







 本文介绍了朴素贝叶斯算法,包括贝叶斯公式、拉普拉斯平滑以及在Python中使用sklearn库的MultinomialNB实现。通过一个案例展示了如何对20Newsgroups数据集进行预处理、特征抽取并进行分类预测,计算出模型的准确率。
本文介绍了朴素贝叶斯算法,包括贝叶斯公式、拉普拉斯平滑以及在Python中使用sklearn库的MultinomialNB实现。通过一个案例展示了如何对20Newsgroups数据集进行预处理、特征抽取并进行分类预测,计算出模型的准确率。
目录
联合概率和条件概率

朴素贝叶斯-贝叶斯公式


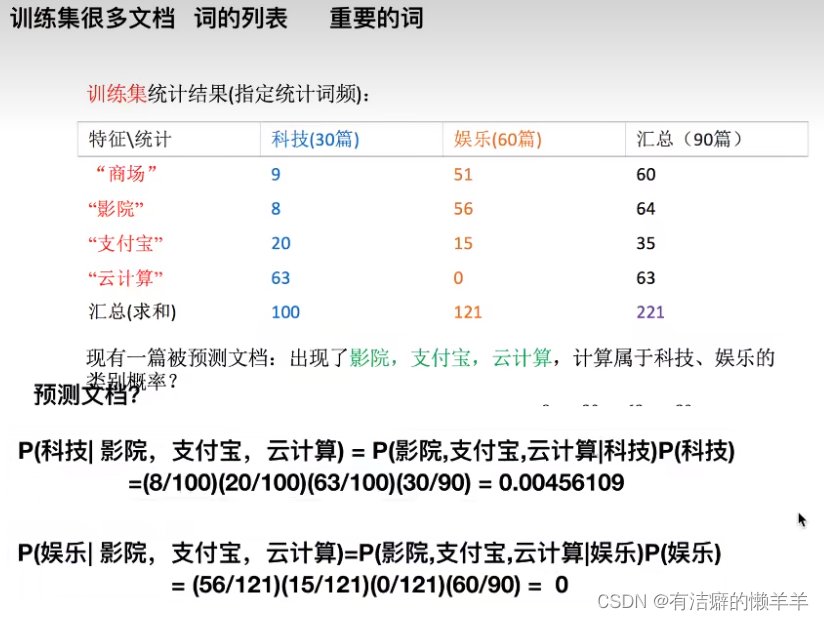
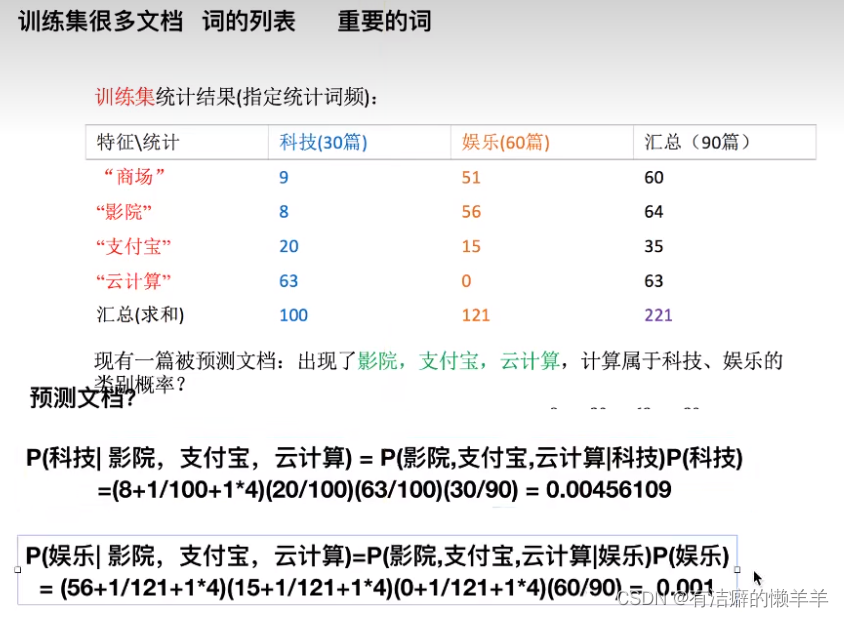
拉普拉斯平滑

sklearn朴素贝叶斯实现API
sklearn.naive_bayes.MultinomialNB

朴素贝叶斯算法案例
![]()
朴素贝叶斯案例流程

from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
def naviebayes():
"""
朴素贝叶斯进行文本分类
"""
news = fetch_20newsgroups(subset='all')
# 进行数据分割
x_train, x_test, y_train, y_test = train_test_split(news.data,news.target, test_size=0.25)
# 对数据集进行特征抽取
tf = TfidfVectorizer()
# 以训练集当中的词的列表进行每篇文章重要性统计['a','b','c','d']
x_train = tf.fit_transform(x_train)
x_test = tf.transform(x_test)
# 进行朴素贝叶斯算法的预测
mlt = MultinomialNB(alpha=1.0)
print(x_train.toarray())
mlt.fit(x_train, y_train)
y_predict = mlt.predict(x_test)
print("预测的文章类别为:", y_predict)
# 得出准确率
print("准确率:",mlt.score(x_test, y_test))
if _name_ == "_main_":
naviebayes()朴素贝叶斯训练集误差大,结果肯定不好
不需要调参
朴素贝叶斯分类优缺点



















 1578
1578

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









