




之前的一篇文章GraphRag-知识图谱结合LLM 的检索增强简单介绍一下GraphRAG及一些基本原理,今天我们再深入分析一下GraphRAG原理。
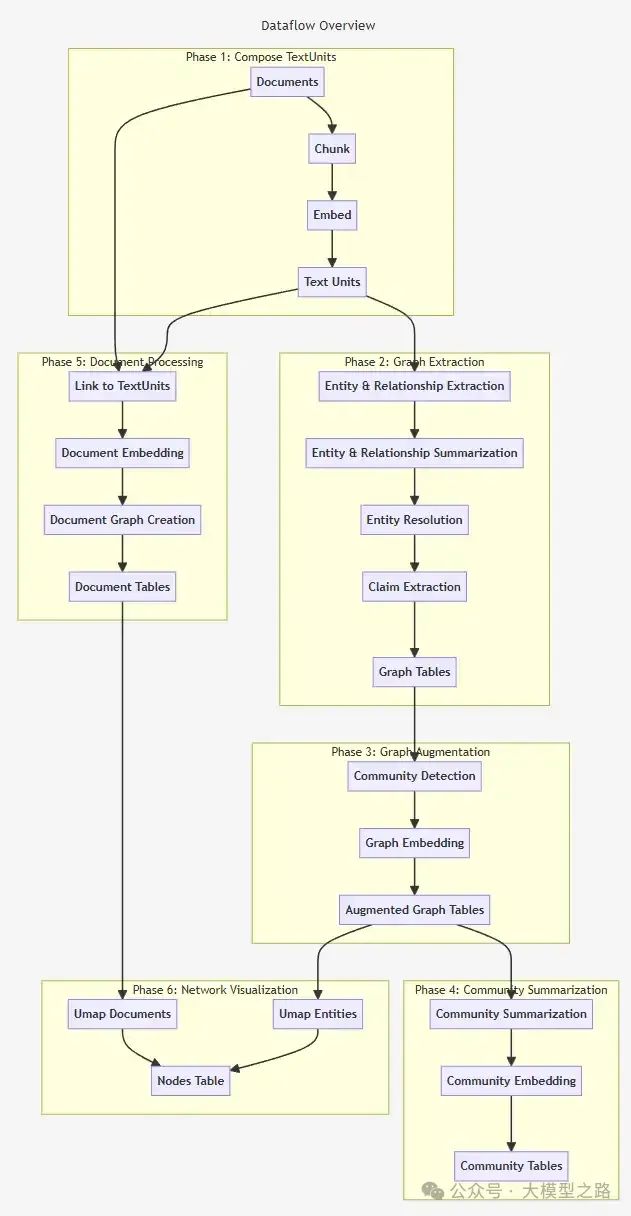
这幅图是知识图谱生成的完整过程,从这幅图中,我们可以更加细化的分析GraphRAG原理,GraphRAG主要包括以下几部分:
1、非结构化文本数据的切分
2、文本实体、关系抽取,生成图谱
3、图谱增强
4、社区总结
5、文档处理
6、知识图谱的可视化
接下来,我们就挨个进行详细分析。
非结构化文本数据的切分
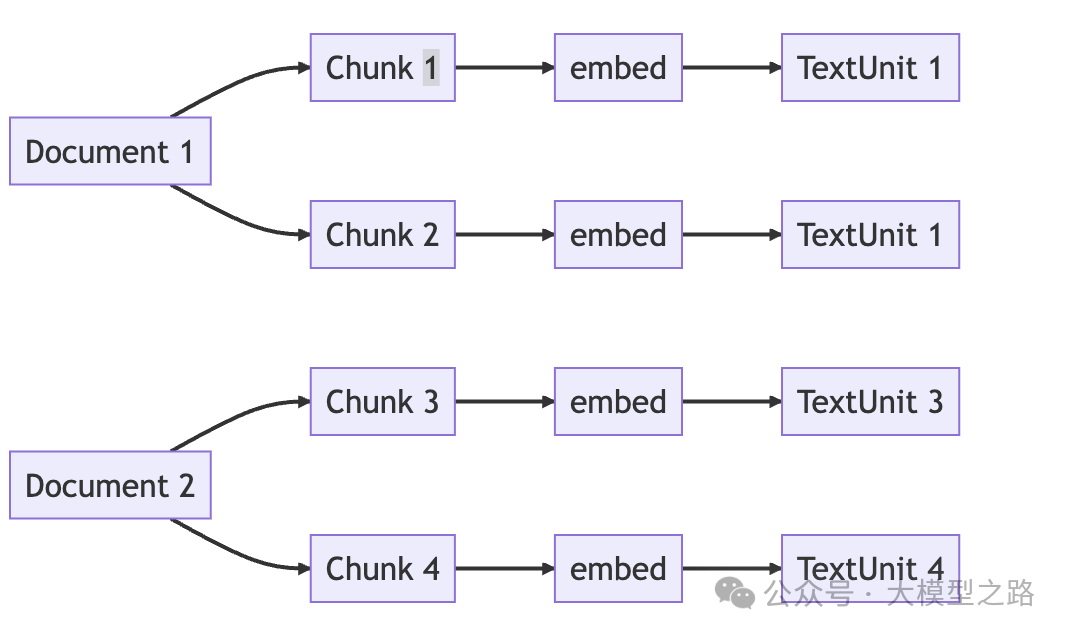
文本数据的切分和传统RAG切块是类似的,这里的切块依然需要考虑chunk大小
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1409
1409

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











