




 本文探讨了知识蒸馏中的软标签与硬标签概念,以及它们如何通过LossFn优化学生网络。知识蒸馏展示了即使在没有特定类别样本的情况下,教师网络仍能向学生网络传递关于该类别的信息。此外,文章还提及了知识蒸馏在无标签样本场景下的应用。
本文探讨了知识蒸馏中的软标签与硬标签概念,以及它们如何通过LossFn优化学生网络。知识蒸馏展示了即使在没有特定类别样本的情况下,教师网络仍能向学生网络传递关于该类别的信息。此外,文章还提及了知识蒸馏在无标签样本场景下的应用。
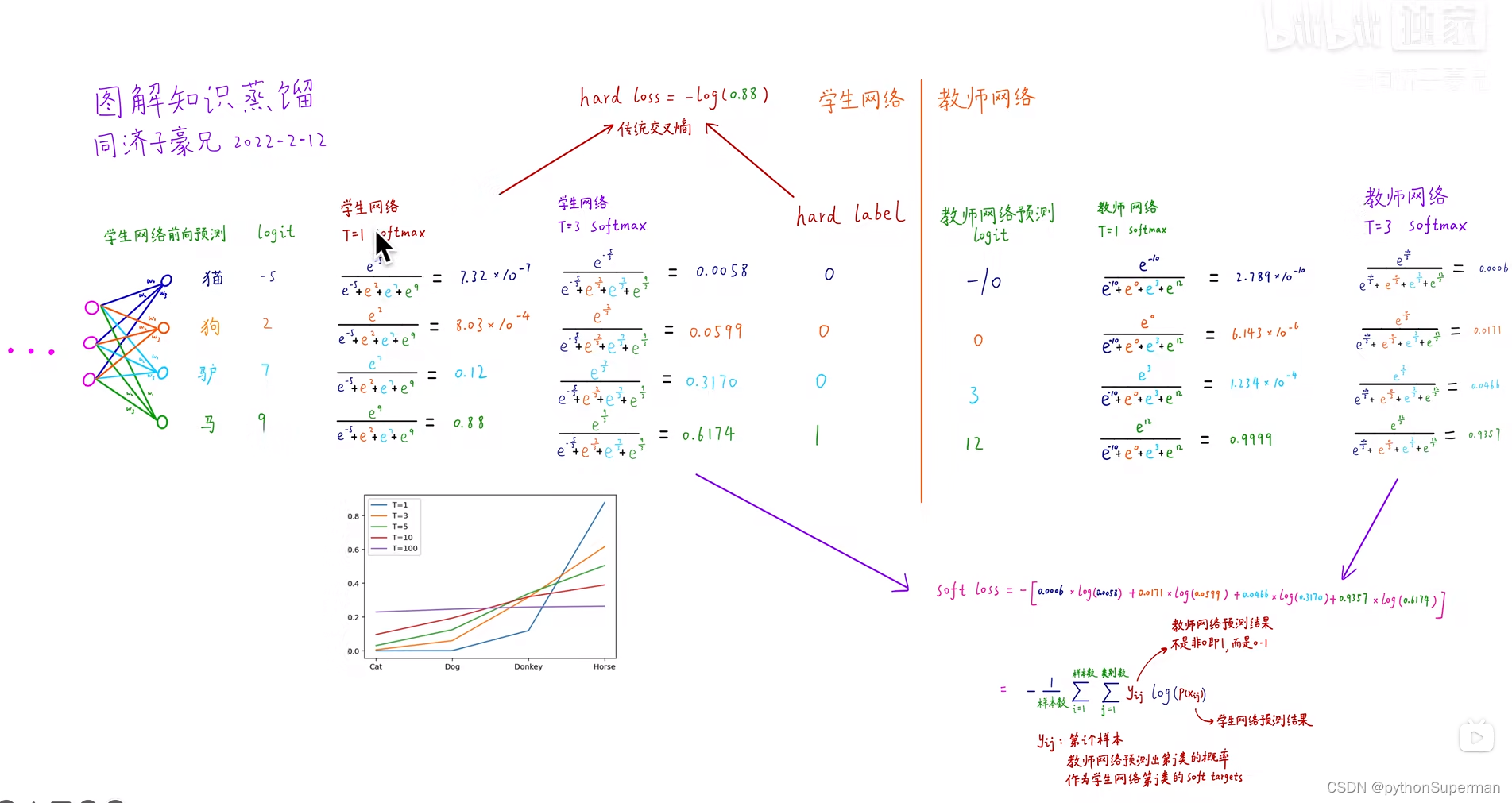
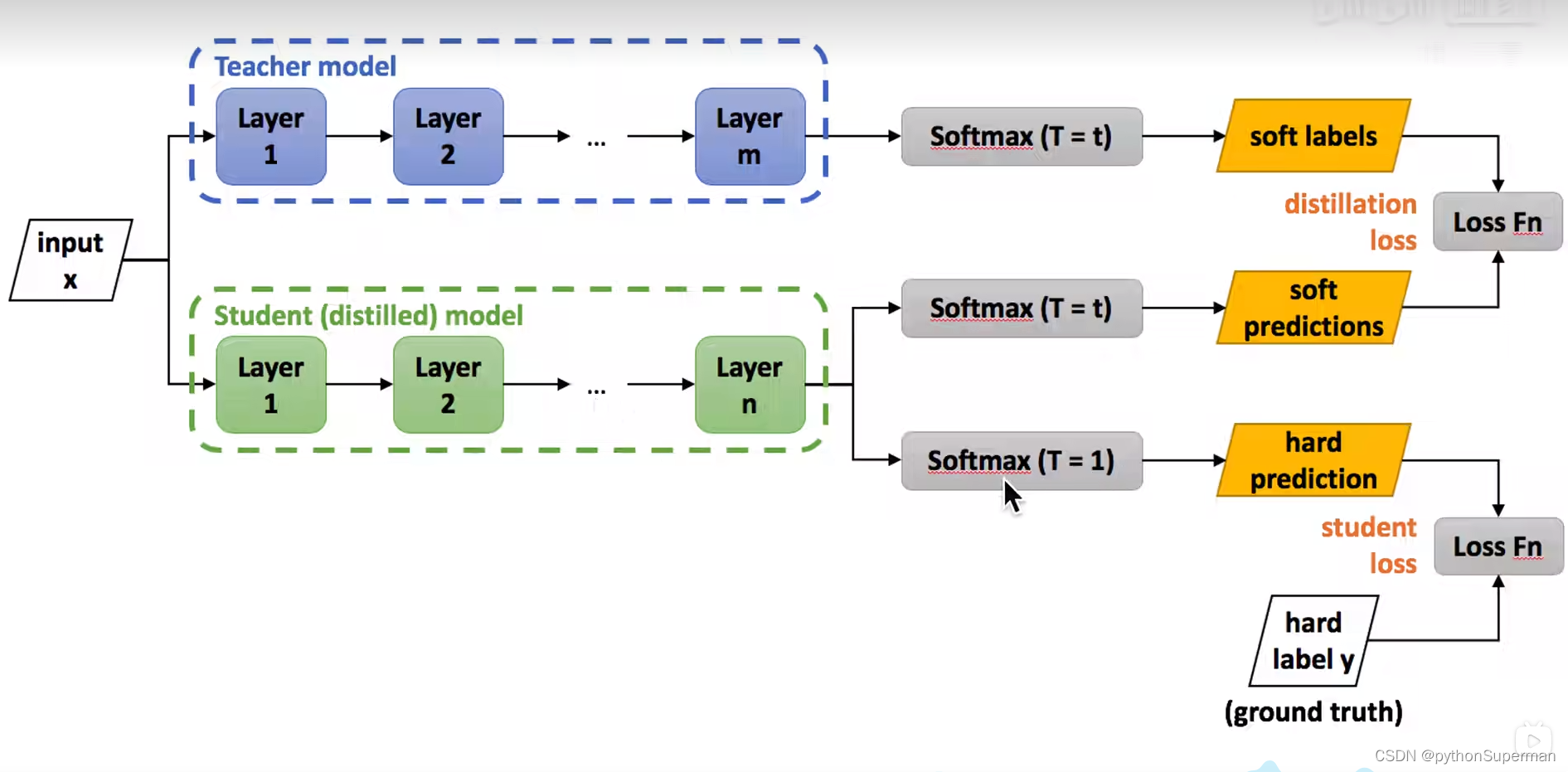
soft labels与soft predictions越接近越好,通过Loss Fn来实现,产生的数值叫做distillation loss,也叫soft loss。
hard label y与hard prediction越接近越好,通过Loss Fn来实现,产生的数值叫做student loss,也叫hard loss。
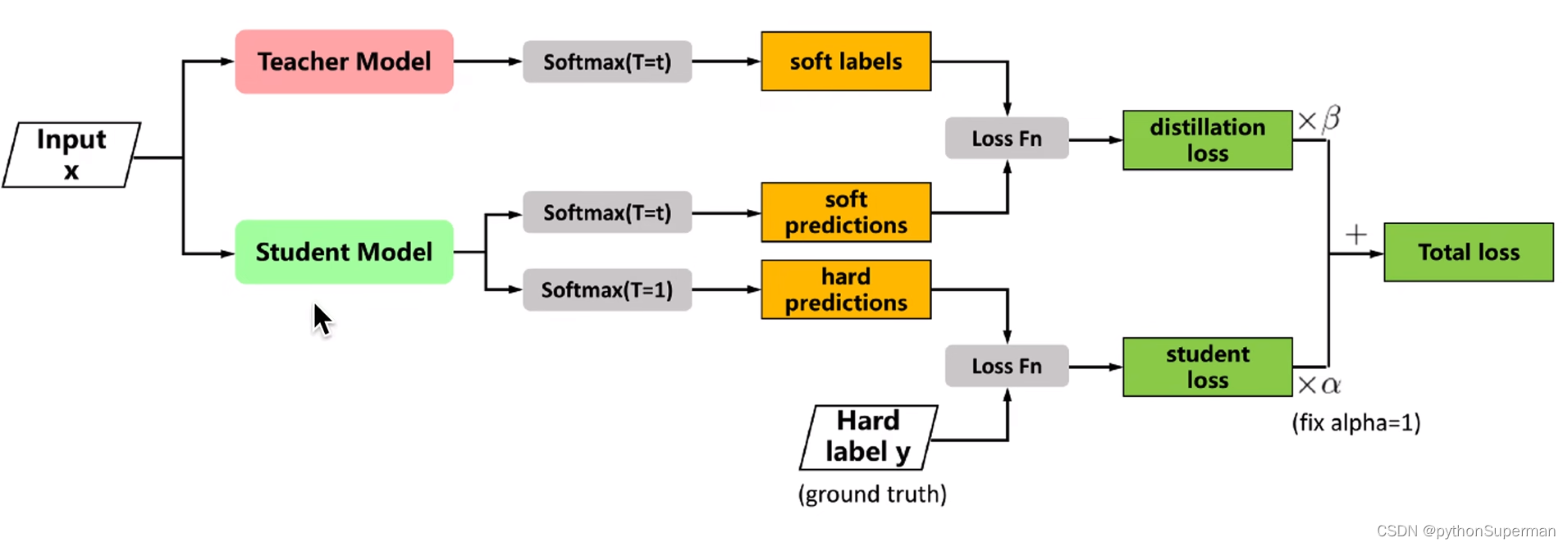
目的是微调学生网络中的权重,使得最终损失函数最小化。
实验结果
知识蒸馏有一个附带的效果,假如说我们的训练学生网络的数据集里抠掉类别为3的所有样本,然后用没有3的数据集去训练这个神经网络。但是训练教师网络的时候是用的所有类别去训练。
有一个神奇的效果就是,教师网络把类别为3的概率迁移给了学生网络。虽然学生网络在训练的过程中从来没有见到过3的类别的样本,但是老师把对类别3的见解传递给了学生网络:和8很像,和7不太像,和6有多不像全部传授了学生网络。所以学生网络在最终预测的时候,对3的类别仍然能够去识别。
知识蒸馏的应用场景
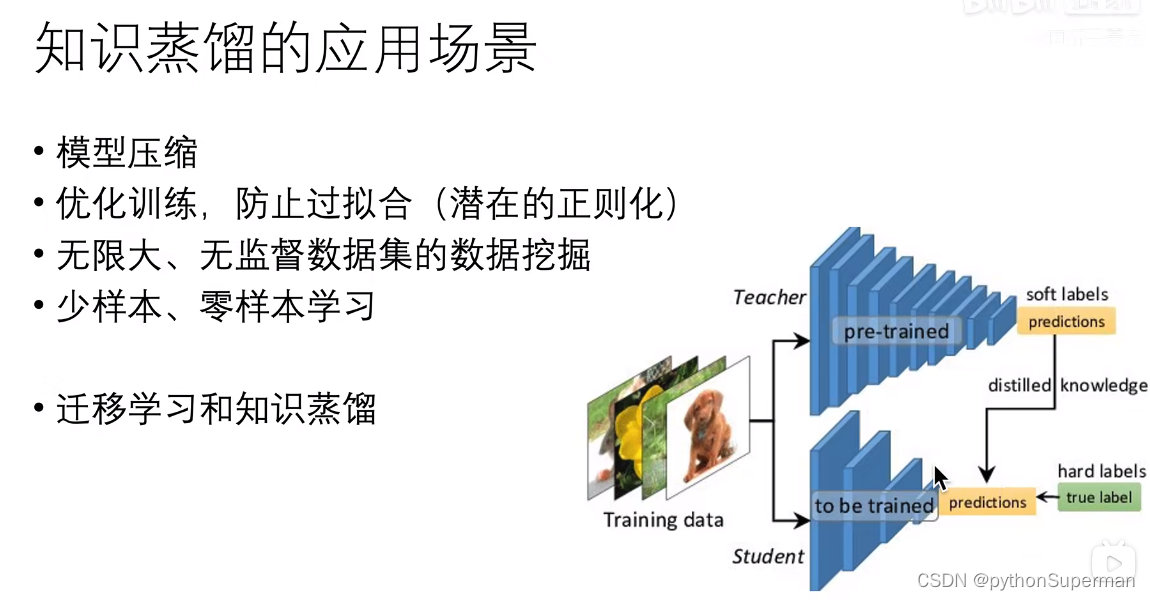
当样本图片没有标签的时候,也可以用知识蒸馏的方法解决。意思是只有soft labels。
老师会把所有的脑回路展示给学生,老师怎么做,学生就跟着怎么做,老师怎么学,学生就跟着怎么学,老师说是狗,学生就认为是狗就行了。


















 1285
1285

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









