



 本文通过一个具体的案例,详细介绍了如何使用Python进行线性回归分析。从数据读取、理解、预处理,到模型训练及结果解释,一步步展示了完整的分析流程。
本文通过一个具体的案例,详细介绍了如何使用Python进行线性回归分析。从数据读取、理解、预处理,到模型训练及结果解释,一步步展示了完整的分析流程。
目录
数据集
https://download.youkuaiyun.com/download/llf000000/86724138
基于实例的线性回归的简要介绍
在数据集women的基础上,以身高为自变量,而体重为因变量进行线性回归分析。
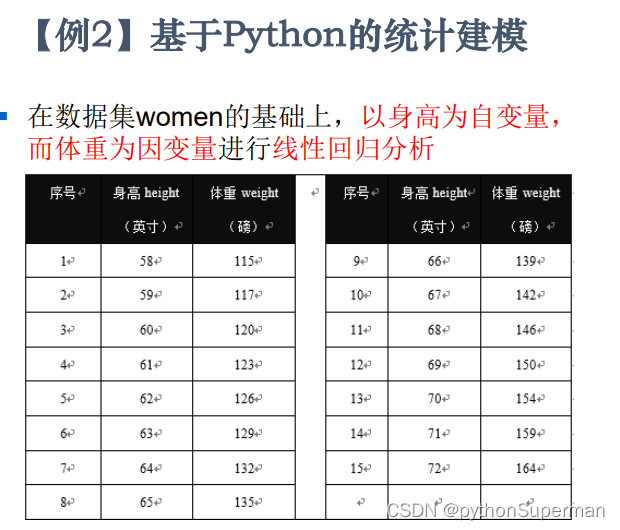

x是自变量height,y是因变量weight
最小二乘法:每个点到该条线的距离之和最小的线就是最好的线。
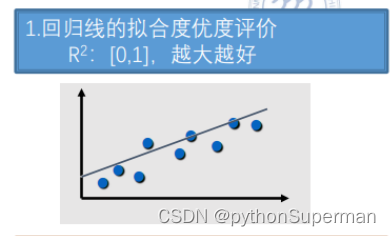
回归线的拟合优度评价,越接近1越好
代码块
(1)数据的读入
#查看当前工作目录
import os
print(os.getcwd())#读入文件"women.csv"至Pandas数据框df_women
import pandas as pd
df_women = pd.read_csv('women.csv', index_col=0)
#第0列为索引列/行名
#第一列和第一行不能参加数据的分析
print(df_women.head())
#显示前5行数据
(2)数据的理解
以“数据框形状”的角度去理解数据
# 查看数据形状(行数和列数)
df_women.shape
#shape是DataFrame数据框的属性
#shape是属性,所以没有“()”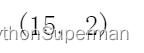
以“简要信息”的角度去理解数据
#查看数据框的简要信息
df_women.info()
#info()是方法,所以又“()”
以“列”的角度去理解数据
#属性相当于变量,方法相当于函数
# 查看列名
print(df_women.columns)
#columns是属性 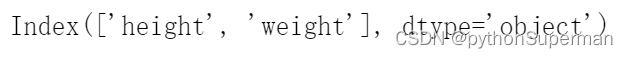
dtype是数据类型,Python认为一切都是对象,一切都是object
以“描述性统计”的角度去理解数据
# 查看描述性统计信息
df_women.describe()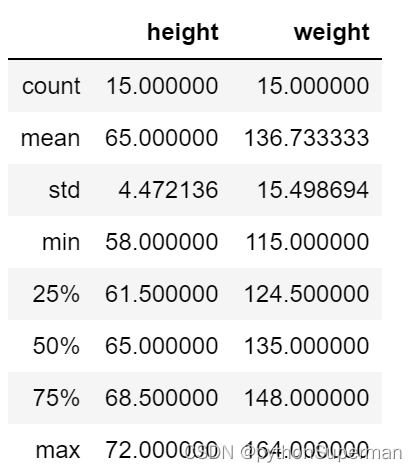
count:数量
mean:均值
std(Standard deviation):标准差
min:最小的值
max:最大的值
以“可视化的角度”去理解数据
用matplotlib进行可视化

rc


# 数据可视化
#pyplot是做数据可视化的
# “@”:装饰器
# “#”:注释
# “%”:魔术命令,是jupyter才有的
import matplotlib.pyplot as plt
%matplotlib inline
#inline:把接下来画的图放在行内,在当前的页面上显示
#plt.rcParams["font.family"] = 'Heiti TC'这段代码不行
# 解决中文显示问题
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# windows下
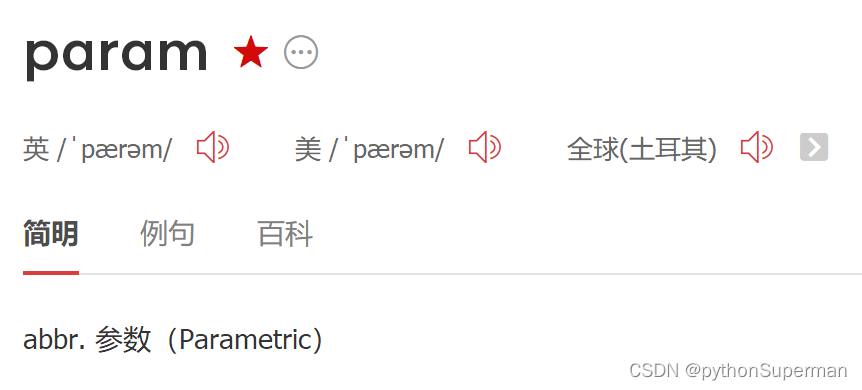
#plt.rcParams['font.family']="XimHei" #汉字显示 param:参数
# “front.family”是字体集
#Heiti TC 黑体 TC
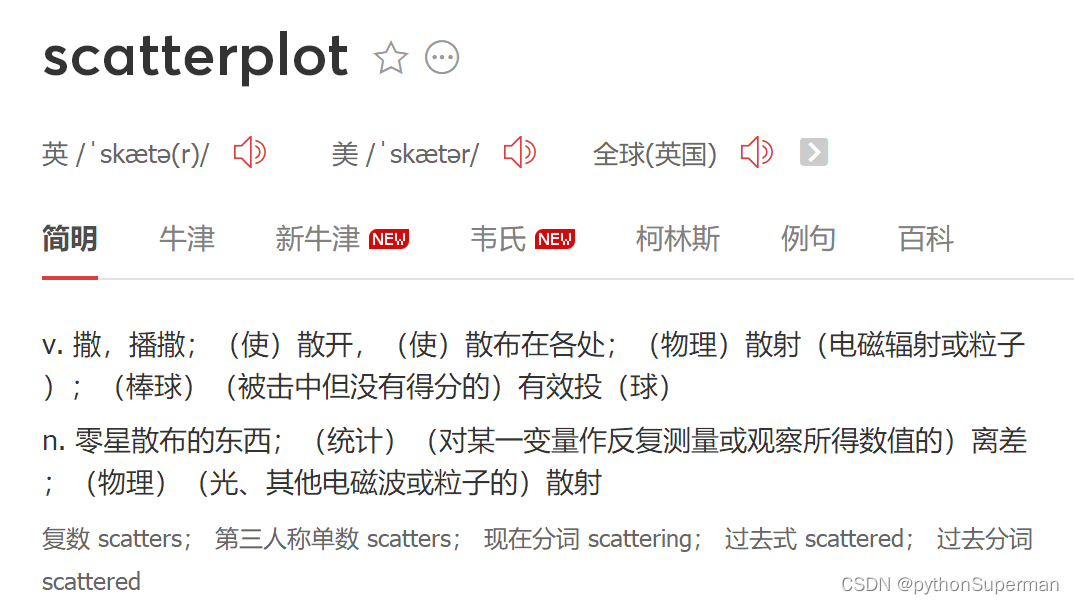
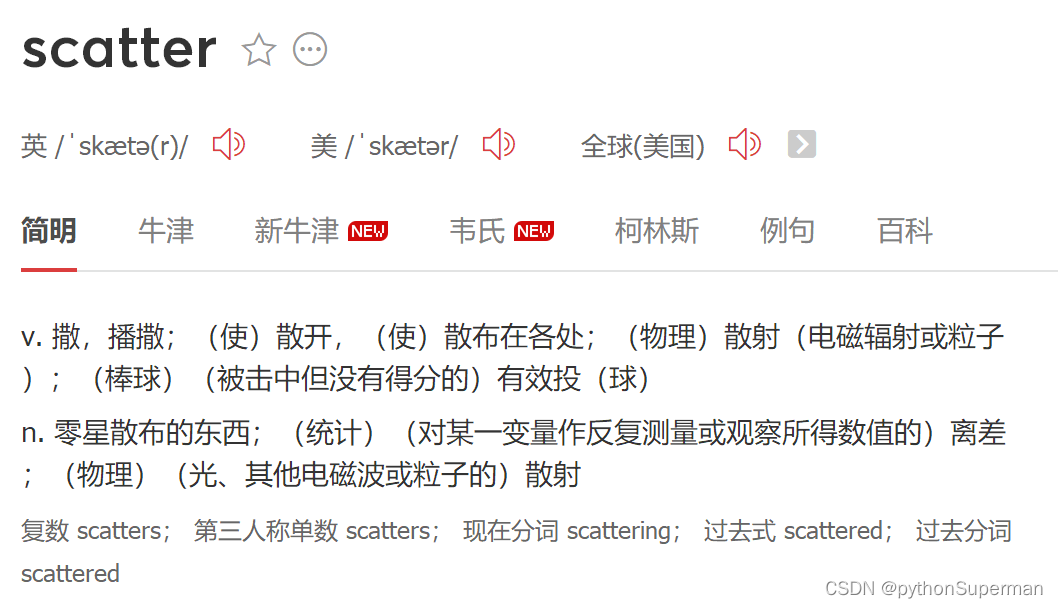
plt.scatter(df_women["height"], df_women["weight"])
#散点图的函数scatter(x周,y周)
#scatter只有绘图的功能,没有打印和展示图的功能
plt.title('女性体重与身高数据的可视化')
plt.xlabel('身高')
plt.ylabel('体重')
plt.show()plt.scatter(df_women["height"], df_women["weight"]) 等价于 plt.scatter(data = df_women, x= "height",y="weight")
(3)数据的规整化处理
也就是数据的准备,我们需要调用第三方的包和模块来解决问题,但是第三方的包和模块对数据的模态是有要求的,也就是我们在调用第三方的包和模块是需要把我们的数据转换成第三方的包和模块能接收的数据格式
#特征矩阵(X)的生成
#某个中括号前面有单词的话,“[]”肯定是对前面这个东西的切片
#把height给切出来
X = df_women["height"]
X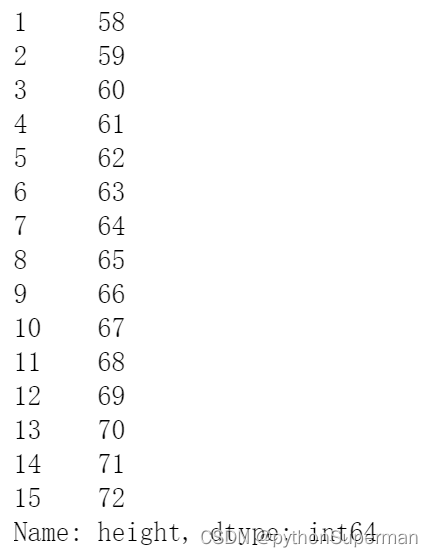
#目标向量(y)的生成
y = df_women["weight"]
y
(4)模型的训练
#特征矩阵的规整化处理
#每一个包对数据的模式和形态是有要求的,
'''我们的模型时y=ax+b,statsmodel在训练的时候只会训练a,不会训练b,为了防止出现这个情况并且让a和b都得到训练,我们需要在自变量也就是特征矩阵中增加一列,这一列的名字叫做const,而这一列全是1。计算机看到这一列1时明白了纪要计算a,也要计算b。'''
import statsmodels.api as sm
X=sm.add_constant(X)
#给X新增一列,列名【const】,每行的取值均为1.0
X 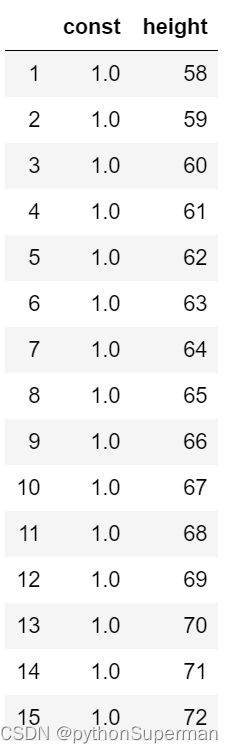
#构建模型
#OLS是最小二乘法的缩写ordinary least squares
myModel = sm.OLS(y, X)但是这个模型调用完之后,这个a和b还没有算出来,只是把X和y送给这个模型了
a和b算出来的这个过程叫做fit,fit的意思就是基于你的数据算出的参数
#模型拟合
#基于你的数据拟合出你的a和b
results = myModel.fit()
#a和b放在results的里面我们的模型已经训练好了,我们的模型叫做results
(5)模型的解读与评价
#summary把拟合后的情况告诉你
print(results.summary())
由上表得出:
weight = 3.4*h+(-87)
(DW统计量区间是[0,4],数值越靠近2越可靠)

#回归系数
results.params
#params属性找到你的系数和截距
#残差(residual)
results.resid 


#残差的标准差
results.resid.std() ![]()
#信任区间 (Confidence interval )
results.conf_int(alpha=0.025)
#R方
print("rsquared=",results.rsquared)

#F统计量的p值
results.f_pvalue ![]()
#DW统计量
sm.stats.stattools.durbin_watson(results.resid) 
#JB统计量
sm.stats.stattools.jarque_bera(results.resid)
#返回值有四个,分布为JB,JB的P值,锋度和偏度![]()
#可视化预测结果
y_predict=results.predict()
y_predict
plt.rcParams["font.family"] = 'Heiti TC'
# windows下
#plt.rcParams['font.family']="XimHei" #汉字显示
plt.plot(df_women["height"], df_women["weight"],"o")
plt.plot(df_women["height"], y_predict)
plt.title('女性体重与身高的线性回归分析')
plt.xlabel('身高')
plt.ylabel('体重') 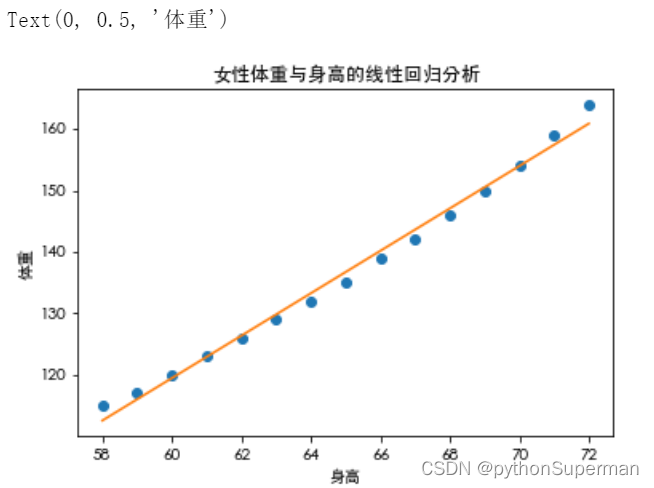



















 575
575

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









