







题目:构造数组的MaxTree
题目展示:
定义二叉树节点如下:
//创建一个树的节点,用于构建最大树
typedef struct listNodeTree
{
int val;
struct listNodeTree* left;
struct listNodeTree* right;
//之后编写一个含参数的默认构造,可以在创建节点的时候自动进行赋值操作
listNodeTree(int data)
:val(data)
, left(nullptr)
, right(nullptr)
{}
}LTNode; 一个数组的 MaxTree 定义如下。
数组必须没有重复元素。
MaxTree 是一棵二叉树,数组的每一个值对应一个二叉树节点。
包括 MaxTree 树在内且在其中的每一棵子树上,值最大的节点都是树的头。
给定一个没有重复元素的数组 arr;写出生成这个数组的 MaxTree 的函数,要求如果数组长度为 N,则时间复杂度为 O(N)、额外空间复杂度为 o(N)。
题目解析:
解法一:对数组先排序,之后构建树 时间复杂度:O(N*logN)
这道题目要求我们构建符合条件的二叉树的结构。所以我们需要想办法找到合适的方法。首先我们最容易想到的就是先对数组进行排序,之后得到一个有序的数组,最后再构建我们想要的树的结构。但是这样并不符合我们题目当中的要求,因为据我们所知,即使再优秀的排序算法构建一个有序数组的时间复杂度也是O(N*logN),时间复杂度不满足要求,所以我们需要查找其他符合条件的算法。
解法二:选取左边或右边大于该位置但是最小的值 时间复杂度:O(N)
这个算法的思路源于我们本书,第一次看到的时候肯定会感到十分惊奇,这是一个十分神奇的算法,完美的符合了我们本题的要求。
首先我们举一个简单的例子:
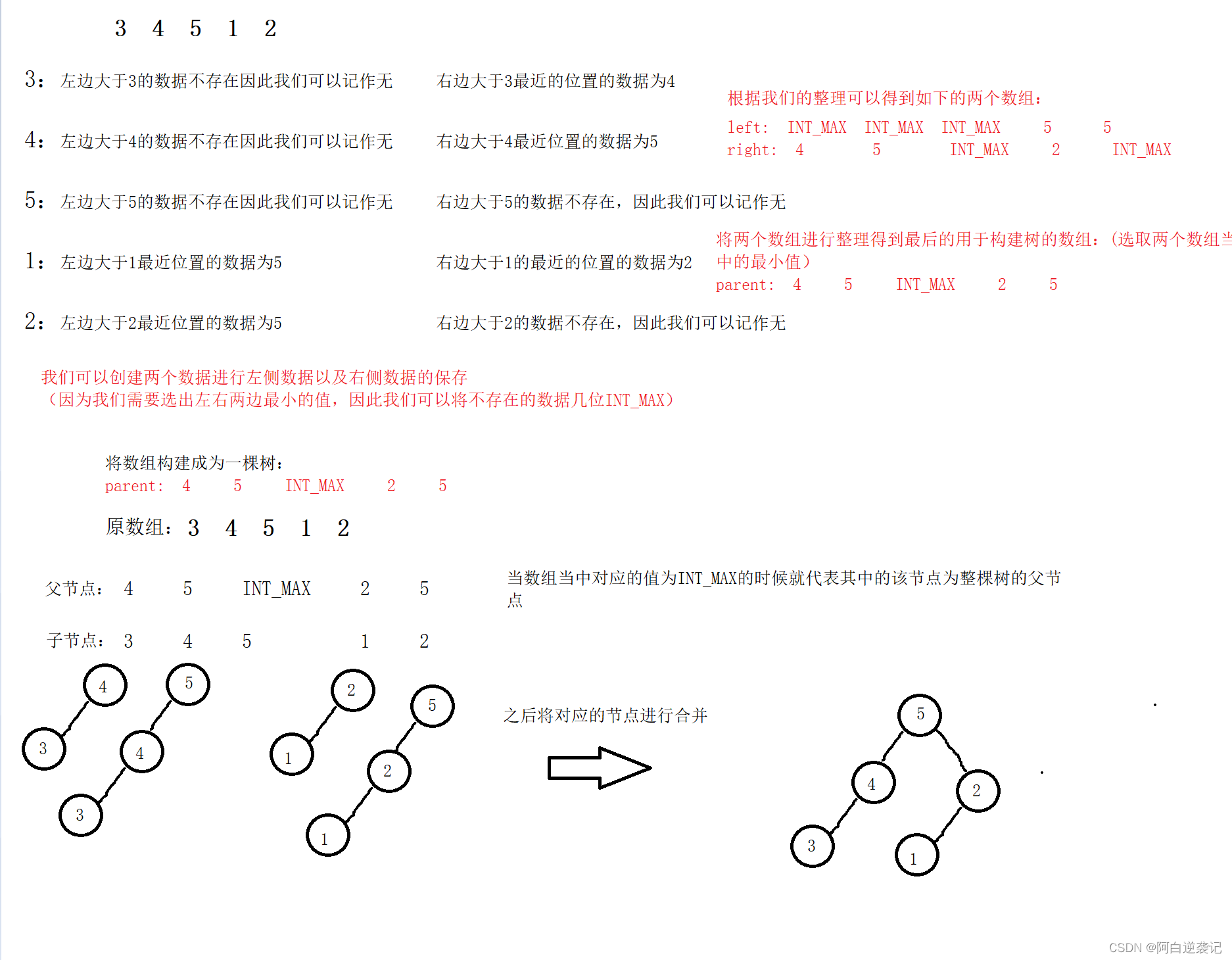
我们需要对如下的数据进行操作:arr ={3, 4, 5, 1, 2}
3 的左边第一个比 3 大的数:无 3 的右边第一个比 3 大的数:4
4 的左边第一个比 4 大的数:无 4 的右边第一个比 4 大的数:5
5 的左边第一个比 5 大的数:无 5 的右边第一个比 5 大的数:无
1 的左边第一个比1 大的数:5 1 的右边第一个比 1 大的数:2
2 的左边第一个比 2 大的数: 5 2 的右边第一个比 2 大的数:无
就像是我们如上的思路那样,我们需要找到某个节点位置附近大于该位置,但是较小的值。所以我们可以列出如上的数据。同时我们可以创建两个数组,分别保存该位置左边大于该位置的值以及右边大于该位置的值。之后选出这两个数组当中对应位置较小的数据,该数据就是我们想要产生的父亲节点。我们先熟悉一下构建的过程,之后我们会给出明确的证明。过程如下:
原理证明:
一个合格的算法不是空想出来的,都需要严格的证明,最终才可以称得上是一个严谨的算法。那么我们就来证明该算法的合理性。
首先我们的节点综合起来可以构建成为一棵树而不是多棵树,因为除了最大的数之外,以后的所有的数都可以找到比它大的数据作为父亲节点。因此所有的节点都直接或者间接的链接到最大的数之下。
其次这是一颗二叉树。这就需要我们证明左右可能产生的节点的情况了,即证明数组的一侧孩子的数量不可能超过1。
我们可以使用反证法进行证明:我们可以假设一个数的一侧可能存在两个孩子节点,也就是存在两个较小的数据。由于我们数组当中不存在重复的元素,因此我们可以分类讨论:
1. parent child1 child2 且child1>child2
假设左侧的孩子节点的数据更大,因此毫无疑问,child1的父亲节点是parent,但是对于child2来说,child1已经满足大于child2的要求了,就不会向左进行查找找到parent了。所以该情况不可能出现。
2. parent child1 child2 且child1<child2
假设右侧的孩子节点的数据更大,所以我们child2的父亲节点毫无疑问是parent了,但是对于child1来说,我们会向左侧找到一个大于child1的数据parent,也会向右侧找到一个大于child1的数据child2。相比于parent和child2来说,由于parent大于child2,我们需要选择一个更小的数据来作为父亲节点所以child1的父亲节点会试child2。所以我们数据的一侧只可能存在一个孩子节点。另一侧也是相同的道理。所以我们所构建成的树就是一棵二叉树。
证明完毕。
代码构建以及细节注意事项:
接下来我们需要进行的就是将我们的算法转化成为代码的形式。我们来规划一下需要进行的操作:
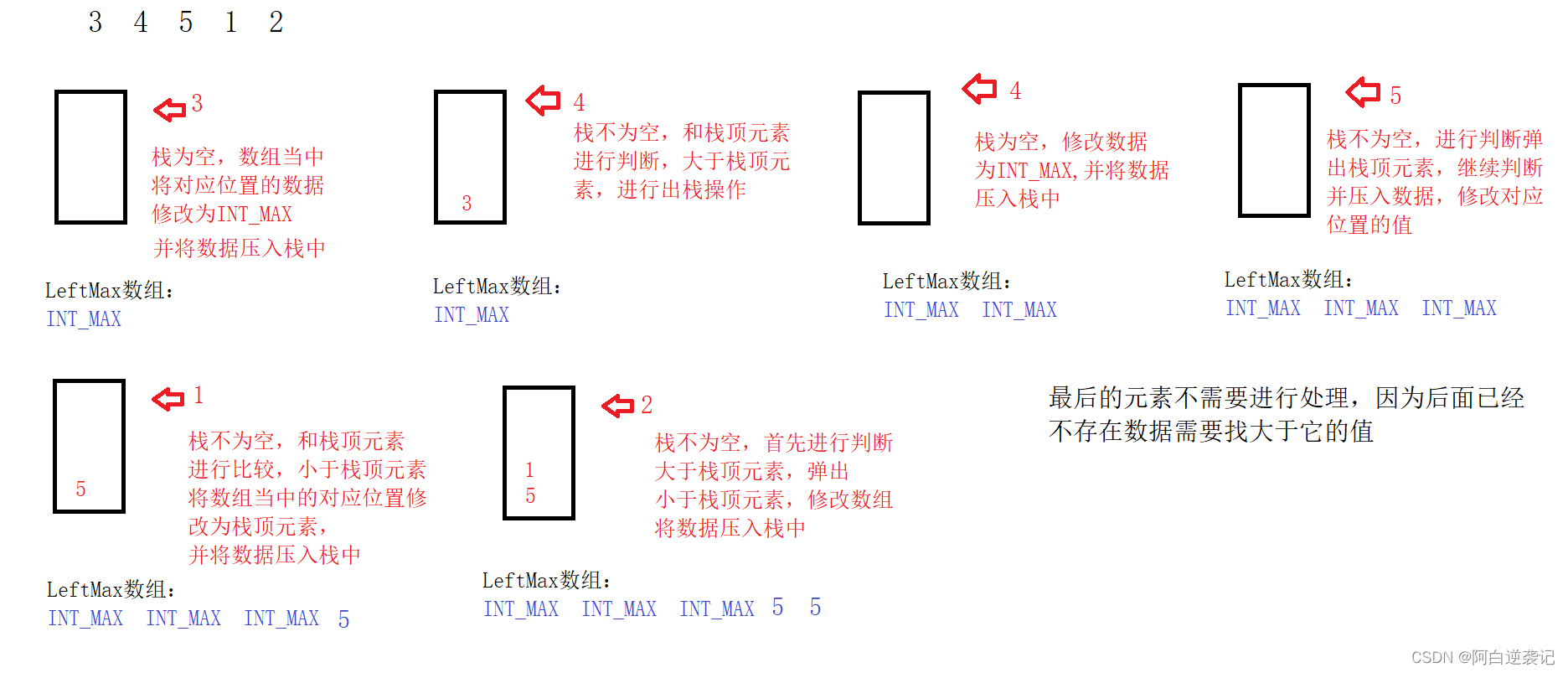
1.创建两个数组,分别保存从左侧开始,大于该位置的数据值,也就是我们的父亲节点。
但是在创建的时候我们需要注意:我们需要以什么方式构建呢?如果每次都进行一遍查询的话,那么我们的时间复杂度就为O(N^2)很明显效果并不好,所以我们需要进行优化一下。
当我们面对与连续的变化的多次进行的数组进行选择最大或者最小的数据的时候我们可以想到我们可以尝试使用栈进行代码的优化操作。
我们可以创建一个栈,向栈当中不断地压入数据,在加入数据之前,我们需要先判断栈是否为空,如果为空就将数组当中指定位置的值修改为INT_MAX,因为该位置可能是边界数据,那么左边就不存在大于该位置的值。如果栈不为空就进行判断,首先将数据和栈顶的元素进行判断,如果栈顶元素小于我们该位置的元素,就直接弹出栈顶元素,接着和接下来的栈中的数据进行比较。直到我们的栈为空,或者该位置的数据小于栈顶的数据为止。如果栈为空,就将数组当中对应的位置修改为INT_MAX,如果栈不为空,就说明栈顶元素就为该边最接近的大于该位置的数据,我们直接保存即可。所进行的步骤如下:
2.合并leftMax数组和rightMax数组,找到其中对应位置较小的值,生成一个新的数组,根据这个新的数组进行构建树
第二步就像是我们所说的那样,但是我们在编写代码的时候我们可能会对如何查找数据产生疑问,举一个简单的例子:数据 2 的父亲节点为 5 。但是我们如何找到 5 这个数据节点就成为一个问题了,如果检查每一个数据都向前进行一次遍历,时间复杂度肯定达不到要求,因此我们在此,采用了pair的形式将数值和下标连接起来。首先我们先将数组当中所有的数据都转化成为节点的形式。之后将父节点的值和下标一起保存起来进行判断。节点的值用于进行比较,下标用于方便查找。思路示意图:

那么根据如上思路,我们可以编写如下的代码:
#define _CRT_SECURE_NO_WARNINGS
#include<iostream>
#include<stack>
#include<vector>
#include<algorithm>
using namespace std;
//创建一个树的节点,用于构建最大树
typedef struct listNodeTree
{
int val;
struct listNodeTree* left;
struct listNodeTree* right;
//之后编写一个含参数的默认构造,可以在创建节点的时候自动进行赋值操作
listNodeTree(int data)
:val(data)
, left(nullptr)
, right(nullptr)
{}
}LTNode;
void modifyLeftAndRight(const vector<int>&datas,vector<int>& left, vector<int>& right)
{
stack<pair<int,int>> leftArr;
stack<pair<int, int>> rightArr;
for (int i = 0; i < datas.size(); i++)
{
//判断栈是否为空,并将数据修改加入到新数组
if (leftArr.empty())
{
//向最左侧的数组当中加入一个最大的数据
left.push_back(INT_MAX);
leftArr.push(make_pair(datas[i], i));
}
else
{
//和栈中的数据进行比较
while (1)
{
if (!leftArr.empty() && datas[i] >= leftArr.top().first)
{
leftArr.pop();
}
else
{
//当进入该部分的时候需要判断数组当中的内容是否为空,如果为空就直接向数组当中加入最大的数据
if (leftArr.empty())
{
left.push_back(INT_MAX);
}
else
{
//当栈不为空的时候,直接向栈当中加入数据,之后将数组当中的数据进行修改
left.push_back(leftArr.top().second);
}
leftArr.push(make_pair(datas[i], i));
break;
}
}
}
int pos = datas.size() - 1 - i;
//单次的左侧数组当中的数据已经修改完毕了,那么之后就需要将右侧数组当中的最大值以同样的方式进行加入到right数组当中
//判断栈是否为空,并将数据修改加入到新数组
if (rightArr.empty())
{
//向最左侧的数组当中加入一个最大的数据
right.push_back(INT_MAX);
rightArr.push(make_pair(datas[pos], pos));
}
else
{
//和栈中的数据进行比较
while (1)
{
if (!rightArr.empty() && datas[pos] >= rightArr.top().first)
{
rightArr.pop();
}
else
{
//当进入该部分的时候需要判断数组当中的内容是否为空,如果为空就直接向数组当中加入最大的数据
if (rightArr.empty())
{
right.push_back(INT_MAX);
}
else
{
//当栈不为空的时候,直接向栈当中加入数据,之后将数组当中的数据进行修改
right.push_back(rightArr.top().second);
}
rightArr.push(make_pair(datas[pos], pos));
break;
}
}
}
}
reverse(right.begin(), right.end());
}
LTNode* CTMaxTree(const vector<int>& sour, const vector<int> maxData)
{
//为了便于链接各个节点,所以我们将所有的数据都转化成为节点的形式
vector<LTNode*> nodes;
for (int i = 0; i < sour.size(); i++)
{
LTNode* newnode = new LTNode(sour[i]);
nodes.push_back(newnode);
}
//最后将树链接起来得到最终的结果
LTNode* head = nullptr;
for (int i = 0; i < sour.size(); i++)
{
if (maxData[i] == INT_MAX)
{
//当数据为最大值的时候,该节点为我们树的头节点
head = nodes[i];
}
else
{
//之后将较小的节点连接到父节点的下方
int pos = maxData[i];
if (nodes[pos]->left == nullptr)
{
//链接到左子树部分
nodes[pos]->left = nodes[i];
}
else
{
//链接到右子树的部分
nodes[pos]->right = nodes[i];
}
}
}
//当循环结束的时候直接返回head即可
return head;
}
LTNode* createMaxTree(const vector<int>& datas)
{
//创建两个数组进行求解相邻的最左侧最右侧最接近的最大值
vector<int> left;
vector<int> right;
modifyLeftAndRight(datas,left, right);
//等待修改完成数据之后,我们只需要对最大的左边和最右边的数据进行判断,即可得到想要的父亲节点
vector<int> mid;
for (int i = 0; i < datas.size(); i++)
{
int pos = left[i];
if (pos == INT_MAX)
{
mid.push_back(right[i]);
continue;
}
else if (right[i] == INT_MAX)
{
mid.push_back(left[i]);
continue;
}
else if (min(datas[left[i]], datas[right[i]]) != datas[pos])
{
pos = right[i];
}
mid.push_back(pos);
}
//之后直接创建节点并构建成为一棵树即可
return CTMaxTree(datas,mid);
}
void preOrder(LTNode* head)
{
if (head == nullptr)
{
return;
}
cout << head->val << " ";
preOrder(head->left);
preOrder(head->right);
}
int main()
{
//将数组转化成为符合标准的最大数
vector<int> nums({ 3,4,5,1,2,6,8,7,0 });
LTNode* head= createMaxTree(nums);
//之后遍历树查看是否符合我们的要求
preOrder(head);
return 0;
}

















 1472
1472

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











