







 本文详细介绍了Go语言字典的使用,包括基本操作、内存模型、查找数据的过程、扩容缩容策略以及迭代遍历的注意事项。通过分析字典的底层结构,帮助读者深入理解Go语言字典的工作原理。
本文详细介绍了Go语言字典的使用,包括基本操作、内存模型、查找数据的过程、扩容缩容策略以及迭代遍历的注意事项。通过分析字典的底层结构,帮助读者深入理解Go语言字典的工作原理。
往期精选(欢迎转发~~)
3.1 基本用法
字典属于引用类型,初始化方式主要有2种,分别为:
m1 := make(map[string]int)m2 := map[string]int {"lvmenglou": 32,"litinajie": 28,}
字典是被设计成“not addressable”,所以不能直接修改value成员,如果需要修改value成员,需要对元素整体替换:
type user struct {name stringage byte}m := map[int]user {1: {"lvmenglou": 32}}m[1].age += 1 // 错误:cannot assign to m[1].age
不能对nil字典进行写操作,否则会触发panic,但是可以读。
var m map[string]intm["a"] = 1 // panic: assignment to entry in nil map
nil与空字典,这个需要注意:
var m1 map[string]int // nil字典m2 := map[string]int{} // 空字典,不等于nil
map属于非线程安全,如果多个线程同时对一个map进行读、写、删除操作,会触发panic,可以使用支持线程安全的sync.Map。
3.2 内存模型
先看一下map的数据结构:
type hmap struct {count intB uint8 // bucket的数量是2^B, 最多可以放 loadFactor * 2^B 个元素,再多就要 hashGrow 了hash0 uint32 // hash seedbuckets unsafe.Pointer //2^B 大小的数组,如果 count == 0 的话,可能是 niloldbuckets unsafe.Pointer // 扩容的时候,buckets 长度会是 oldbuckets 的两倍,只有在 growing 时候为空。// 其它省略...}type bmap struct {topbits [8]uint8keys [8]keytypevalues [8]valuetypepad uintptroverflow uintptr}
B是map的bmap数组长度的对数,每个bmap里面存储了kv对,buckets是一个指针,指向实际存储的bmap数组的首地址,存储结构如下图:
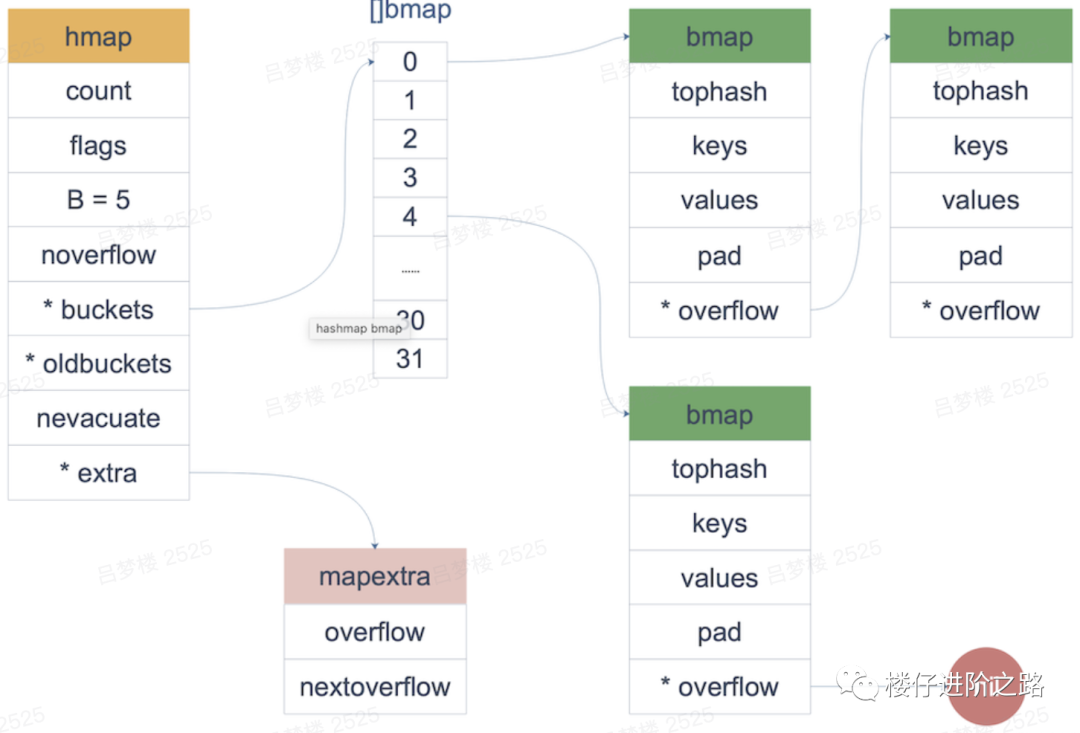
每个bmap里面最多存储 8 个key,下图是bmap的内存模型,HOB Hash 指的就是top hash字段,每个 bucket 设计成最多只能放 8个key-value对,如果有第9个key-value落入当前的bucket,那就需要再构建一个bucket ,通过overflow指针连接起来(可以查看上图)。

3.3 查找数据
key经过哈希计算后得到哈希值,哈希值是64个bit 位(针对64位机),假如一个 key 经过哈希函数计算后,得到的哈希结果是:
10010111 | 000011110110110010001111001010100010010110010101010 │ 01010其中最后5位是01010,值为10,表示10号桶。最前面8位10010111,值是151,用来在bmap中找数据用的,详见下图:
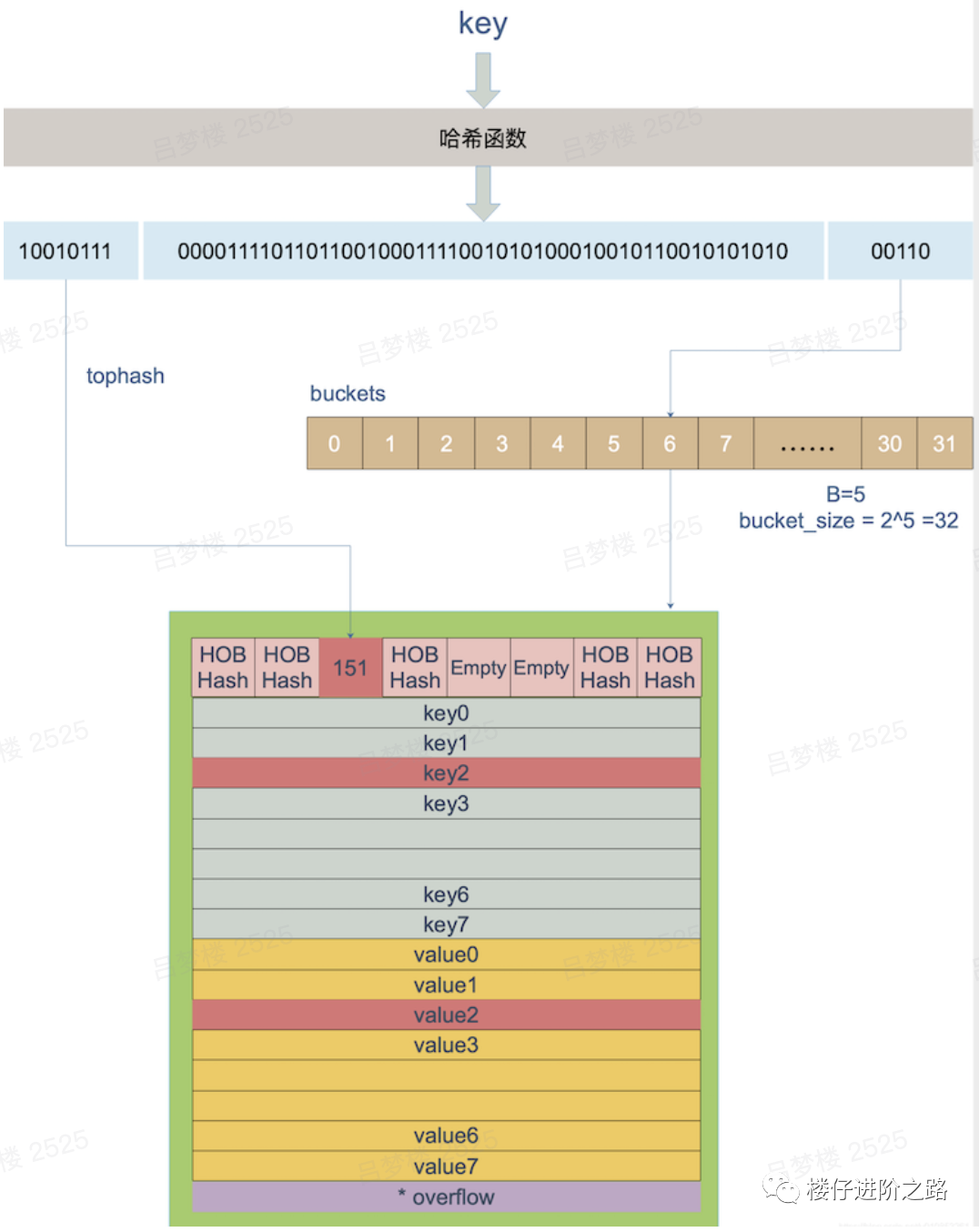
3.4 扩容缩容
一个map最多只能装8*2^B个数据,当数据量快满时,为了减少查询Hash冲突,就需要进行扩容。当bucket数量过多,然后数据又非常少时,就需要进行缩容(之前情况一般出现在数据大量删除的情况)。判断需要扩容和缩容的临界值,需要引入“装载因子”,感兴趣的同学可以自行百度。
当进行扩容时,比如B=5扩容到B=6,最低位需要扩到6位,然后重新Hash,找到在[]bmap对应的hash值,最高位不变。缩容的话,就是相反的方式。(因为最低位的第6位是0或者1,所以第6位为0的数据,因为值不变,所以不会重新进行Hash,第6位为1的数据,需要被Hash到扩容后的桶中)

为了更好举例,扩容前B=2,共有4个bmap,示例图如下:
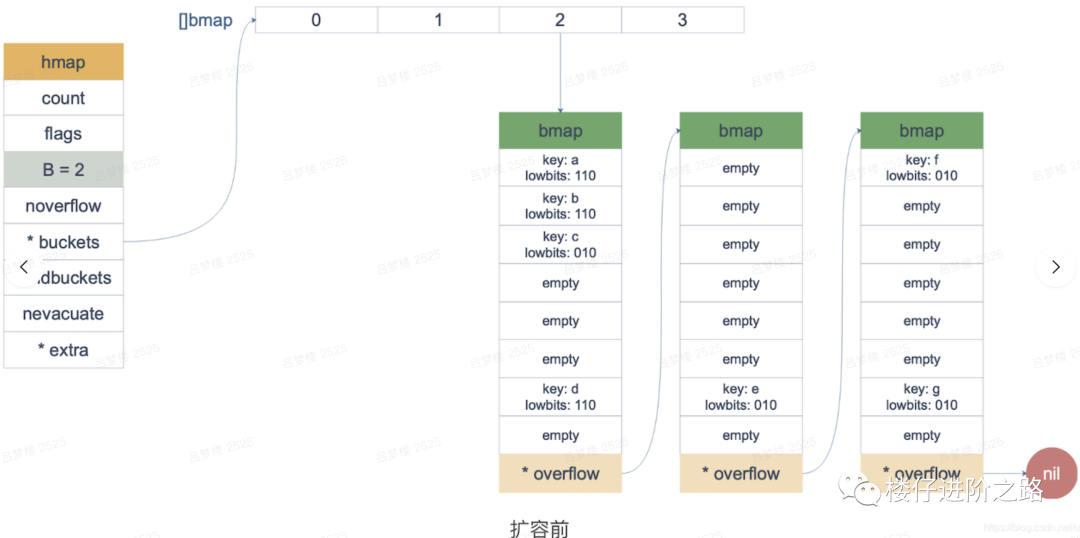
假设overflow太多,触发了等量扩容,需要将数据变得更紧凑,操作如下:

假设针对上面情况,触发了2倍扩容,将B=2扩容到B=3,操作如下:

3.5 迭代遍历
本来map的遍历过程比较简单:遍历所有的bucket以及它后面挂的overflow bucket,然后挨个遍历 bucket中的所有 cell。每个bucket中包含8个cell,从有key的cell中取出 key和value,完成遍历。但是遍历如果发生在扩容的过程中,就会涉及到遍历新老 bucket 的过程。
所以在遍历过成功,如果map在库容,需要对新旧数据同时进行遍历,下面是扩容过程示例,图中进行二倍扩容后,*oldbuckets中的1已经全部搬迁到了*buckets中,所以遍历时,需要对*oldbuckets和*buckets都进行遍历。
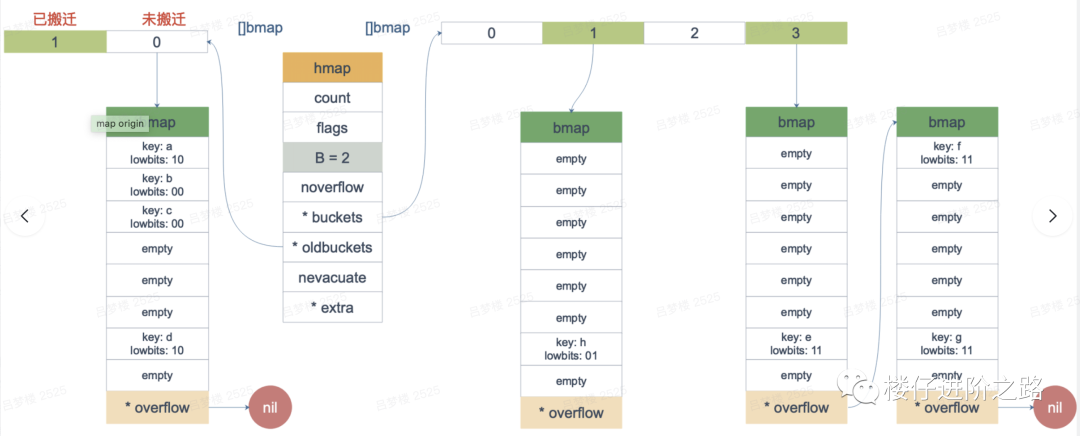
3.6 总结
对于map的使用,大家肯定都会,所以基础的知识讲解的不多,主要是对map的底层结构进行了详细的讲解,正所谓知其然,必知其所以然!对于map的底层结构设计,感觉有些意思,特别是对于它的hash方式(取前N位和后M位),再结合它的扩容和缩容,其实可以从中提炼一些共性的东西。然后对于Rehash,这个和Redis的Rehash原因一样,这块应该是业内的通用设计方法,感兴趣的同学可以看看redis的字典结构和它rehash的方法。

















 458
458

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









