步骤。如何选取合适的文本特征并进行降维,是中文文本分类的挑战性问题。我组根据多年在中文文本分类的研究经验,在THUCTC中选取二字串bigram作为特征单元,特征降维方法为Chi-square,权重计算方法为tfidf,分类模型使用的是LibSVM或LibLinear。THUCTC对于开放领域的长文本具有良好的普适性,不依赖于任何中文分词工具的性能,具有准确率高、测试速度快的优点。
(2)密集向量distributed representation
即分布式表示。最早由Hinton提出,可以克服one-hot representation的上述缺点,基本思路是通过训练将每个词映射成一个固定长度的短向量,所有这些向量就构成一个词向量空间,每一个向量可视为该空间上的一个点**[1]**。此时向量长度可以自由选择,与词典规模无关。
可表示近义词之间的关系(正交结果不一定为0)


用到了hs参数,不太懂,了解了一下
找到两篇博客,晚点消化
hierarchica softmax
nagative sampling
2. embedding
归纳:矩阵降维升维,利用共同特征构建两句话之间的关系
3. Gensim
Gensim是一款开源的第三方Python工具包,用于从原始的非结构化的文本中,无监督地学习到文本隐层的主题向量表达。
使用gensim训练word2vec
from gensim.models.word2vec import Word2Vec
model = Word2Vec(sentences, workers=num_workers, size=num_features)
word2vec的实现是位于gensim包中gensim\models\word2vec.py文件里面的Word2Vec类中
4. python 面向对象
内部类相当于外部类的属性
使用内部类定义实例对象的时候,都必须在内部类的类名前加一个外部类的实例名
5. np.mean()
np.mean(a,axis)
- axis 不设置值,对 m*n 个数求均值,返回一个实数
- axis = 0:压缩行,对各列求均值,返回 1* n 矩阵
- axis =1 :压缩列,对各行求均值,返回 m *1 矩阵
6. sklearn 库
(1) classification
-
SGD Classifier
-
Linear SVC
-
kernel approximation
-
KNeighbors Classifier
-
SVC
-
Ensemble Classifiers
-
Naive Bayes
(2)clustering
- KMeans
- Spectral Clustering
- GMM
- MiniBatch KMeans
- MeanShift
- VBGMM
(3)regression
- SGD Regressor
- Lasso ElasticNet
- SVR(kernel=‘rbf’)
- RidgeRegression
- SVR(kernel=‘linear’)
(4)dimensionality reduction
- Randomized
- Isomap
- Spectral Embedding
- LLE
- kernel approximation
7. python 相关 import
(1)Tqdm 是一个快速,可扩展的Python进度条,可以在 Python 长循环中添加一个进度提示信息,用户只需要封装任意的迭代器 tqdm(iterator)。
from tqdm import tqdm
(2)
import warnings
warnings.filterwarnings("ignore")
8. type()&dtype()&astype()

9. 竞赛常用代码积累
填充缺失值、特征处理等操作时train和test放在一起,
data = pd.concat([train, test])
处理完后再根据标签是否为空分开
X_train = data[~data['label'].isna()]
X_test = data[data['label'].isna()]
isna()/isnull()
返回布尔值,检测元素值是否为NAN
两个baseline提交代码
test['pre'] = pre
test['pre'] = test['pre'].apply(lambda x:1 if x>0.5 else 0)
sub = test[['pid','pre']]
sub = sub.rename(columns=({'pid':'user_id','pre':'category_id'})) #dataframe.rename()
sub.to_csv('sub.csv',index=False)
X_test['category_id'] = [1 if i >= 2.5 else 0 for i in predictions_lgb]
X_test['user_id'] = X_test['pid']
X_test[['user_id', 'category_id']].to_csv('base_sub.csv', index=False)
10. StratifiedKFold & Kfold
StratifiedKFold用法类似Kfold,但是他是分层采样,确保训练集,测试集中各类别样本的比例与原始数据集中相同
11. pandas操作
(1)用pandas读写csv文件的index和columns细节问题
dataframe 这个类型的对象就是一个有行index和列name的数据结构,写入时默认是保存的
参数index=False 表示不写入序列
pandas在读取csv文件时,不会去管原来的csv中是否存在index,而在于在读取的时候是否有设置index。如果读取的时候不设置index,那么系统会默认生成自然序列的index
(2)只写入几列
df.to_csv(‘文件名’,columns=[])
只读入几列
data=pd.read_csv(‘文件名’,usecols=[])
(3)读取csv后转为list
import pandas as pd
data_df = pd.read_csv("test.csv", names=["a", "b", "c", "d"], encoding="utf-8-sig")
print(data_df)
data = data_df.values.tolist()
print(data)
结果:
a b c d
0 1 2 3 NaN
1 4 5 6 7.0
2 8 9 10 NaN
[[1.0, 2.0, 3.0, nan], [4.0, 5.0, 6.0, 7.0], [8.0, 9.0, 10.0, nan]]
12. LightGBM
import lightgbm as lgb
LightGBM是个快速的,分布式的,高性能的基于决策树算法的梯度提升框架。可用于排序,分类,回归以及很多其他的机器学习任务中。
13. python print()换行输出
print()函数中参数end=’ ‘默认为\n,所以会自动换行
如果不想换行,可以修改end里面的值
14. LabelEncoder
from sklearn.preprocessing import LabelEncoder
data = pd.read_csv(pathUtils.train_path,engine='python')
encoder= LabelEncoder().fit(data["job"])
data["job"] = encoder.transform(data["job"])

15. 特征重要性(1)
用在树模型上,筛选特征
利用matplotlib 对特征重要性进行了可视化处理
feature_importance = clf.feature_importances_
def plot_feature_importances(feature_importances, title, feature_names):
feature_importances = 100 * (feature_importances / max(feature_importances))
#按特征重要性进行排序
index_sorted = np.flipud(np.argsort(feature_importances))
pos = np.arange(index_sorted.shape[0]) + 0.8
plt.figure()
plt.bar(pos, feature_importances[index_sorted], align = 'center')
plt.xticks(pos, np.array(feature_names)[index_sorted])
plt.ylabel('Relative Importance')
plt.title(title)
plt.show()
plot_feature_importances(feature_importance, 'Feature importances', feature_names)
7.15
1. sns.heatmap热力图
热力图,又名相关系数图。根据热力图中不同方块颜色对应的相关系数的大小,可以判断出变量之间相关性的大小。
sns.heatmap(df2.corr(),annot=True,vmax=1,square=True,cmap='Reds')
df2.corr() # 你的df2数据集的相关系数矩阵
annot=True # 绘制的热力图中 每个单元格标记对应的相关系数值 (显示数值)
vmax=1 # vmax指代颜色最深表示的最大相关系数值,超过这个相关系数值的色块表现为同一颜色
square=True # 参数为True确保绘制的热力图每个小色块为方形,False不做限制
cmap=‘Reds’ # 整体色系为红色系,也可以替换为Blues Greens
data=df2.corr()
如果是numpy二维数组,用行标标记;如果是DataFrame,就用列名标记
2. 训练集和测试集分布不一致(检验+解决)
(1)检验
通过绘制概率密度图(kdeplot)来查看特征的分布,也可以通过对抗验证的方法进行特征的筛选
(2)解决
利用可视化查看训练集和测试集该特征的的分布情况,总之要用符合测试集分布的数据训练模型
3. 验证集(开发集)
测试集是没有参与模型训练和参数调整的,只是用来测试模型泛化能力
随机采样适合于大量数据集和目标值分布均匀的情况,但如果正负样例分布不均匀,则需要分层采样划分数据集
“在训练模型时参数可以分为两种,一种是普通的模型参数,一种是需要人工调参的超参数,我们都知道普通参数的训练使用的是训练集的数据,验证集的数据并没有参与,因此可以用来进行评估。但实际上,我们在人工选择超参数,并使用验证集来决定最终使用哪组超参数的过程,也可以看作验证集参与了超参数的训练过程,因此我们还需要一个完全没有参与过所有参数训练的测试集来作为最终的结果评估。” from 知乎陈阿土
最后,竞赛中会提供测试集,训练集只分成训练集和验证集就行,不太需要额外划分测试集,因为在同一个训练集中数据分布大致相同
4. 目标属性与非目标属性相关性
在分析特征间相关性时,常使用的方法是 pandas.DataFrame.corr :
DataFrame.corr(self, method=’pearson’, min_periods=1)
参数说明:(其值范围-1到+1)
- pearson:Pearson相关系数
- kendall:Kendall秩相关系数
- Spearman:Spearman等级相关系数
使用皮尔森相关系数的缺点
- 判断的是两个特征的线性关系
- 没法同时适用于类别变量和数值变量的关系计算
- 相关性系数矩阵是对称的,而在许多问题中我们特征变量之间的关系并不一定是对称的
解决方法——预测能力得分

PPS使用实例(纵对横的关系)
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import ppscore as pps
df = pd.read_excel("data/train.xlsx")
plt.figure(figsize=(15, 13))
matrix_df = pps.matrix(df)[['x', 'y', 'ppscore']].pivot(columns='y', index='x', values='ppscore')
sns.heatmap(matrix_df, annot=True, vmin=0, vmax=1, cmap='Blues', fmt=".2f") # fmt表示规范数值,当前保留两位
plt.title("Predictive Power Score")
plt.savefig('corr_pps.png')

PPS可能不准确,但其目的不是给出准确的分数,而是给出两个变量之间的依存关系和快速结果的一般概念。
5. 数据竞赛AB榜
国内数据竞赛AB榜,提交到比赛评测口显示的是A榜成绩,当比赛结束后展示的是B榜成绩
如果A榜分数很高,但B榜分数很低,则是由于过拟合
B榜也相当于复赛
6. shuffle 数据
在训练之前,一般均会对训练集做shuffle,打乱数据之间的顺序,让数据随机化,这样可以避免过拟合。
7. df.dropna()
DataFrame.dropna(axis=0,how=’any’,thresh=None,subset=None,inplace=False)
#等同于df.dropna()
axis 默认为0,即按行删除;axis=1 即按列删除
how=any 删除含有NAN 的行/列,how=all 删除全为NAN的行/列
inplace表示是在原df上修改,还是拷贝一份
subset 删除特定列中含有缺失值的行/列
8. 键盘快捷键
home 全屏减少干扰,退出全屏再按一次
9. MAE &RMSE & MSE
回归算法的一些评价指标
- MAE 平均绝对误差(mean absolute error)

-
MSE 均方误差(mean squared errror)——指参数估计值与参数真值之差平方的期望值;

-
RMSE 均方根误差 ( root mean squared error) 对异常值敏感——是均方误差的算术平方根

10. np.random.uniform()
函数原型: numpy.random.uniform(low,high,size)
功能:从一个均匀分布[low,high)中随机采样,注意定义域是左闭右开,即包含low,不包含high.
参数:
- low: 采样下界,float类型,默认值为0;
- high: 采样上界,float类型,默认值为1;
- size: 输出样本数目,为int或元组(tuple)类型,例如,size=(m,n,k), 则输出mnk个样本,缺省时输出1个值。
返回值:ndarray类型,其形状和参数size中描述一致。
11. 随机种子
随机种子就是随机数的初始值,可用于保证结果的可重复性
np.random.seed(0)
7.16
1. python range()
不写左端默认从零开始
左闭右开
函数原型:range(start, end, scan):
最后一个参数表示间隔
7.17
1. matplotlib.pyplot
导入matplotlib是导入_init_.py 文件,而导入matplotlib.pyplot是导入matplotlib包下的pyplot.py文件
考察单个变量的均值、中位数、众数、分位数、方差、变异系数等
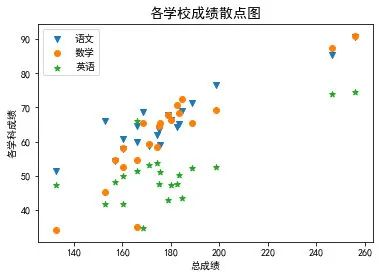
- plt.scatter() 散点图
# 绘制各学科成绩散点图
plt.figure(figsize=(6,4)) #设计画布大小
plt.scatter(data1["总分"],data1["语文"],marker='v')
plt.scatter(data1["总分"],data1["数学"],marker='o')
plt.scatter(data1["总分"],data1["英语"],marker='*')
plt.title("各学校成绩散点图",fontsize = 14)
plt.xlabel("总成绩")
plt.ylabel("各学科成绩")
plt.legend(["语文","数学","英语"]);
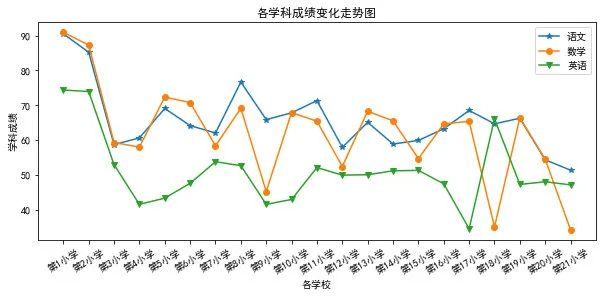
- plt.plot() 折线图
plt.figure(figsize=(10,4))
plt.plot(range(21),data1.iloc[:,1],'-*') #选取语文成绩数据
plt.plot(range(21),data1.iloc[:,2],'-o') #选取数学成绩数据
plt.plot(range(21),data1.iloc[:,3],'-v') #选取英语成绩数据
plt.title('各学科成绩变化走势图')
plt.xlabel('各学校')
plt.ylabel('学科成绩')
plt.xticks(range(21),data1["学校"],rotation=30) #rotation=30控制文字倾斜角度
plt.legend(['语文','数学','英语']);
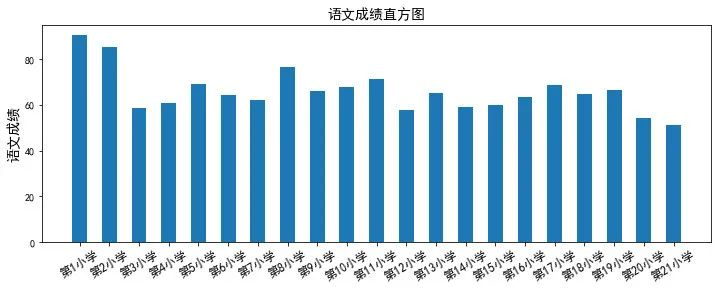
-
plt.bar() 直方图
直方图包含更多关于分布形状的信息——是高斯分布、均匀分布还是多模态分布
yw = data1.loc[:,"学校":"语文"] #提取数据绘制直方图,直方图原理,每个需要被画图的标签对应一个数值
yw = yw.T
yw.columns = yw.iloc[0] #将学校字段转换成列索引
yw1 = yw.drop("学校",axis=0) #删多余的行信息
# 每个学校语文平均成绩的直方图
plt.figure(figsize=(12,4))
plt.bar(range(21),yw.loc["语文",:],width=0.5)
plt.title("语文成绩直方图",fontsize = 14)
plt.ylabel("语文成绩",fontsize = 14)
plt.xticks(range(21),yw.iloc[0],rotation=30,fontsize = 12); #x轴刻度为各学校名称
# 将多个学科成绩画到一张图中 #截取前十
data2.plot.bar(x = '学校',y = ['语文','数学','英语'],figsize=(16,6),width=0.7,rot = 30,title = "各学科成绩直方图"); #rot空值标签倾斜程度
-
plt.pie() 饼图
-
plt.boxplot() 箱型图
几大要素
内限、中位数、上四分位数、下四分位数、异常值
下四分位数:一般使用(n+1)/4,即四分之一分位数即第(n+1)/4个数
上四分位数:一般使用(n+1)/4*3,即四分之三分位数即第(n+1)/4*3个数
内限:上面的T形线段所延伸到的极远处,是Q3+1.5IQR(其中,IQR=Q3-Q1),下面的T形线段所延伸到的极远处,是Q1-1.5IQR。
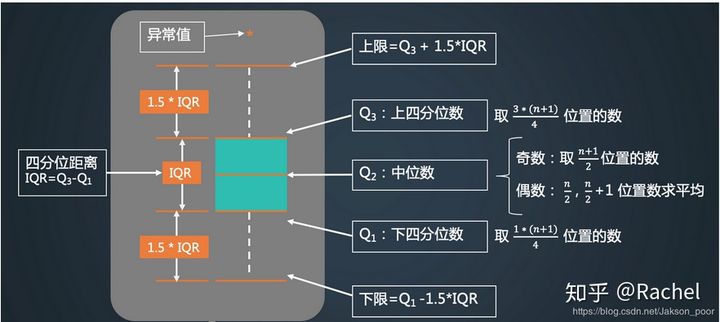
- 小提琴图
2. 数据分析常用语句
data.isnull().sum() #查看缺失值情况
3. groupby()
data1=data.groupby('性别')['身高'].内置函数 # 按照性别分组,统计身高信息

7.18
1. 直方图vs柱状图
(1)直方图纵轴是频数,有助于我们知道数据的分布情况,诸如众数、中位数的大致位置、数据是否存在缺口或者异常值,可以和密度图相互转化;柱状图纵轴是大小
直方图展示的是一组数据中,在你划分的区间里,这些数据的分布情况,但是我们不知道在一个区间里,单个数据的具体大小。下图展现了游客在博物馆的游览时间,其中,将近40%的游客仅逗留了0-10分钟。但是我们无法知道这些游客中,每个人具体的游览时间是多少。
而在柱状图里,我们能看到的是每个数据的大小,并且进行比较。下图就比较了在12次展览中,参观者参观时间的中位数,我们能够知道参观的具体用时。
(2)直方图X轴为定量数据,柱状图X轴为分类数据。
在直方图中,X轴上的变量是一个个连续的区间,这些区间通常表现为数字,例如代表苹果重量的“0-10g,10-20g……”,代表时间长度的“0-10min,10-20min……”。而在柱状图中,X轴上的变量是一个个分类数据,例如不同的国家名称、不同的游戏类型。
直方图上的每根柱子都是不可移动的,X轴上的区间是连续的、固定的。而柱状图上的每根柱子是可以随意排序的,有的情况下需要按照分类数据的名称排列,有的则需要按照数值的大小排列。
(3)直方图柱子无间隔,柱状图柱子有间隔
因为直方图中的区间是连续的,因此柱子之间不存在间隙。而柱状图的柱子之间是存在间隔。
(4)直方图柱子宽度可不一,柱状图柱子宽度须一致
柱状图柱子的宽度因为没有数值含义,所以宽度必须一致。但是在直方图中,柱子的宽度代表了区间的长度,根据区间的不同,柱子的宽度可以不同,但理论上应为单位长度的倍数。
2. 变异系数
3. 监督学习的假设
正负样本要平衡且训练集和测试集样本是独立同分布的
4. iloc & loc
5. Gini系数
Gini(D)反映了从数据集D中随机抽取两个样本,其类别标记不一致的概率(二分类)
因此,Gini(D)越小, 则数据集D的纯度越高
在选择划分属性时,选择那个使划分后Gini系数最小的属性作为最优划分属性
6. 对抗验证
对抗验证中,哪个特征重要性越高,则该特征在训练集和测试集分布不一致
对抗验证中,增设一列判断是否为测试集,然后训练集和测试集合并作为训练数据喂给模型,用训练集作为预测数据,概率高的可以在后续作为验证集,而不要交叉验证,另外对于单拿出来的验证集可以赋予一定的权重
7. np.argsort() & np.sort()
(1) np.sort()[::-1] 降序排列
(2)np.sort()[::1] 升序排列
(3)np.argsort()[::-1] 降序排序后返回索引值
(4)np.argsort()[::1] 升序排序后返回索引值
8. 结构化、非结构化、半结构化数据
3. 监督学习的假设
正负样本要平衡且训练集和测试集样本是独立同分布的
4. iloc & loc
5. Gini系数
Gini(D)反映了从数据集D中随机抽取两个样本,其类别标记不一致的概率(二分类)
因此,Gini(D)越小, 则数据集D的纯度越高
在选择划分属性时,选择那个使划分后Gini系数最小的属性作为最优划分属性
6. 对抗验证
对抗验证中,哪个特征重要性越高,则该特征在训练集和测试集分布不一致
对抗验证中,增设一列判断是否为测试集,然后训练集和测试集合并作为训练数据喂给模型,用训练集作为预测数据,概率高的可以在后续作为验证集,而不要交叉验证,另外对于单拿出来的验证集可以赋予一定的权重
7. np.argsort() & np.sort()
(1) np.sort()[::-1] 降序排列
(2)np.sort()[::1] 升序排列
(3)np.argsort()[::-1] 降序排序后返回索引值
(4)np.argsort()[::1] 升序排序后返回索引值

















 2699
2699

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









