







基于协同过滤推荐的在线课程选修系统
demo
网站查看 http://course.qsxbc.com/all_course/
点我查看
效果
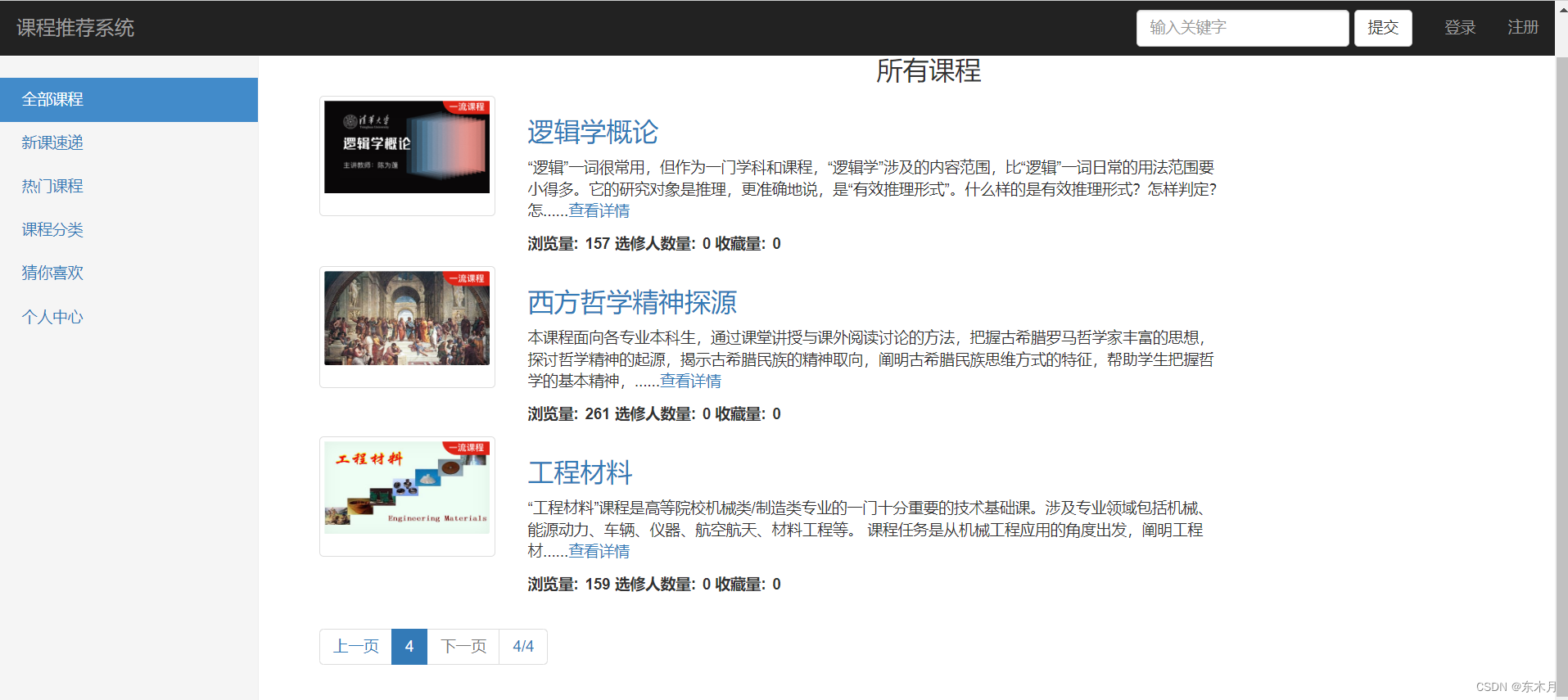
功能
登录注册、点赞收藏、评分评论,课程推荐,热门课程,个人中心,可视化,后台管理,课程选修
推荐算法
# -*-coding:utf-8-*-
"""
@contact: 微信 1257309054
@file: recommend_user.py
@time: 2024/6/8 16:21
@author: LDC
使用Keras框架实现一个深度学习推荐算法
"""
import collections
import math
import os
import django
import operator
import numpy as np
from course.models import *
from k_means_utils import predict
os.environ["DJANGO_SETTINGS_MODULE"] = "course_manager.settings"
django.setup()
def get_default_recommend(user_id):
# 获取默认推荐
# 获取用户注册时选择的类别
category_ids = []
us = UserSelectTypes.objects.get(user_id=user_id)
for category in us.category.all():
category_ids.append(category.id)
course_list = CourseInfo.objects.filter(tags__in=category_ids).distinct().order_by("-collect_num")[:30]
return course_list
class UserCf:
# 基于用户协同算法来获取推荐列表
"""
利用用户的群体行为来计算用户的相关性。
计算用户相关性的时候我们就是通过对比他们选修过多少相同的课程相关度来计算的
举例:
--------+--------+--------+--------+--------+
| X | Y | Z | R |
--------+--------+--------+--------+--------+
a | 1 | 1 | 1 | 0 |
--------+--------+--------+--------+--------+
b | 1 | 0 | 1 | 0 |
--------+--------+--------+--------+--------+
c | 1 | 1 | 0 | 1 |
--------+--------+--------+--------+--------+
a用户选修了:X、Y、Z
b用户选修了:X、Z
c用户选修了:X、Y、R
那么很容易看到a用户和b、c用户非常相似,给a用户推荐课程R,
给b用户推荐课程Y
给c用户推荐课程Z
这就是基于用户的协同过滤。
a用户向量为(1,1,1,0)
b用户向量为(1,0,1,0)
c用户向量为(1,1,0,1)
找a用户的相似用户,则计算a向量与其他向量的夹角即可,夹角越小则说明越相近
利用求高维空间向量的夹角,可以估计两组数据的吻合程度
"""
# 获得初始化数据
def __init__(self, data):
self.data = data
# 计算N维向量的夹角
def calc_vector_cos(self, a, b):
'''
cos=(ab的内积)/(|a||b|)
:param a: 向量a
:param b: 向量b
:return: 夹角值
'''
a_n = np.array(a)
b_n = np.array(b)
if any(b_n) == 0:
return 0
cos_ab = a_n.dot(b_n) / (np.linalg.norm(a_n) * np.linalg.norm(b_n))
print('值为', cos_ab)
return round(cos_ab, 2)
# 计算与当前用户的距离,获得最临近的用户
def nearest_user(self, username, n=2):
distances = {}
# 用户,相似度
# 遍历整个数据集
for user, rate_set in self.data.items():
# 非当前的用户
if user != username:
print('获取{}与{}的向量夹角'.format(username, user))
vector_a = tuple(self.data[username].values())
vector_b = tuple(self.data[user].values())
distance = self.calc_vector_cos(vector_a, vector_b)
# 计算两个用户的相似度
distances[user] = distance
# 排序,按向量夹角由小到到排序
closest_distance = sorted(distances.items(), key=operator.itemgetter(1), reverse=True)
# 最相似的N个用户
closest_users = []
for cd in closest_distance:
if cd[1] == 1:
closest_users.append(cd)
else:
if len(closest_users) >= n:
break
closest_users.append(cd)
print("closest user:", closest_users)
return closest_users
# 给用户推荐课程
def recommend(self, username, n=1):
recommend = set()
nearest_user = self.nearest_user(username, n) # 获取最相近的n个用户
for user_id, _ in nearest_user:
for usercourse in UserCourse.objects.filter(user_id=user_id):
if usercourse.course.id not in self.data[username].keys():
recommend.add(usercourse.course.id)
return recommend
# 用户推荐
def recommend_by_user_id(user_id, is_mix=False):
# 通过用户协同算法来进行推荐
current_user = User.objects.get(id=user_id)
# 如果当前用户没有选修过课程,则按照收藏量降序返回
if current_user.usercourse_set.count() == 0:
if is_mix:
return []
return get_default_recommend(user_id)
data = {}
course_ids = []
other_user_ids = set()
# 把该用户选修过的课程变成向量字典:{'用户id': {'课程1id': 1, '课程2id': 1...}}
for u_course in current_user.usercourse_set.all():
# 遍历用户选修过的课程
if not data:
data[current_user.id] = {u_course.course.id: 1} # 已选课程,设置值为1
else:
data[current_user.id][u_course.course.id] = 1
course_ids.append(u_course.course)
# 获取其他选修过该课程的用户id
for usercourse in UserCourse.objects.filter(course=u_course.course):
if usercourse.user.id != current_user.id:
other_user_ids.add(usercourse.user.id)
# 把选修过其中课程的用户选修过的课程变成向量字典:{'用户2id': {'课程1id': 0, '课程2id': 1...}}
for other_user in User.objects.filter(pk__in=other_user_ids):
other_user_id = other_user.id
for i in range(len(course_ids)):
course = course_ids[i]
if UserCourse.objects.filter(user_id=other_user_id, course=course):
is_select = 1
else:
is_select = 0
if other_user_id not in data:
data[other_user_id] = {course.id: is_select} # 已选课程,设置值为1,未选课程设置为0
else:
data[other_user_id][course.id] = is_select
user_cf = UserCf(data=data)
recommend_ids = user_cf.recommend(current_user.id, 1)
if not recommend_ids:
# 如果没有找到相似用户则按照收藏量降序返回
if is_mix:
return []
return get_default_recommend(user_id)
if is_mix:
return list(recommend_ids)
return CourseInfo.objects.filter(is_show=True, id__in=recommend_ids).order_by('-select_num')
# 物品推荐
class ItemCf:
# 基于物品协同算法来获取推荐列表
'''
1.构建⽤户–>物品的对应表
2.构建物品与物品的关系矩阵(同现矩阵)
3.通过求余弦向量夹角计算物品之间的相似度,即计算相似矩阵
4.根据⽤户的历史记录,给⽤户推荐物品
'''
def __init__(self, user_id):
self.user_id = user_id # 用户id
def get_data(self):
# 获取用户评分过的课程
rate_courses = RateCourse.objects.filter()
if not rate_courses:
return False
datas = {}
for rate_course in rate_courses:
user_id = rate_course.user_id
if user_id not in datas:
datas.setdefault(user_id, {})
datas[user_id][rate_course.course.id] = rate_course.mark
else:
datas[user_id][rate_course.course.id] = rate_course.mark
return datas
def similarity(self, data):
# 1 构造物品:物品的共现矩阵
N = {} # 喜欢物品i的总⼈数
C = {} # 喜欢物品i也喜欢物品j的⼈数
for user, item in data.items():
for i, score in item.items():
N.setdefault(i, 0)
N[i] += 1
C.setdefault(i, {})
for j, scores in item.items():
if j != i:
C[i].setdefault(j, 0)
C[i][j] += 1
print("---1.构造的共现矩阵---")
print('N:', N)
print('C', C)
# 2 计算物品与物品的相似矩阵
W = {}
for i, item in C.items():
W.setdefault(i, {})
for j, item2 in item.items():
W[i].setdefault(j, 0)
W[i][j] = C[i][j] / math.sqrt(N[i] * N[j])
print("---2.构造的相似矩阵---")
print(W)
return W
def recommand_list(self, data, W, user, k=3, N=10):
'''
# 3.根据⽤户的历史记录,给⽤户推荐物品
:param data: 用户数据
:param W: 相似矩阵
:param user: 推荐的用户
:param k: 相似的k个物品
:param N: 推荐物品数量
:return:
'''
rank = {}
for i, score in data[user].items(): # 获得⽤户user历史记录,如A⽤户的历史记录为{'唐伯虎点秋香': 5, '逃学威龙1': 1, '追龙': 2}
for j, w in sorted(W[i].items(), key=operator.itemgetter(1), reverse=True)[0:k]: # 获得与物品i相似的k个物品
if j not in data[user].keys(): # 该相似的物品不在⽤户user的记录⾥
rank.setdefault(j, 0)
rank[j] += float(score) * w # 预测兴趣度=评分*相似度
print("---3.推荐----")
print(sorted(rank.items(), key=operator.itemgetter(1), reverse=True)[0:N])
return sorted(rank.items(), key=operator.itemgetter(1), reverse=True)[0:N]
def recommendation(self, k=3, N=10):
"""
给用户推荐相似课程
:param user: 推荐的用户
:param k: 相似的k个物品
:param N: 推荐物品数量
"""
data = self.get_data()
if not data or self.user_id not in data:
# 用户没有评分过任何课程,就返回空列表
return []
W = self.similarity(data) # 计算物品相似矩阵
sort_rank = self.recommand_list(data, W, self.user_id, k, N) # 推荐
return sort_rank
def recommend_by_item_id(user_id, is_mix=False):
# 物品推荐
cf_list = ItemCf(user_id).recommendation() # 物品协同过滤得到的推荐列表
course_ids = [s[0] for s in cf_list]
if is_mix:
return course_ids
course_list = CourseInfo.objects.filter(id__in=course_ids).distinct().order_by("-select_num")
if not course_list:
# 推荐列表为空
if is_mix:
return []
return get_default_recommend(user_id)
return course_list
# k-means推荐
def recommend_by_k_mean(user_id, course_id=None, is_mix=False):
# 使用机器学习K-means聚类算法推荐用户喜欢的课程
try:
data = [] # 用户课程类型挑选列表
tag_dict = collections.OrderedDict() # 课程类型字典(有序字典)
# 获取所有类型,并设置值为0
for tag in Tags.objects.filter():
tag_dict[tag.name] = 0
# 获取用户喜欢的课程类型
us = UserSelectTypes.objects.get(user_id=user_id)
for category in us.category.filter():
# 在类型字典中设置用户喜欢的类型为1
tag_dict[category.name] = 1
data.append(list(tag_dict.values()))
tag_like_list = predict(data) # 预测数据
if not tag_like_list:
# 预测推荐集合为空,则返回用户注册时选择的类别
if is_mix:
return []
return get_default_recommend(user_id)
index = 0
recommend_tag = []
for tag, value in tag_dict.items():
if tag_like_list[index] == 1:
# 用户喜欢的课程类型
recommend_tag.append(tag)
index += 1
print('推荐的类型', recommend_tag)
rank_set = set() # 推荐课程id集合
# 获取各推荐课程类型中排行前三的课程推荐给用户,其中排行按照收藏量来计算
for tag in recommend_tag:
courses = CourseInfo.objects.filter(tags__name=tag).order_by("-collect_num")[:5]
for course in courses:
rank_set.add(course.id)
print('推荐的列表id', rank_set)
if is_mix:
return list(rank_set)
if rank_set:
course_list = CourseInfo.objects.filter(id__in=rank_set).exclude(id=course_id).distinct().order_by(
"-collect_num")
return course_list
except Exception as e:
print('k-means出错', e)
# 预测推荐集合为空,则返回用户注册时选择的类别
if is_mix:
return []
return get_default_recommend(user_id)
# 混合推荐
def recommend_by_mix(user_id):
recommend_user_ids = recommend_by_user_id(user_id, is_mix=True) # 基于用户推荐
print('recommend_user_ids', recommend_user_ids)
recommend_item_ids = recommend_by_item_id(user_id, is_mix=True) # 基于物品推荐
print('recommend_item_ids', recommend_item_ids)
recommend_kmean_ids = recommend_by_k_mean(user_id, is_mix=True) # 基于k-means推荐
print('recommend_kmean_ids', recommend_kmean_ids)
recommend_ids = list(set(recommend_user_ids + recommend_item_ids + recommend_kmean_ids)) # 总的推荐列表
print('总的推荐列表', recommend_ids)
course_list = CourseInfo.objects.filter(is_show=True, id__in=recommend_ids).order_by('-select_num')
if not course_list:
# 推荐列表为空
return get_default_recommend(user_id)
return course_list



















 1262
1262

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











