




随着大型语言模型的涌现,如何通过优化算法和策略来提高这些模型的性能成为了业界和学术界关注的热点。OpenAI的o1模型展示了测试时扩展(Test-time Scaling)方法在提升语言模型性能方面的潜力。本文介绍了一种名为s1的简约测试时扩展方法,该方法旨在通过精心设计的数据集和创新的预算强制(Budget Forcing)策略,实现性能上的显著飞跃,甚至超越了OpenAI的o1-preview模型。
一、背景与动机
测试时扩展是一种利用额外测试时计算能力来提高模型性能的方法。这种方法的核心思想是,在测试阶段给予模型更多的计算资源,以便它能够更深入地处理输入信息,从而作出更准确的预测。OpenAI的o1模型已经证明了这种方法的有效性,但如何在保持方法简约性的同时实现性能的最大化提升,仍然是一个挑战。
二、s1方法概述
s1方法主要围绕两个核心部分展开:精心策划的小数据集s1K和创新的预算强制策略。
(一)s1K数据集
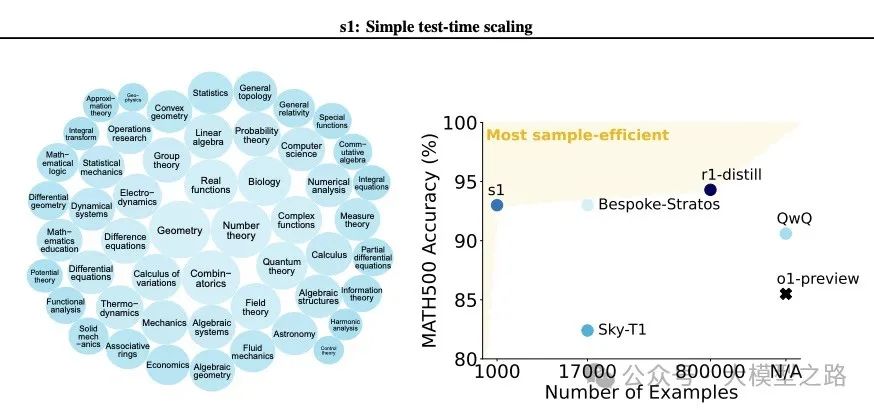
s1K是一个包含1000个问题的数据集,每个问题都配有详细的推理轨迹。这些数据集的选择基于三个关键标准:难度、多样性和质量。
-
难度:数据集应具有一定的挑战性,要求显著的推理努力。为了确保这一点,s1K从多个来源收集了初始的59029个问题,并通过两个不同规模的模型(Qwen2.5–7B-Instruct和Qwen2.5-32B-Instruct)进行评估,以筛选出那些能够反映模型推理能力的难题。
-
多样性:数据集应涵盖不同的领域,以覆盖不同的推理任务。为了实现这一点,s1K从现有的数据集(如NuminaMATH、AIME problems、OlympicArena、AGIEval)中筛选数据,并创建了两个
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1476
1476

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











