




LLM在处理自然语言任务时表现出色,但在推理能力方面仍有待提升。传统的提升方法主要依赖于监督微调(SFT),这不仅需要大量标注数据,而且在某些情况下可能限制了模型的泛化能力。最近,DeepSeek(DeepSeek-V3 深度剖析:下一代 AI 模型的全面解读)团队提出了一种创新的方法,通过强化学习(RL)而非监督学习来提升大型语言模型的推理能力。这一方法在论文《DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning》中得到了详细阐述。本文将对该论文进行深入解读。
论文概述
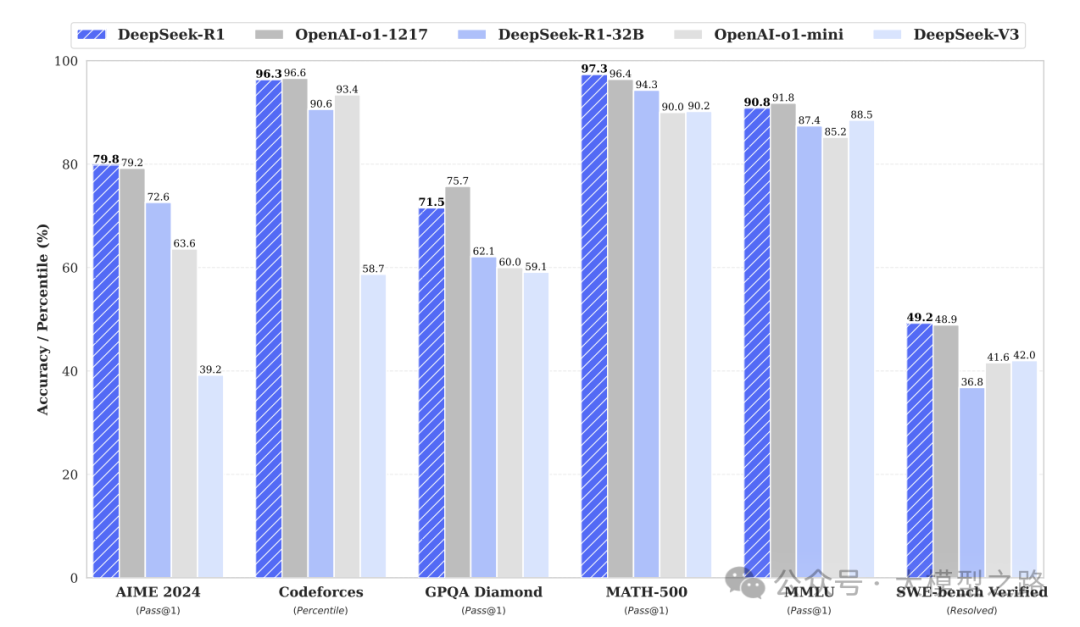
1. 主要贡献
论文提出了DeepSeek-R1(DeepSeek R1:开启 AI 推理新时代的开源先锋)和DeepSeek-R1-Zero两种新型模型,它们通过大规模强化学习
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











