







 本文深入探讨了Python内置高阶函数map()的使用方法,包括单参数和多参数的使用场景,以及如何利用map()进行类型转换和处理不一致长度的序列。同时,通过实例展示了如何规范化英文名字列表。
本文深入探讨了Python内置高阶函数map()的使用方法,包括单参数和多参数的使用场景,以及如何利用map()进行类型转换和处理不一致长度的序列。同时,通过实例展示了如何规范化英文名字列表。
map()函数
map()是 Python 内置的高阶函数,它接收一个函数 f 和一个 list,并通过把函数 f 依次作用在 list 的每个元素上,得到一个新的 list 并返回。
1、当seq只有一个时,将函数func作用于这个seq的每个元素上,并得到一个新的seq。
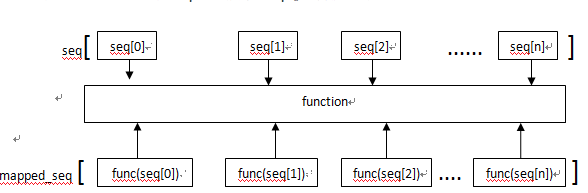
例如,对于list [1, 2, 3, 4, 5, 6, 7, 8, 9]
如果希望把list的每个元素都作平方,就可以用map()函数:
因此,我们只需要传入函数f(x)=x*x,就可以利用map()函数完成这个计算:
def f(x):
return x*x
print map(f, [1, 2, 3, 4, 5, 6, 7, 8, 9])
输出结果:
[1, 4, 9, 10, 25, 36, 49, 64, 81]
注意:map()函数不改变原有的 list,而是返回一个新的 list。
利用map()函数,可以把一个 list 转换为另一个 list,只需要传入转换函数。
由于list包含的元素可以是任何类型,因此,map() 不仅仅可以处理只包含数值的 list,事实上它可以处理包含任意类型的 list,只要传入的函数f可以处理这种数据类型。
假设用户输入的英文名字不规范,没有按照首字母大写,后续字母小写的规则,请利用map()函数,把一个list(包含若干不规范的英文名字)变成一个包含规范英文名字的list:
输入:['adam', 'LISA', 'barT']
输出:['Adam', 'Lisa', 'Bart']
def format_name(s):
s1=s[0:1].upper()+s[1:].lower();
return s1;
print map(format_name, ['adam', 'LISA', 'barT'])
2、当seq多于一个时,map可以并行(注意是并行)地对每个seq执行如下图所示的过程:
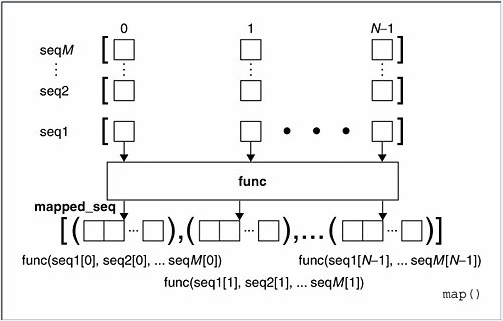
l2=map(lambda x,y:x**y,[1,2,3],[1,2,3])
for i in l2:
print(i)
l3=map(lambda x,y:(x**y,x+y),[1,2,3],[1,2,3])
for i in l3:
print(i)
python3中可以处理类表长度不一致的情况,但无法处理类型不一致的情况,
l4=map(lambda x,y:(x**y,x+y),[1,2,3],[1,2])
for i in l4:
print(i)
l4=map(lambda x,y:(x**y,x+y),[1,2,3],[1,2,'a'])
for i in l4:
print(i)
特殊用法,做类型转换:
l=map(int,'1234')
for i in l:
print(type(i))
print(i)
如果函数是 None,自动假定一个‘identity’函数,这时候就是模仿 zip()函数,
l=[1,2,3]
x=map(None,l)
print(x)
这时候 None 类型不是一个可以调用的对象。所以他没法返回值。
目的是将多个列表相同位置的元素归并到一个元组。如:
>>> print map(None, [2,4,6],[3,2,1])
[(2, 3), (4, 2), (6, 1)]
但是在 python3中,返回是一个迭代器,所以它其实是不可调用的

















 5208
5208

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









