




JMeter是一个功能强大的开源性能测试工具,它被广泛用于测试Web应用程序、Web服务、API、数据库以及其他类型的应用程序。
支持测试数据库的性能和可靠性,可以模拟多个并发用户对数据库执行各种不同类型的操作,例如查询、插入、更新和删除等。
这篇文章主要介绍测试数据库的基本方法。
jmeter下载地址:
Apache JMeter - Download Apache JMeter![]() https://jmeter.apache.org/download_jmeter.cgi
https://jmeter.apache.org/download_jmeter.cgi
1. jmeter 怎么测试数据库
测试数据库与测试web程序类似,web程序的测试需要提供接口,而数据库测试则需要提供依赖库和连接串来测试。
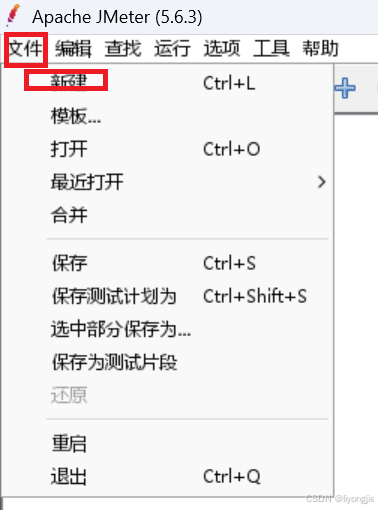
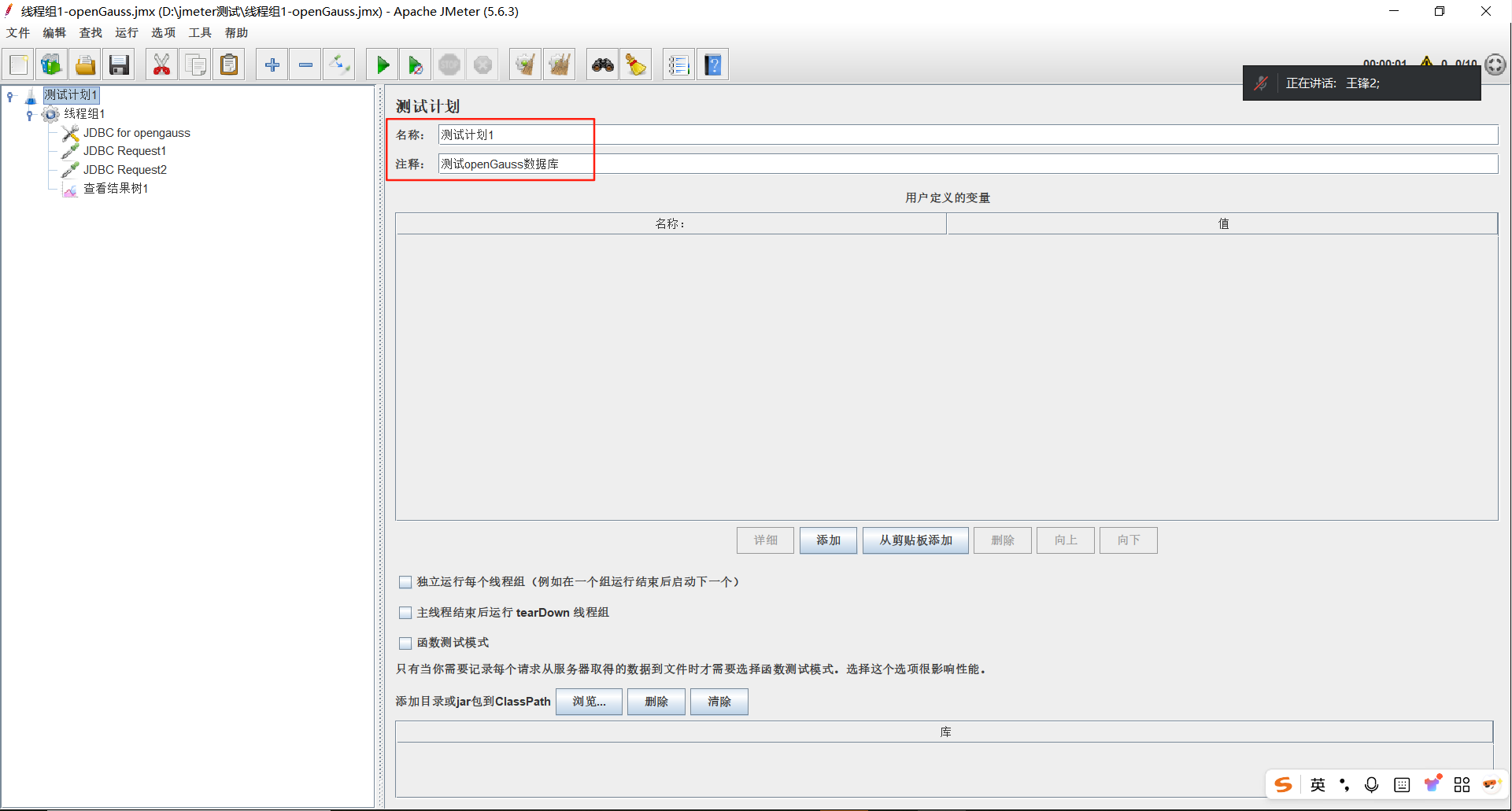
1.1新建测试计划
1.2线程组的介绍
在学习测试数据库之前需要了解什么是线程组?
线程组是用于模拟并发用户的行为,它是一组线程的集合,每个线程代表一个虚拟用户,可以并发执行相同或不同的测试请求。
在执行过程中,每个线程独立运行,按照指定的逻辑顺序发送请求并接收响应。线程组可以指定启动和停止时间,从而控制测试的持续时间。此外,线程组还可以设置启动延迟和循环计数,以增加测试的复杂性和真实性。通过如下步骤添加:
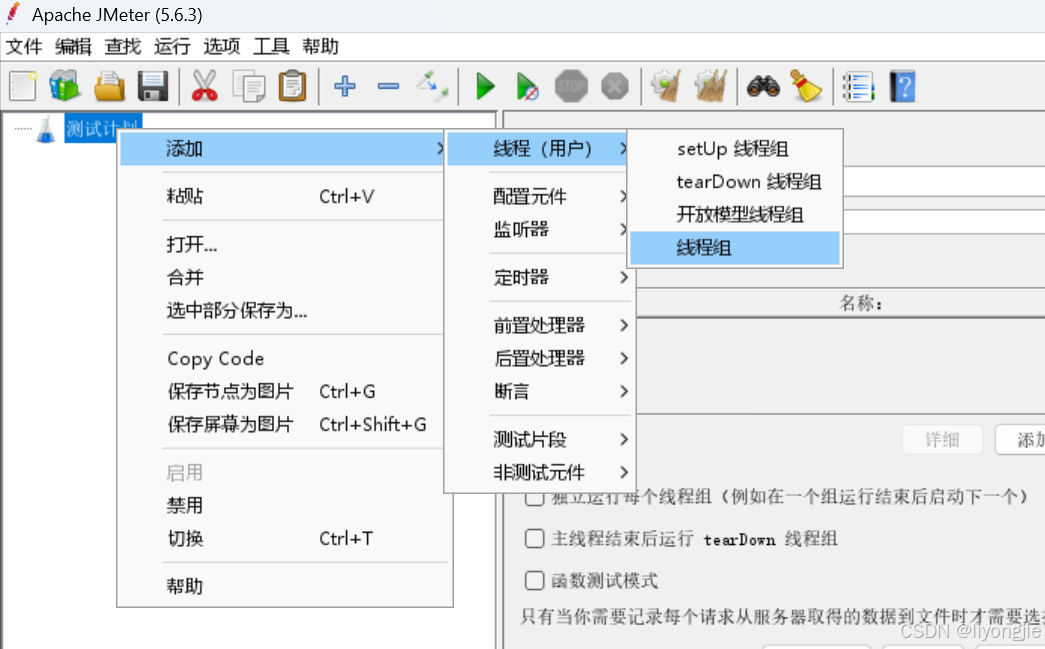
右击测试计划 → 添加 → 线程(用户) → 线程组
串行测试通常按如下配置:
并发测试通常按如下配置:
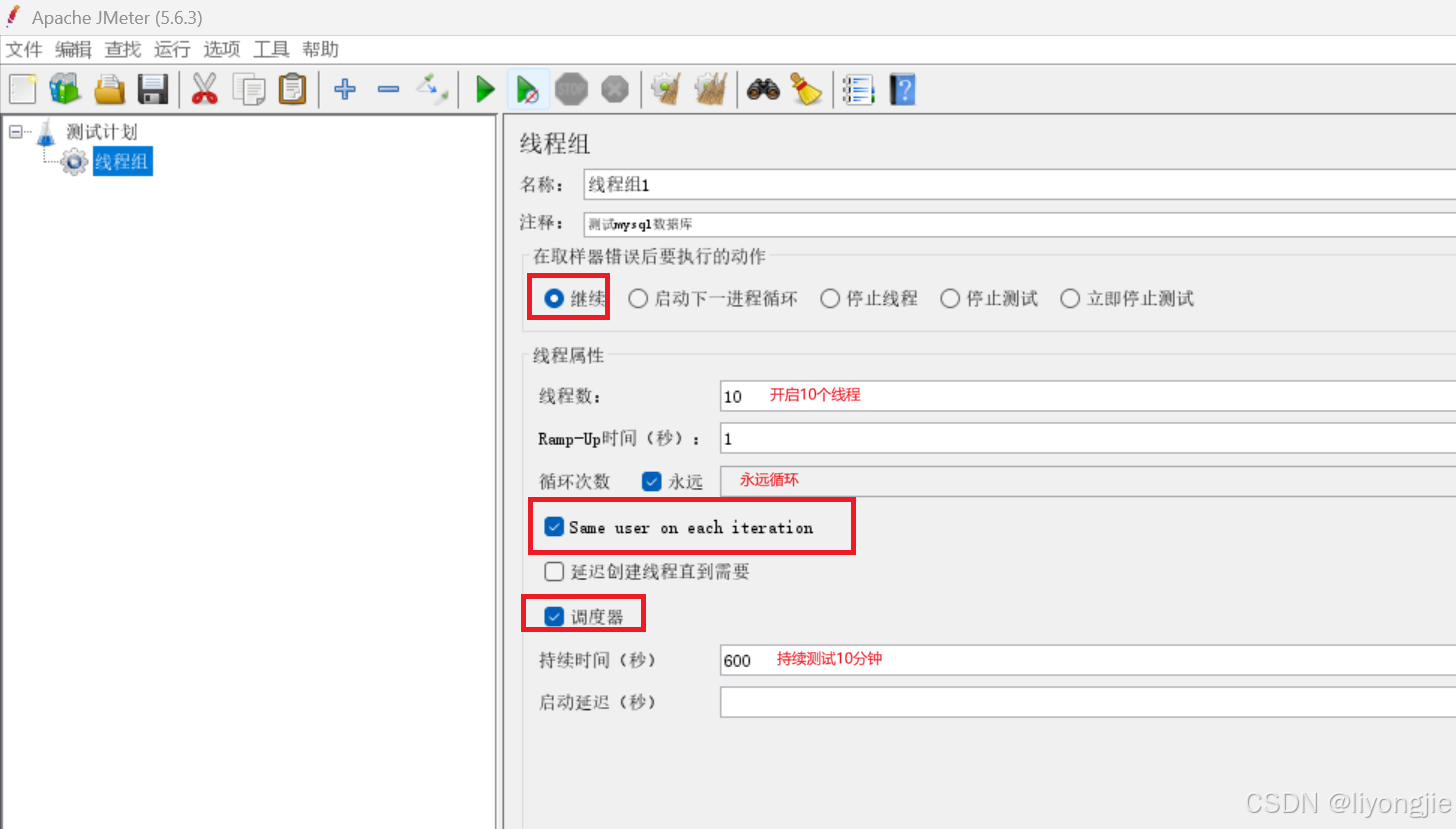
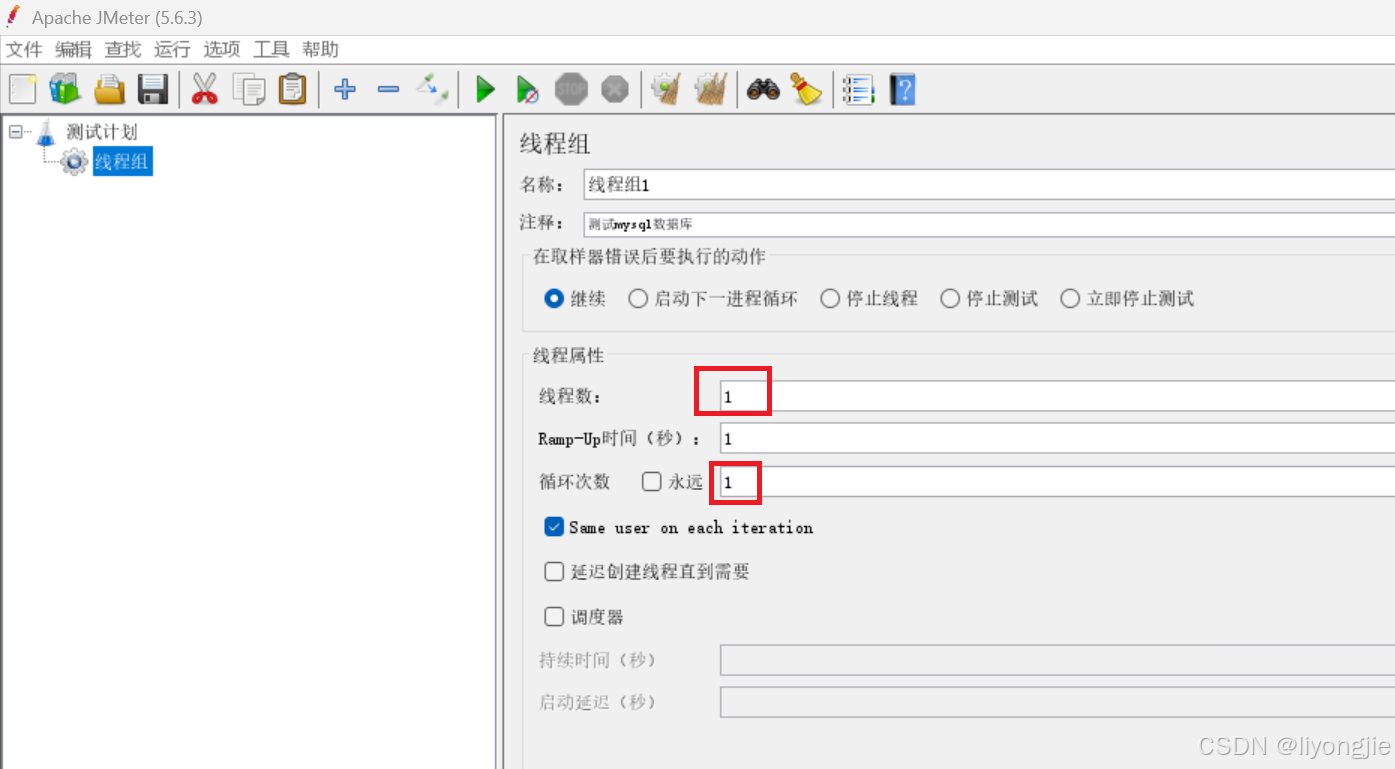
它的整体界面由3部分组成:名称设置、异常设置、线程设置。
【第1部分】名称设置
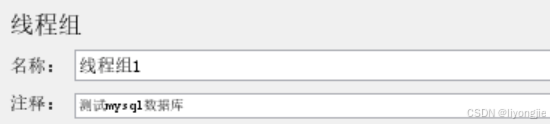
- 名称:表示这一组业务的名字,比如可以修改为 "用户登录"、"用户购物"等。
- 注释:名称用宏观的方式来写,那么注释就是把业务的一些细节写上去,便于理解。
【第2部分】异常设置
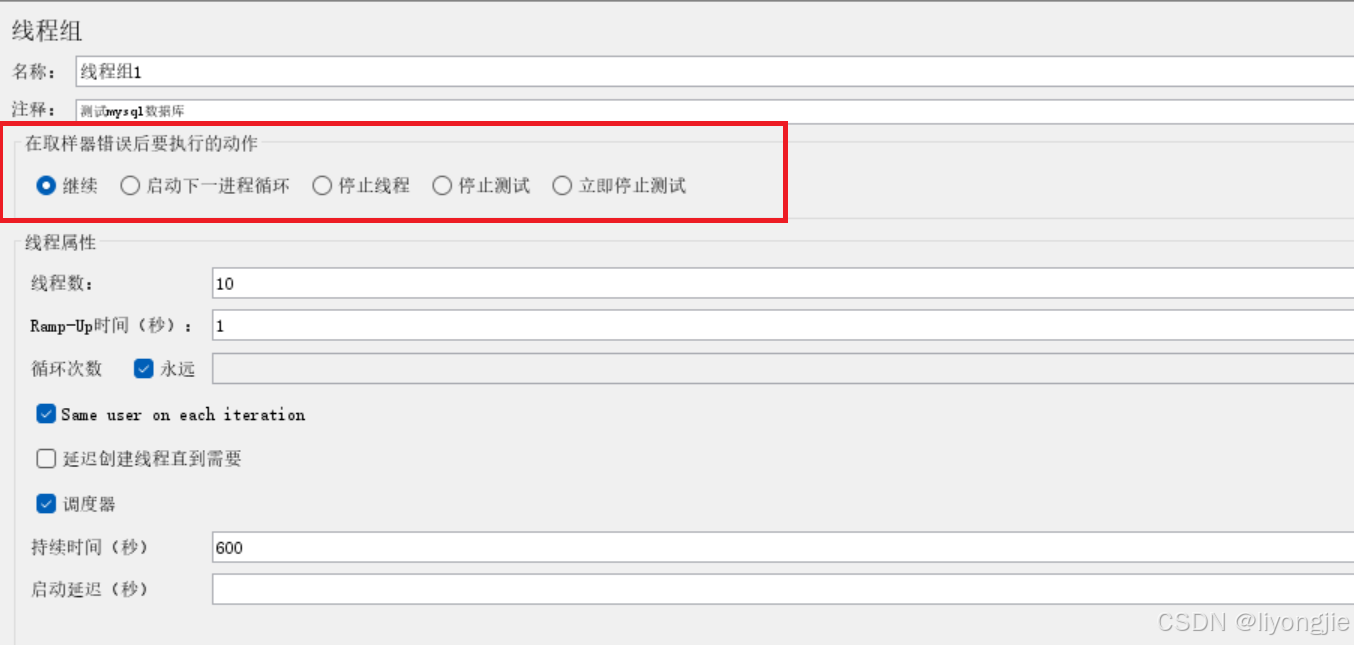
- 继续:无论当前取样器是否执行成功或失败,都会继续执行下一个取样器。
- 启动下一进程循环:即使当前线程组中有其他线程在运行,也会立即启动新的线程循环。
- 停止线程:当测试计划中有多个线程组,在停止当前线程之后,其他线程组将继续执行。
- 停止测试:停止整个测试计划。
【第3部分】线程设置
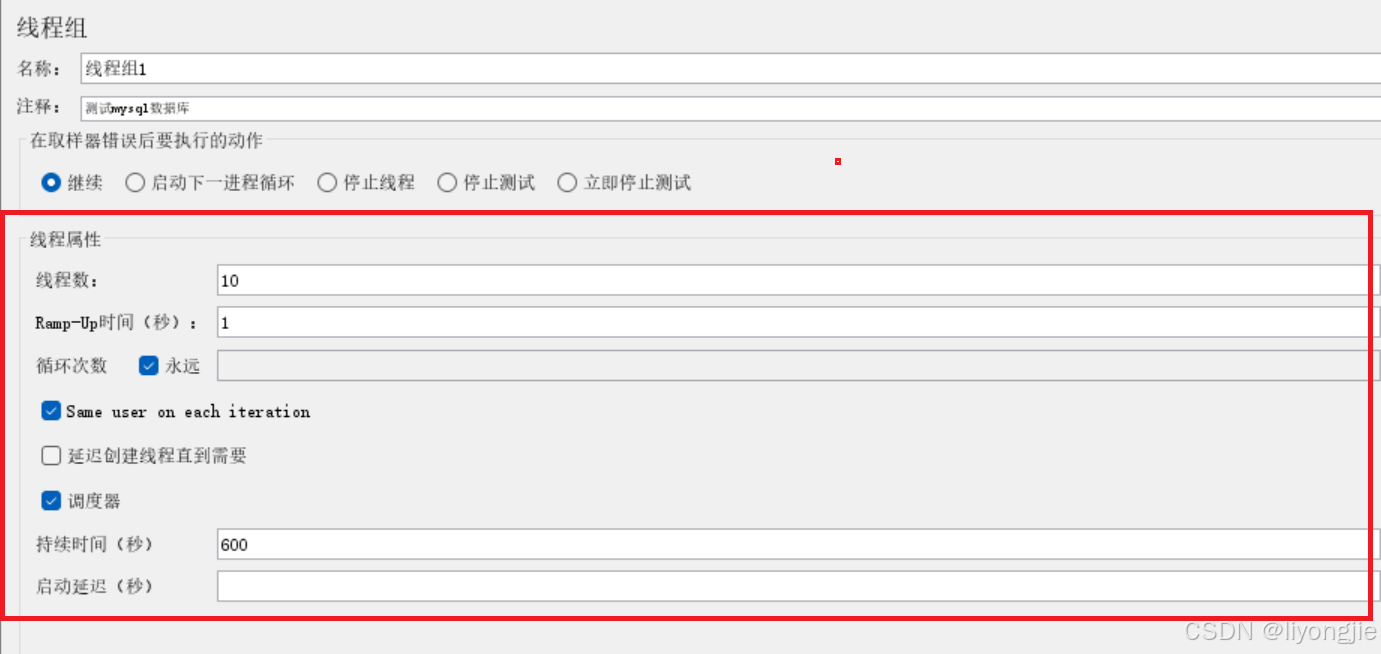
- 线程数:模拟用户的并发数。接口测试一般1个就行,压测就根据情况而定。
- Ramp-Up时间:指定启动所有线程所需的时间。例如设置为5秒,且有10个线程,则每秒启动2个线程,直到所有线程都被启动。
- 循环次数:每个线程循环的次数。例如设置线程2个,循环10次,那么业务就会执行20次。如果是压测的话勾选永远,再使用调度器指定测试时间。
- Same user on each iteration:每个迭代使用相同的用户。
- 延迟创建线程直到需要:自动周期性控制。
- 调度器:一般压测需要勾选调度器,指定压测的时长。
1.3数据库连接配置
在学习线程组后,第2步需要了解数据库怎么连接。
数据库通过配置元件中的《JDBC Connection Configuration》去连接,添加步骤如下:
右击测试计划 → 添加 → 配置元件 → JDBC Connection Configuration

配置 MySQL 示例
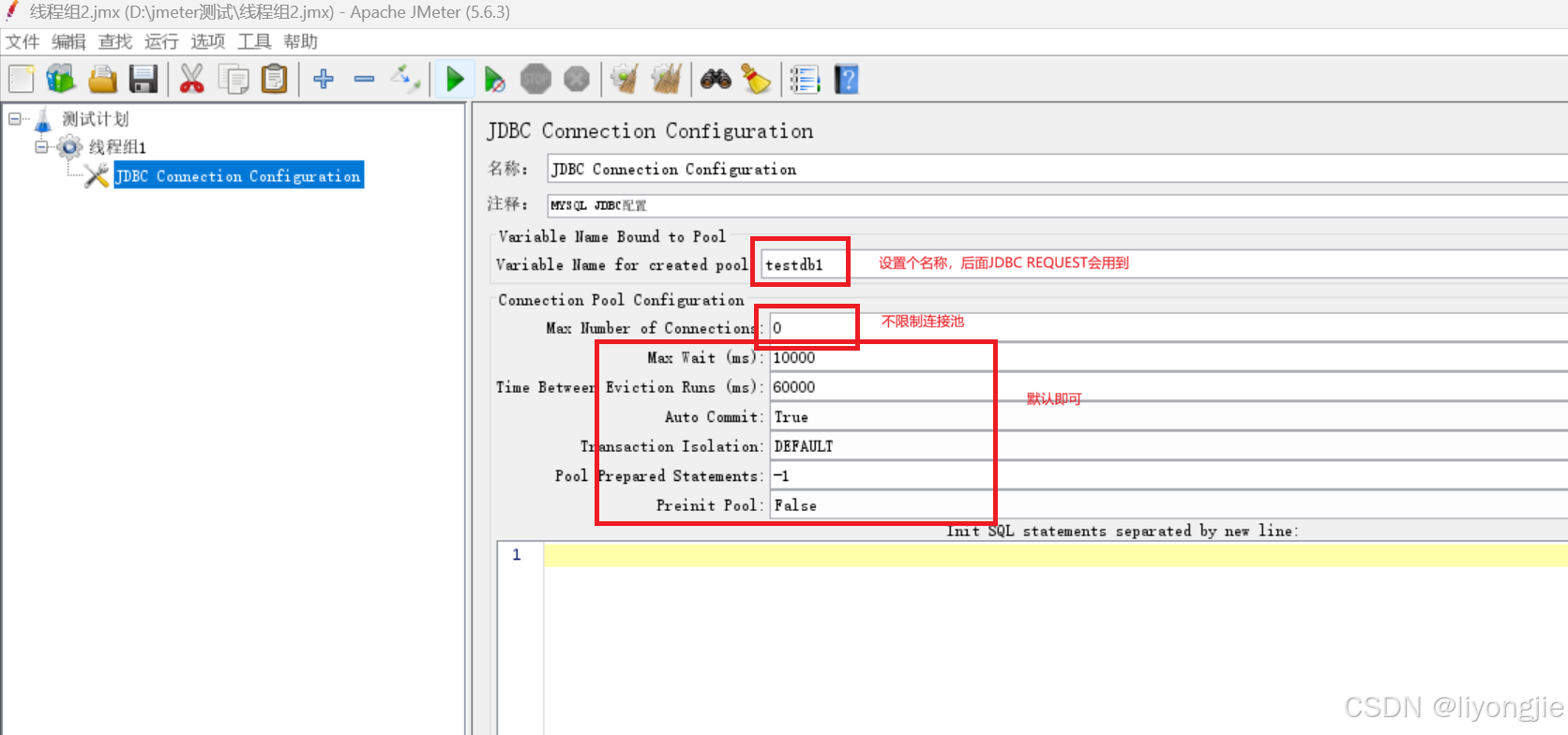
MYSQL JDBC配置:
jdbc:mysql://localhost:3306/mysql
com.mysql.jdbc.Driver测试其他数据库只需要修改对应的连接串和驱动即可:
"""MySQL"""
URL:jdbc:mysql://[IP]:[端口]/[数库名] # jdbc:mysql://localhost:3306/mysql
Driver:com.mysql.jdbc.Driver"""Oracle"""
URL:jdbc:oracle:thin:@[IP]:[端口]:[数库名] #jdbc:oracle:thin:@localhost:1521:orcl
Driver:oracle.jdbc.OracleDriver"""PostgreSQL"""
URL:jdbc:postgresql://[IP]:[端口]/[数库名] # jdbc:postgresql://localhost:5432/postgres
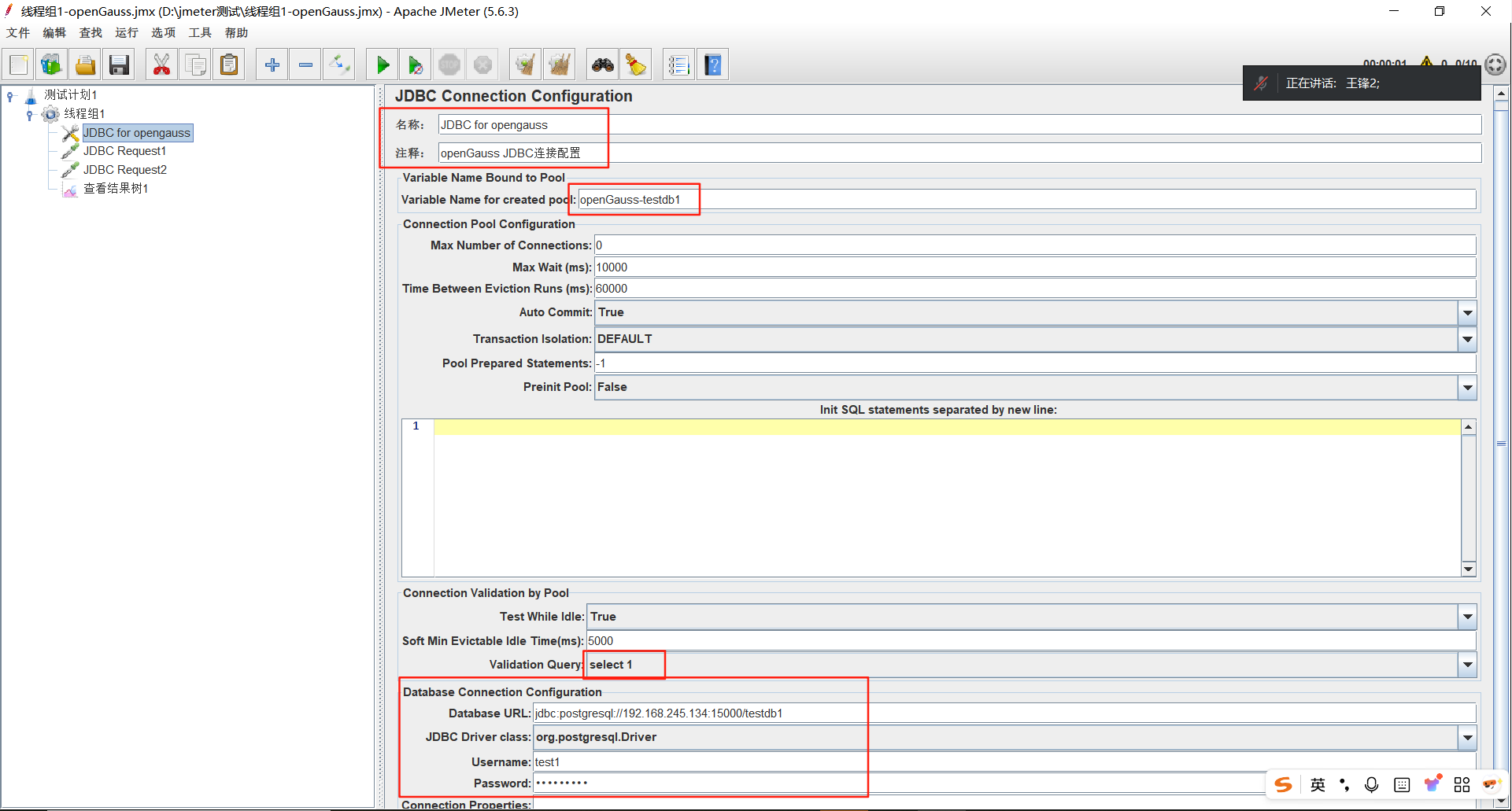
Driver:org.postgresql.Driver它的整体界面由5部分组成:名称、配置变量、连接池、连接验证和数据库配置
【第1部分】名称

这里的名称和注释和线程组的名称是一个意思,自定义名称即可。这里的JDBC连接配置指的是:jmeter 通过JDBC来访问数据库,访问时数据库查询的接口便是JDBC。
【第2部分】配置变量
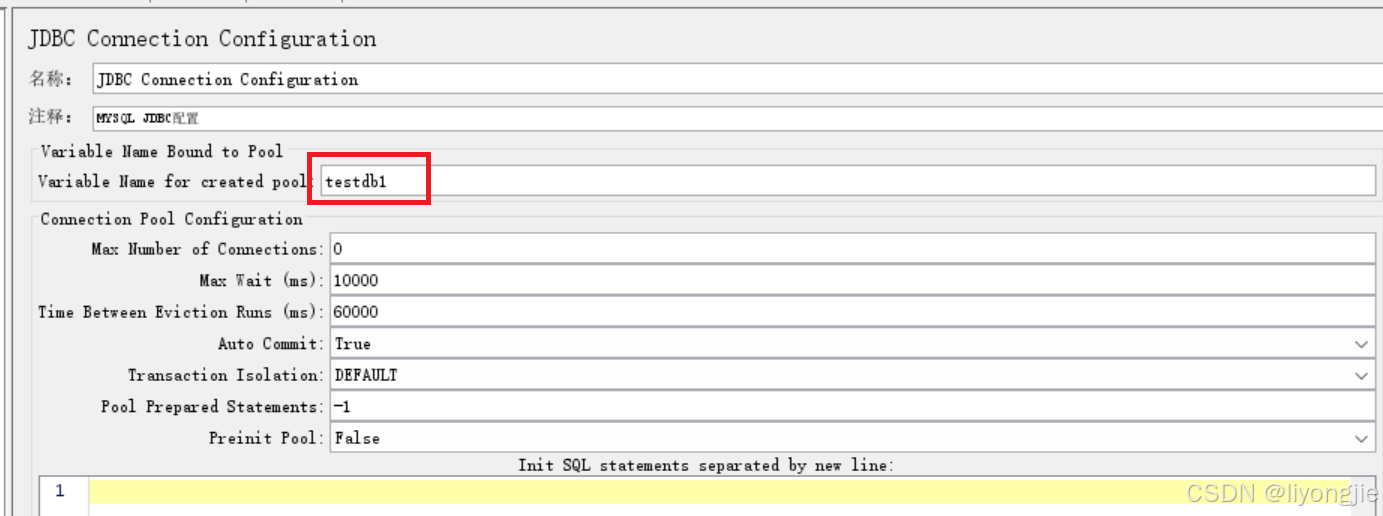
我们需要在标注的红框中填写一个自定义的变量名,可以是aaa,也可以是bbb(名称自定义),变量的作用就是后续测试的引用。
比如当需要测试一条业务 select 1; 时,那么需要向对应的数据库发起请求,而发起请求是需要一些提供一些数据库参数的。所以我们在《JDBC Connection Configuration》中已经配置好了数据库的连接方式,那么在其他业务中直接引用这个配置即可,而引用的方式就是自定义的变量。
【第3部分】连接池
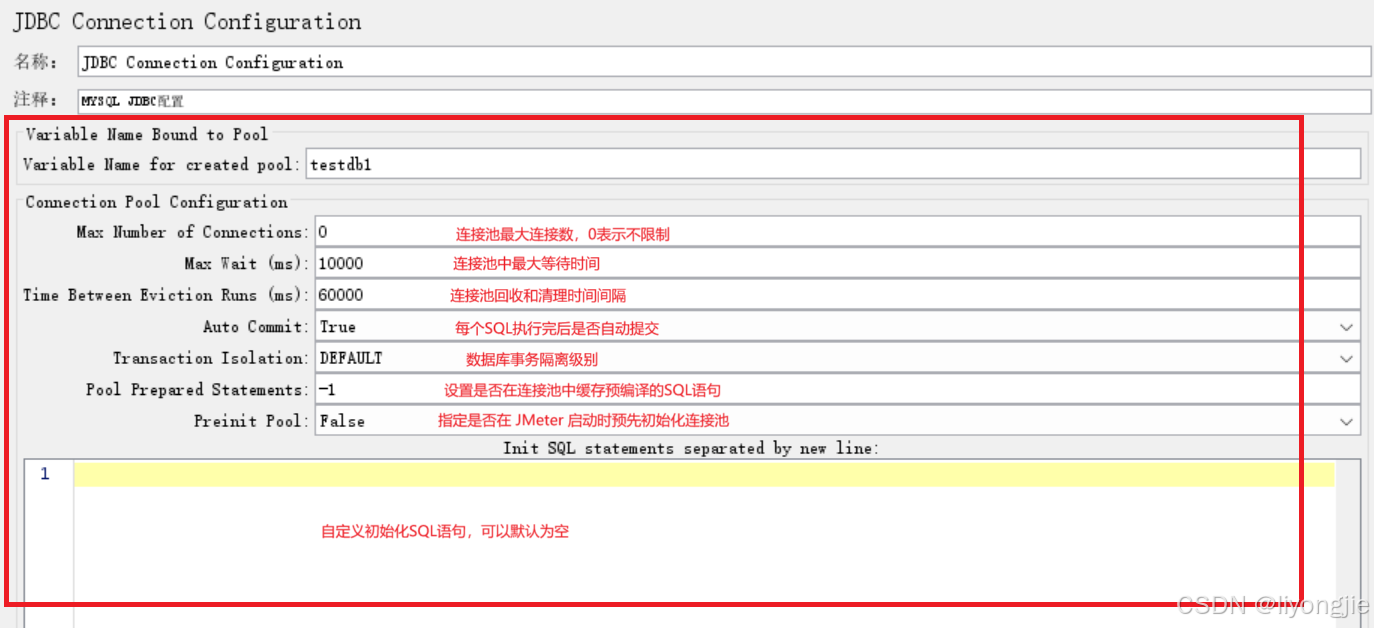
- Max Number of Connections:设置连接池中的最大连接数(0表示不限制最大连接数),超过此数量的请求将在等待队列中等待连接资源。连接池是一种管理数据库连接的机制,它允许应用程序共享和重复使用连接,从而提高性能和效率。
-
Max Wait (ms):设置在连接池中等待可用连接时的最大等待时间。当测试中的并发用户线程请求数据库连接时,如果所有的连接已经被占用且没有空闲连接可用,那么新的连接请求会被放入一个等待队列中,Max Wait (ms)定义了在该队列中等待连接的最长时间。如果超过了设定时间仍然无法获取连接,则等待的请求将会放弃并继续执行其他操作。
-
Time Between Eviction Runs (ms):设置连接池中进行连接回收和清理的时间间隔(0表示禁用连接回收和清理机制)。连接池中的连接在使用过程中可能会因为各种原因变得无效,例如连接超时、数据库关闭等。为了保持连接池的健康和性能,需要定期回收和清理这些无效的连接。
- Auto Commit:设置是否在每个SQL语句执行之后自动提交事务。True:每个SQL语句在执行完之后会立即自动提交事务。False:需要手动调用提交命令来提交事务。
-
Transaction Isolation:设置数据库事务的隔离级别。
DEFAULT:使用数据库默认的事务隔离级别。
READ_UNCOMMITTED(读取未提交的数据):事务可以读取其他事务未提交的数据。该隔离级别提供了最低的数据一致性和最高的并发性,但也可能出现脏读、不可重复读和幻读等问题。
READ_COMMITTED(读取已提交的数据):事务只能读取其他事务已经提交的数据。该隔离级别保证了脏读的防止,但仍可能出现不可重复读和幻读的问题。
REPEATABLE_READ(可重复读取):事务在整个事务过程中可以多次读取相同的数据,并且其他事务不能对其进行更新。该隔离级别保证了脏读和不可重复读的防止,但仍可能出现幻读的问题。
SERIALIZABLE(串行化):事务之间完全串行执行,确保了最高的数据一致性,但同时也可能导致并发性能下降。 - Pool Prepared Statements:设置是否在连接池中缓存预编译的SQL语句(可以提高性能和安全性)。如果设置了预编译语句,JMeter会在连接池中缓存预编译的SQL语句,并在需要时复用。如果设置为-1,则每次执行SQL语句时都会重新编译。
-
Preinit Pool:指定是否在 JMeter 启动时预先初始化连接池。若设置为 True,JMeter 在启动时会在连接池中预先初始化一定数量的连接。在测试执行过程中,使用数据库连接的操作就可以直接获取到已经预先初始化的连接,而无需在运行时创建新的连接。这种预先初始化的方式可以显著减少数据库连接的创建时间,提高性能,并减轻数据库的负载。
- 初始化sql框:允许按照每行一个 SQL 语句的格式提供多个初始化语句,每行的 SQL 语句都将在连接建立之后按照顺序执行。这些 SQL 语句可以包括一些初始化或准备工作,例如设置连接的字符集、创建临时表、加载数据库函数、设定连接的隔离级别等。
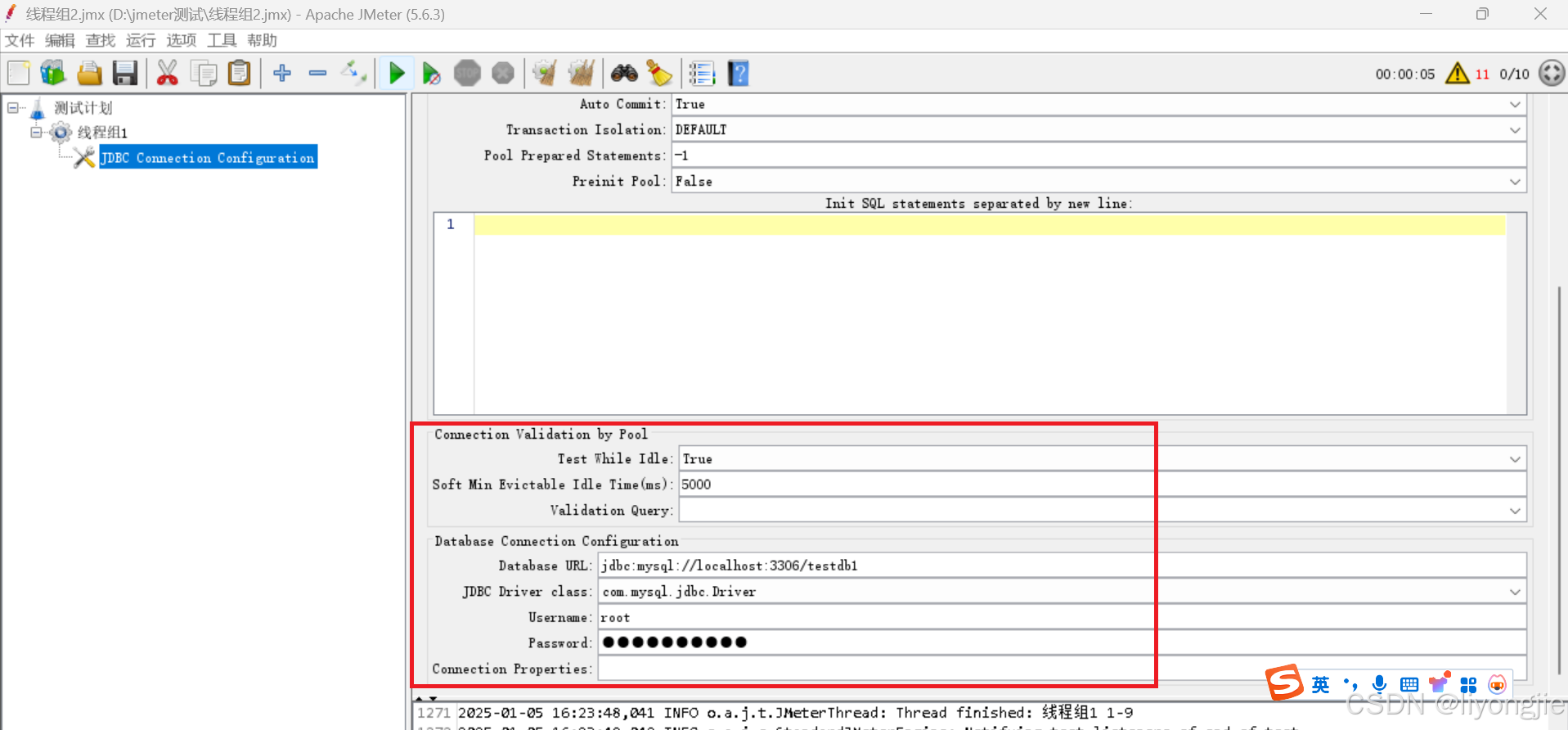
【第4部分】连接验证

- Test While Idle:指定是否在连接处于空闲状态时进行测试(也就是没有被使用的状态)。True 需要配置下面2个选项。
-
Soft Min Evictable Idle Time(ms):指定连接在空闲状态下被认为是可回收的最短时间。连接池中的连接在使用完毕后,如果处于空闲状态一段时间,可以被回收并释放资源。Soft Min Evictable Idle Time (ms) 选项定义了一个最小的空闲时间,当连接空闲时间超过这个阈值时,连接可以被回收。通过合理设置该选项的值,可以控制连接池中连接的空闲回收策略,平衡资源利用和性能开销。
- Validation Query:指定在测试数据库连接时执行的验证查询语句,一般使用最简单的语句,比如 select 1
【第5部分】数据库配置

- Database URL:设置连接到数据库服务器的 URL。包括数据库服务器的主机名、端口号、数据库名称以及其他连接参数。
- JDBC Driver class:指定数据库驱动程序的类名。
- Username:连接数据库的用户名。
- Password:数据库用户的密码。
-
Connection Properties:设置额外的连接属性,定制数据库连接的行为,可以针对特定的连接需求进行优化和调整。
characterEncoding: 字符编码,用于设置数据库连接的字符集编码。
ssl: 是否启用 SSL 加密连接。
fetchSize: 数据库查询时一次性从结果集中获取的记录数量。
maxRows: 结果集的最大行数限制。
loginTimeout: 登录超时时间,即连接到数据库服务器的最大等待时间。
1.4 数据库业务构造
jmeter 通过取样器中的《JDBC Request》来实现业务,添加步骤如下:
- 右击线程组 → 添加 → 取样器 → JDBC Request
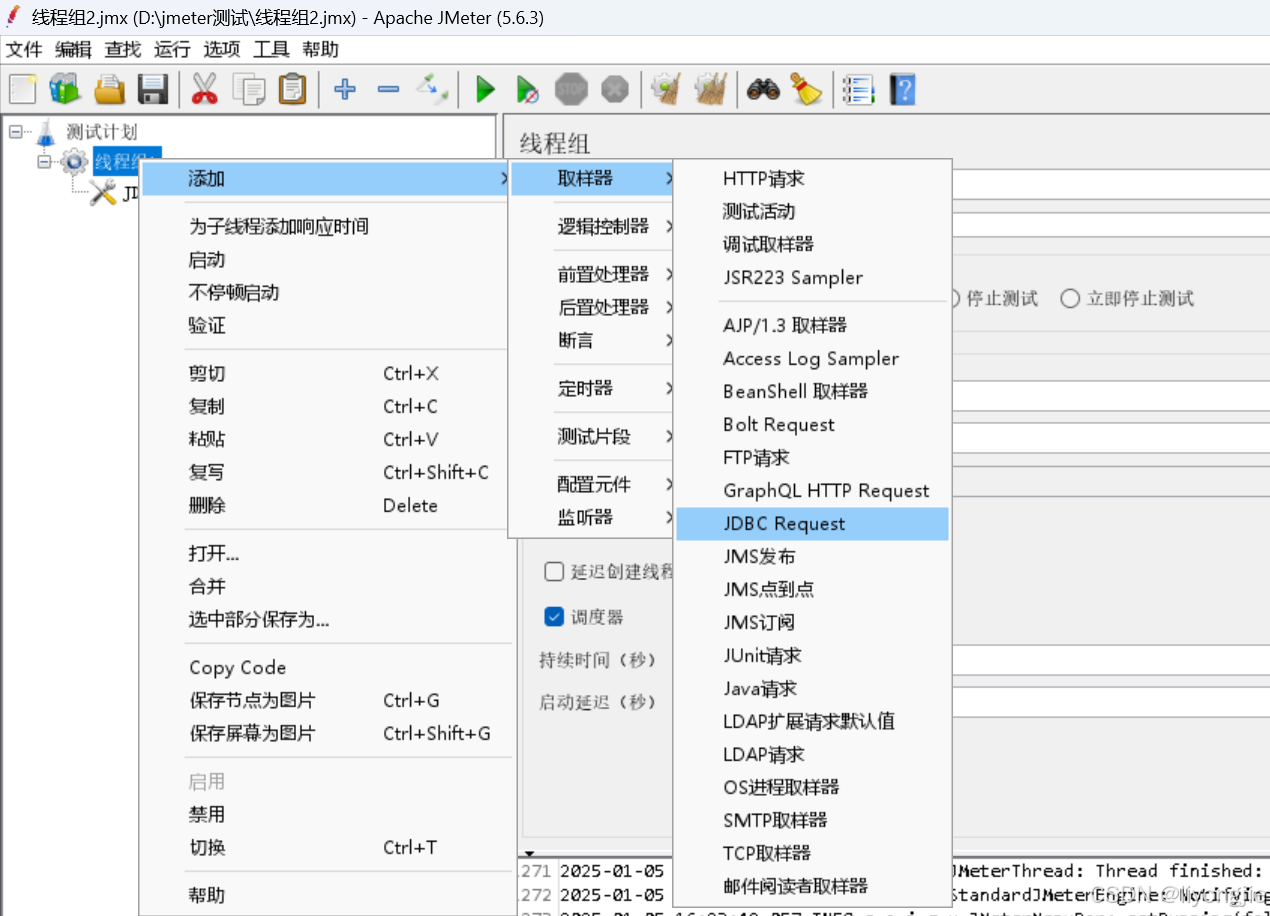
MySQL 业务示例
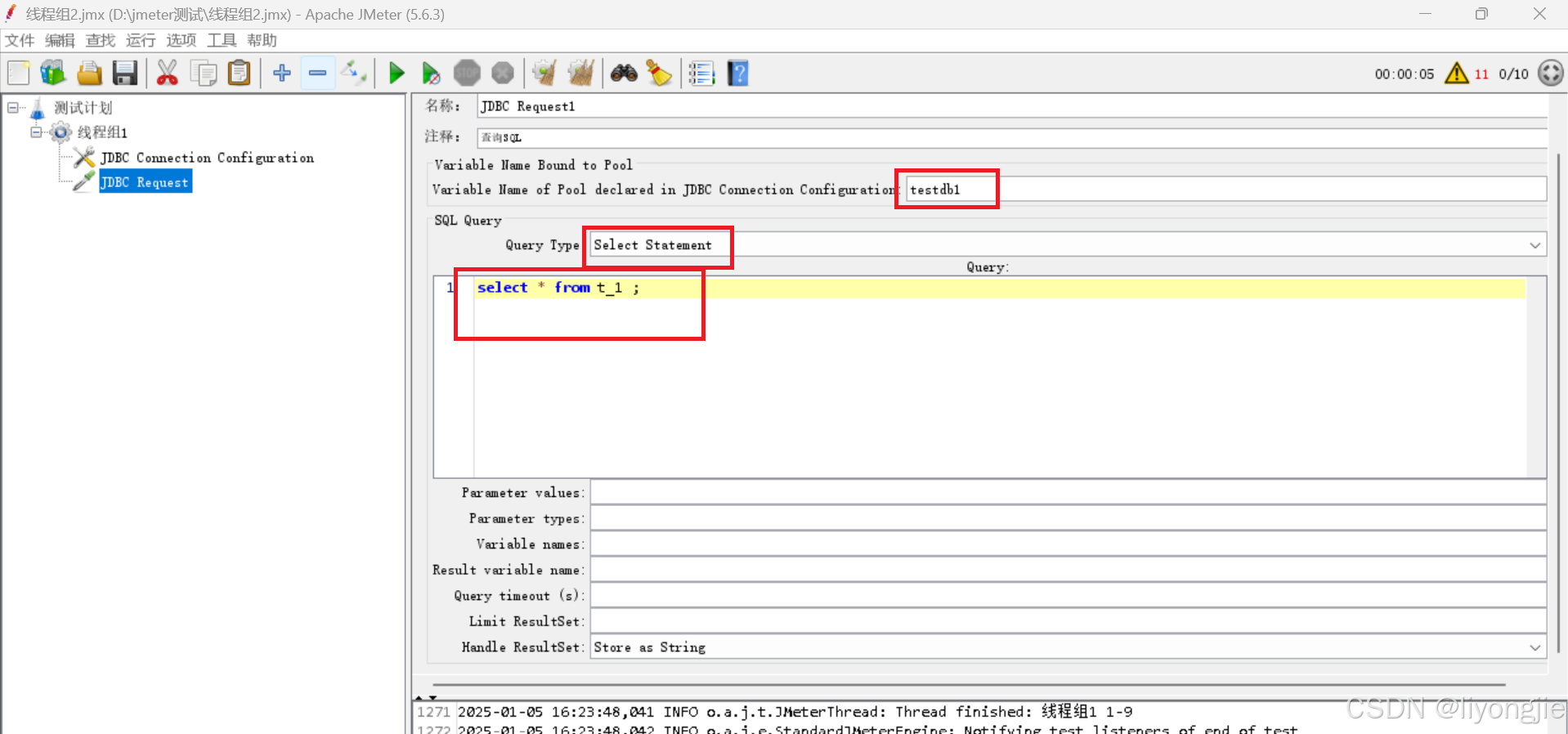
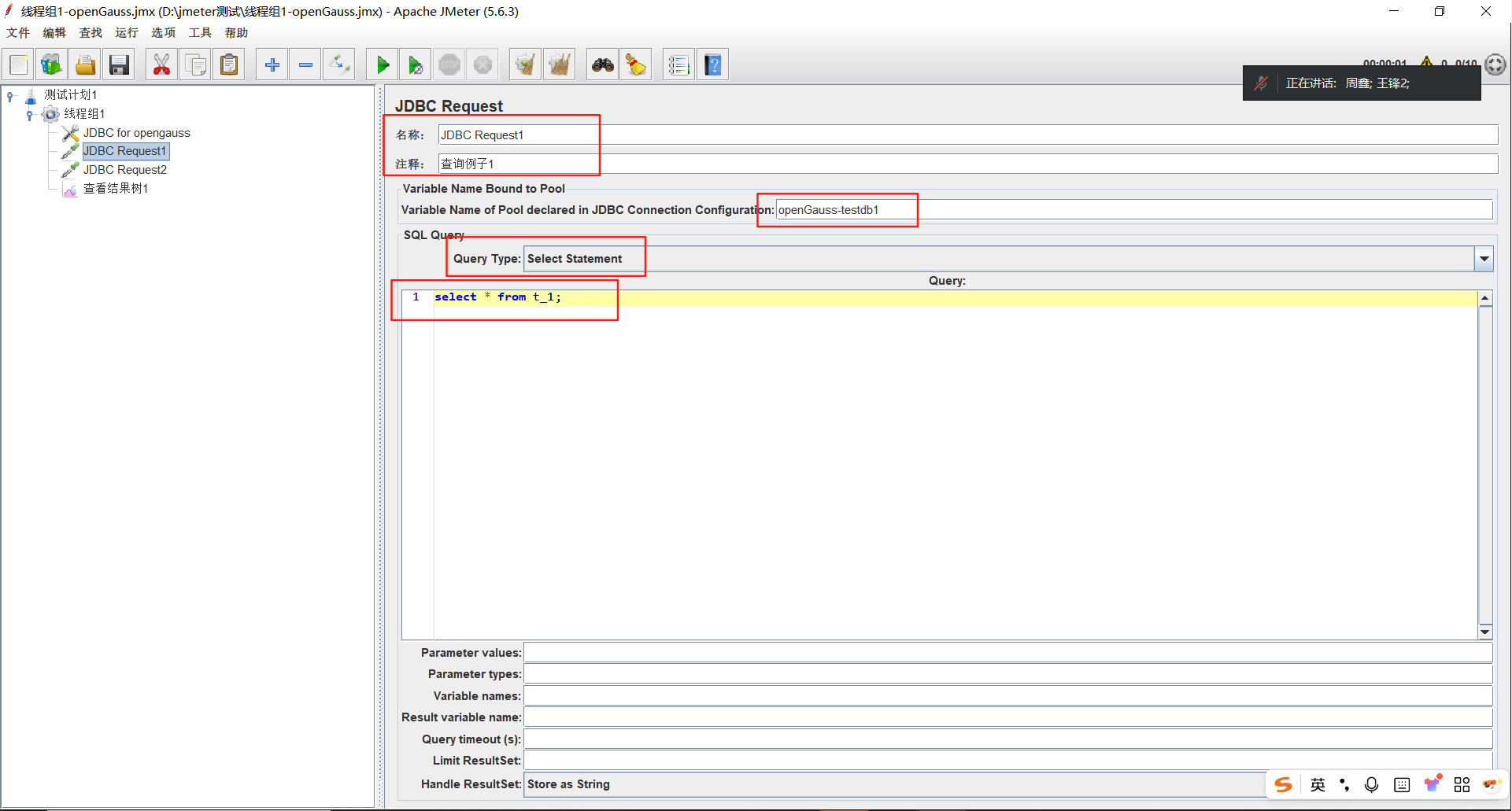
它的整体页面由4部分组成:名称、JDBC引用配置、SQL业务、其他属性。
【第1部分】名称

这里的名称和注释和线程组的名称是一个意思,自定义名称即可。
【第2部分】JDBC引用配置

这个名称要和:《JDBC Connection Configuration》中配置一致
【第3部分】SQL业务
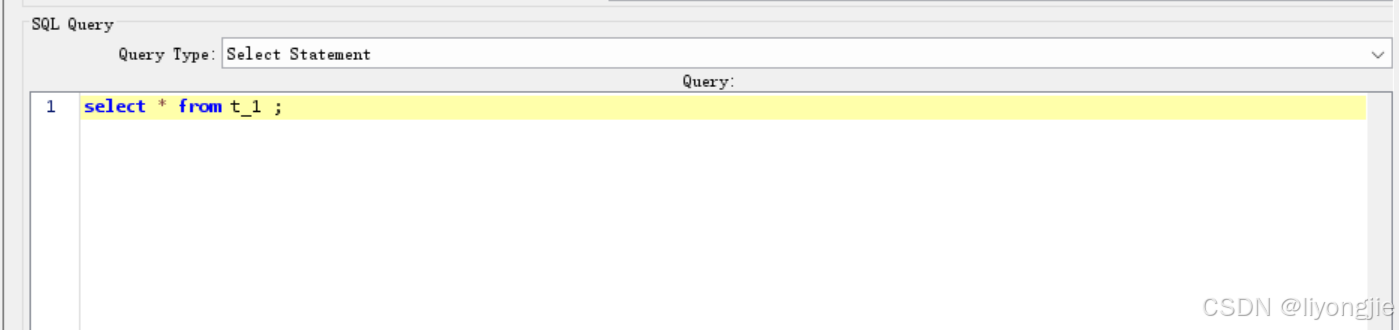
SQL 类型说明如下:
- Select Statement:执行1条数据库查询语句,例如 SELECT、FROM、WHERE、JOIN 等。
- Update Statement:执行1条数据库更新语句,例如 修改、删除或插入等。
- Callable Statement:调用1条已定义的存储过程或函数的接口,例如 CALL 存储过程名()。
-
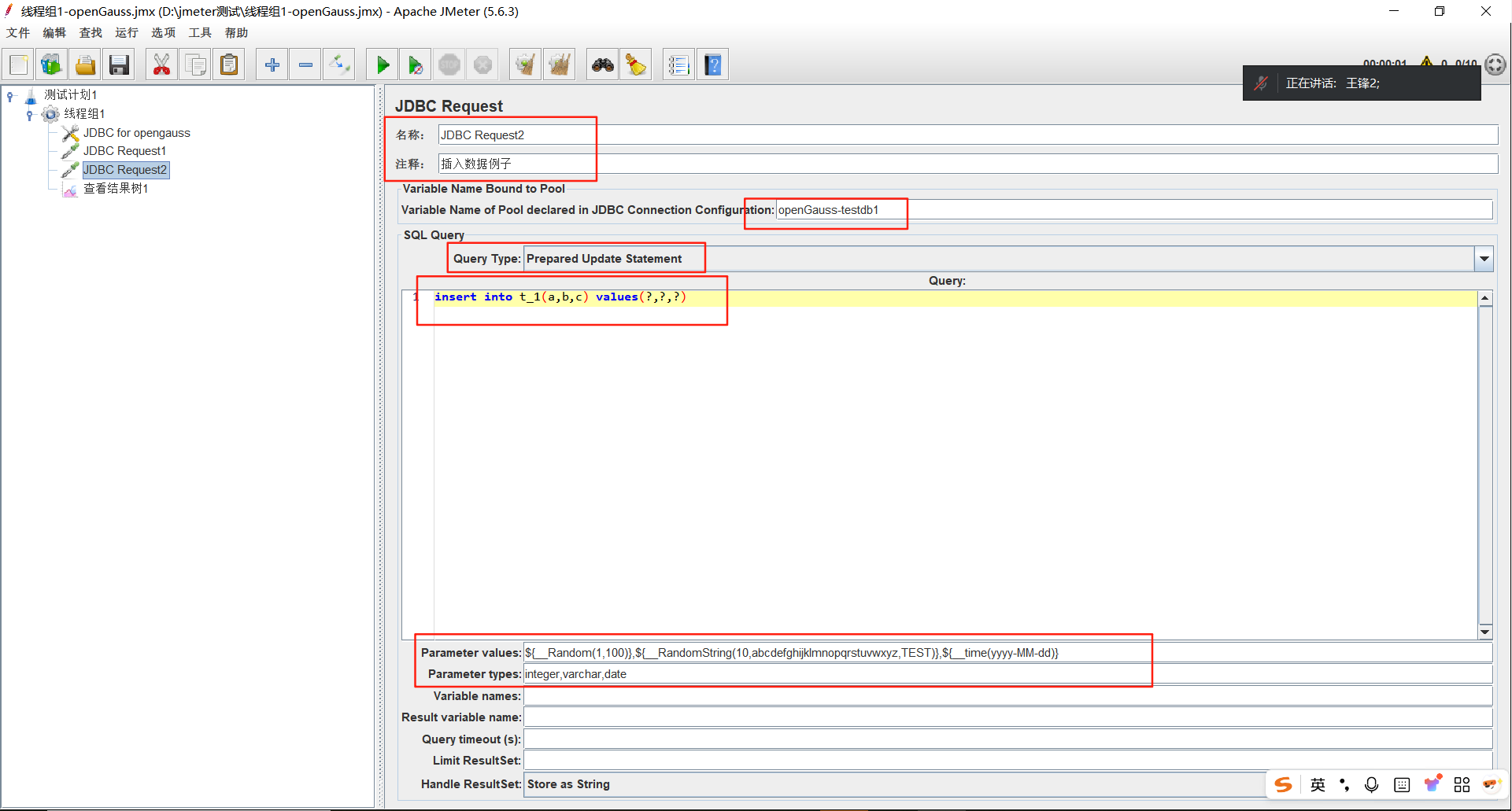
Prepared Select Statement:编写具有占位符的SQL查询语句,例如 SELECT * FROM t1 WHERE id < ? AND num > ?; 使用问号表示参数占位符,在 "Parameter Values" 中按顺序输入值(多个值以逗号分割),并在 "Parameter types" 中指定类型。
- Prepared Update Statement:与上面 "Prepared Select Statement" 的作用一样,支持修改、删除和插入语句,不支持查询。
- Commit:指定1个提交事务的操作。在使用 “Commit” SQL类型时,需要确保数据库连接以及之前的数据库操作都是在同一个事务中。提交操作只有在事务处于活动状态时才会起作用。如果没有使用到事务或没有进行相应的数据库操作,那么 “Commit” 操作将不会产生任何效果。
- Rollback:指定1个回滚事务的操作。方式与上面 "Commit" 类似。
- AutoCommit(false):禁用自动提交模式(禁止自动将每个SQL操作作为一个单独的事务提交到数据库中)。
- AutoCommit(true):启用自动提交模式(每个SQL操作都会立即提交到数据库中)。
【第4部分】其他属性

- Parameter values:指定 SQL 语句中的参数值的属性。比如语句为 select * from t1 where id = ?; 这里就是对问号指定参数值,比如10或者jmeter内置变量等(多个参数用逗号分割)。
- Parameter types:指定参数类型,与上面的 "Parameter values" 一起使用,比如参数为数字,这里类型就是Integer;参数为字符,类型为varchar。
- integer: 整数类型,用于表示整数参数值。
- long: 长整数类型,用于表示长整数参数值。
- float: 浮点数类型,用于表示浮点数参数值。
- double: 双精度浮点数类型,用于表示双精度浮点数参数值。
- varchar: 字符串类型,用于表示字符串参数值。
- boolean: 布尔类型,用于表示布尔参数值(true或false)。
- date: 日期类型,用于表示日期参数值。
- time: 时间类型,用于表示时间参数值。
- timestamp: 时间戳类型,用于表示时间戳参数值。
- Variable names:指定SQL查询的结果集中的列名,以便提取和存储这些结果的属性。通过设置这个属性,可以将查询结果的特定列值存储到JMeter变量中,以供后续的处理和验证使用。
- Result variable name:指定 SQL 查询的结果集的变量名,以便将整个结果集存储到一个变量中。
-
Query timeout (s):设置SQL查询的超时时间的属性。这个属性可以控制JMeter等待SQL查询的时间,如果查询在指定的超时时间内没有完成,JMeter将中断查询并报告超时。在某些情况下,SQL查询可能需要很长时间才能完成,例如查询大量的数据或执行复杂的操作。通过设置合适的查询超时时间,可以防止JMeter长时间等待查询结果而导致整个测试计划停顿或耗费过多的资源。
- Limit ResultSet:用于限制结果集的大小。这个属性可以控制JMeter返回结果集的最大行数,从而减少数据传输和处理的负担。
- Handle ResultSet:指定如何处理查询结果集。这个属性可以控制JMeter处理结果集的方式,包括获取行数、存储结果或不处理结果等。
- Store as String:让JMeter将整个结果集作为一个字符串存储到一个变量中。
- Count:让JMeter只获取结果集的行数而不返回实际的结果。
1.5下载依赖库
依赖库的使用方式有2种(选其一):
- 测试计划最下面添加 jar 包。
- 将下载的 jar 放到 jmeter/lib 下面,重启jmeter。
2.几个简单的例子
例子1:没有任何参数的查询
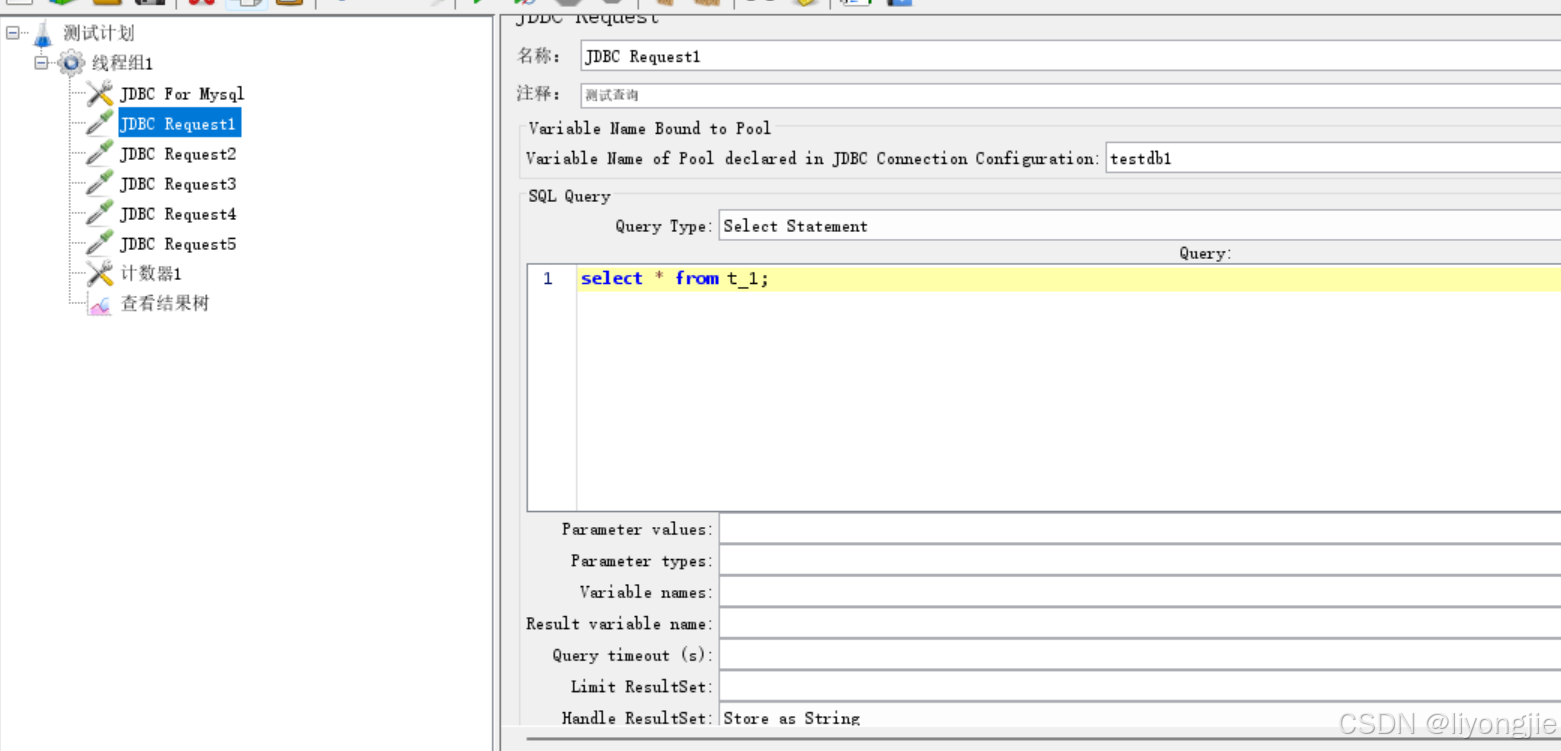
例子2:带参数的查询
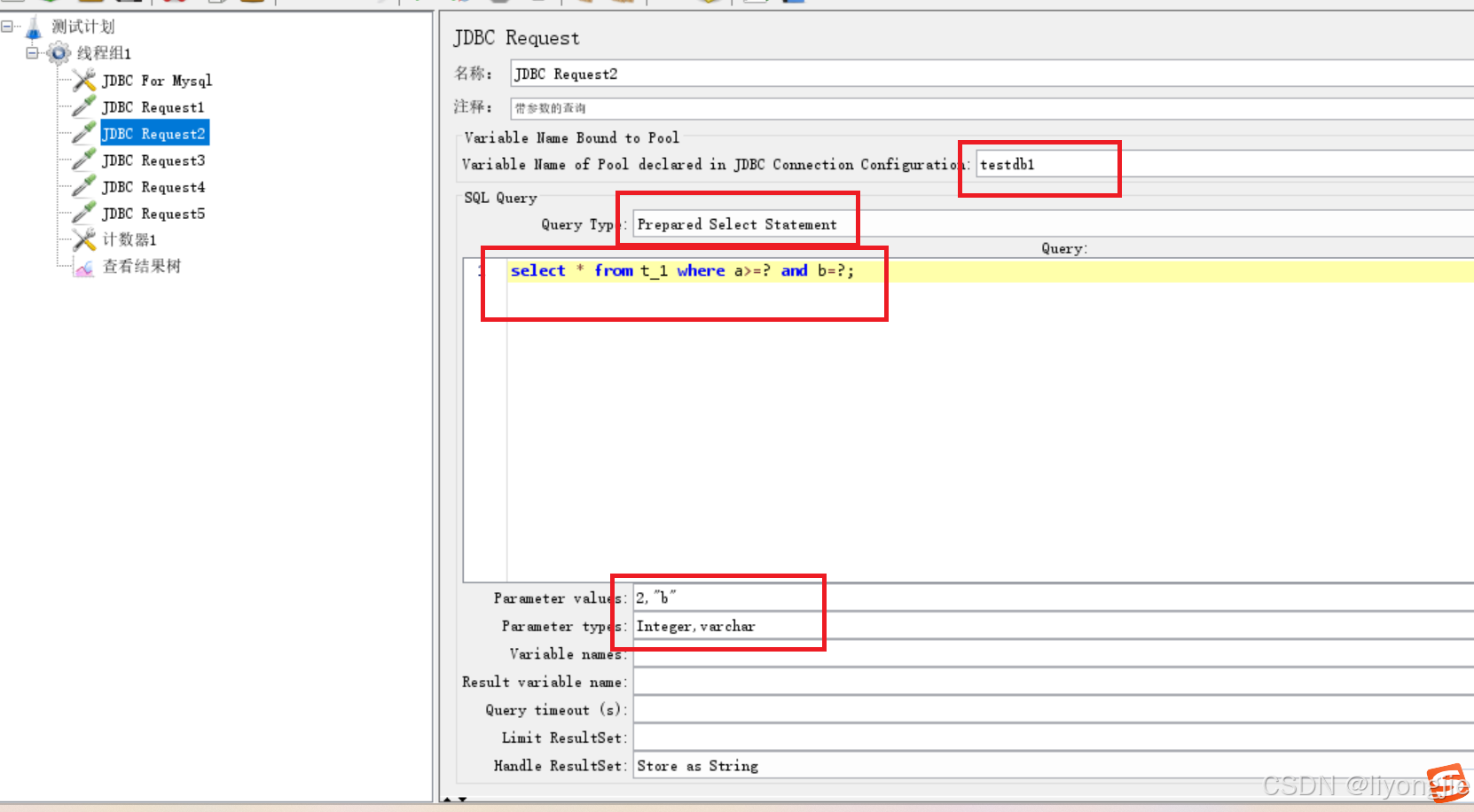
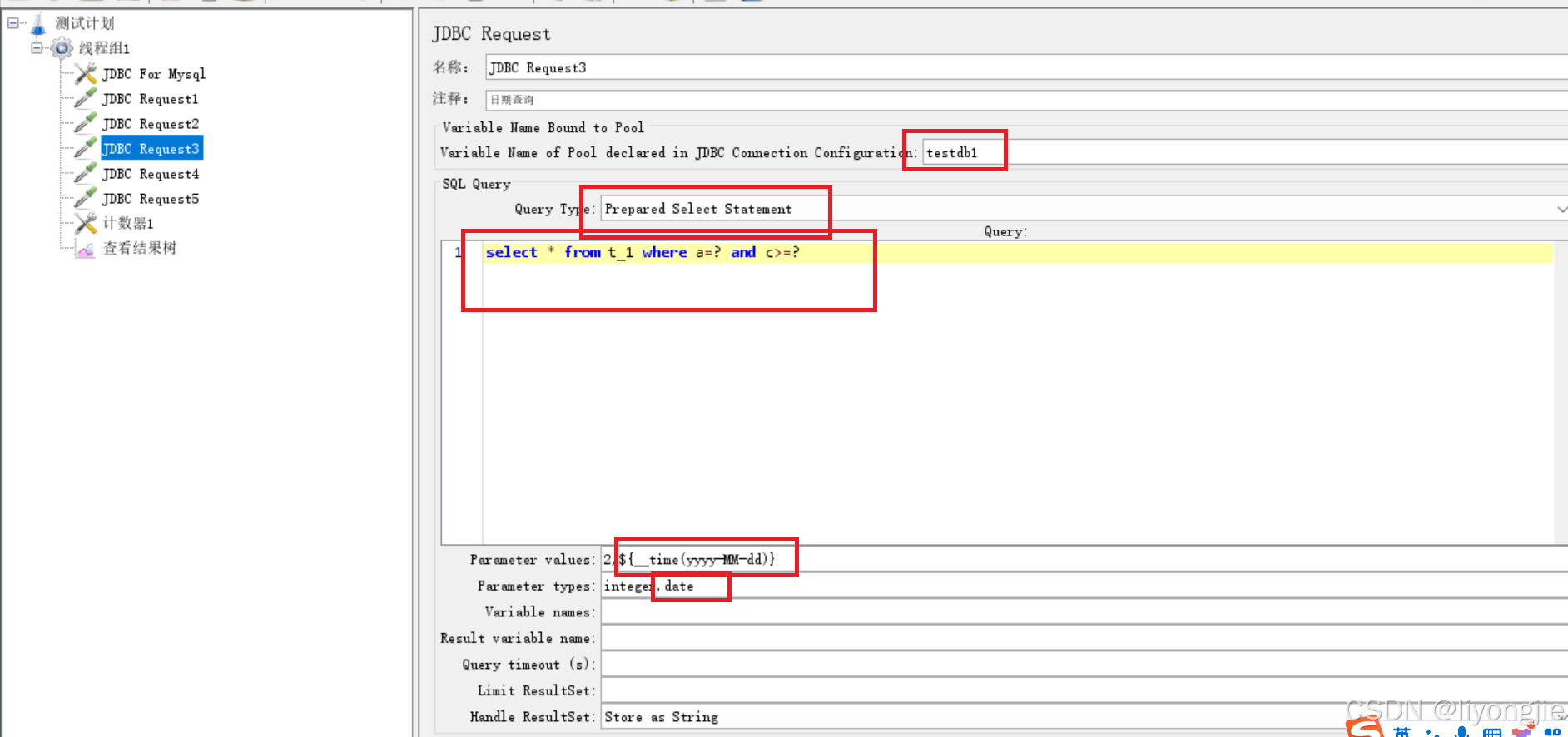
例子3:当前日期作为参数查询
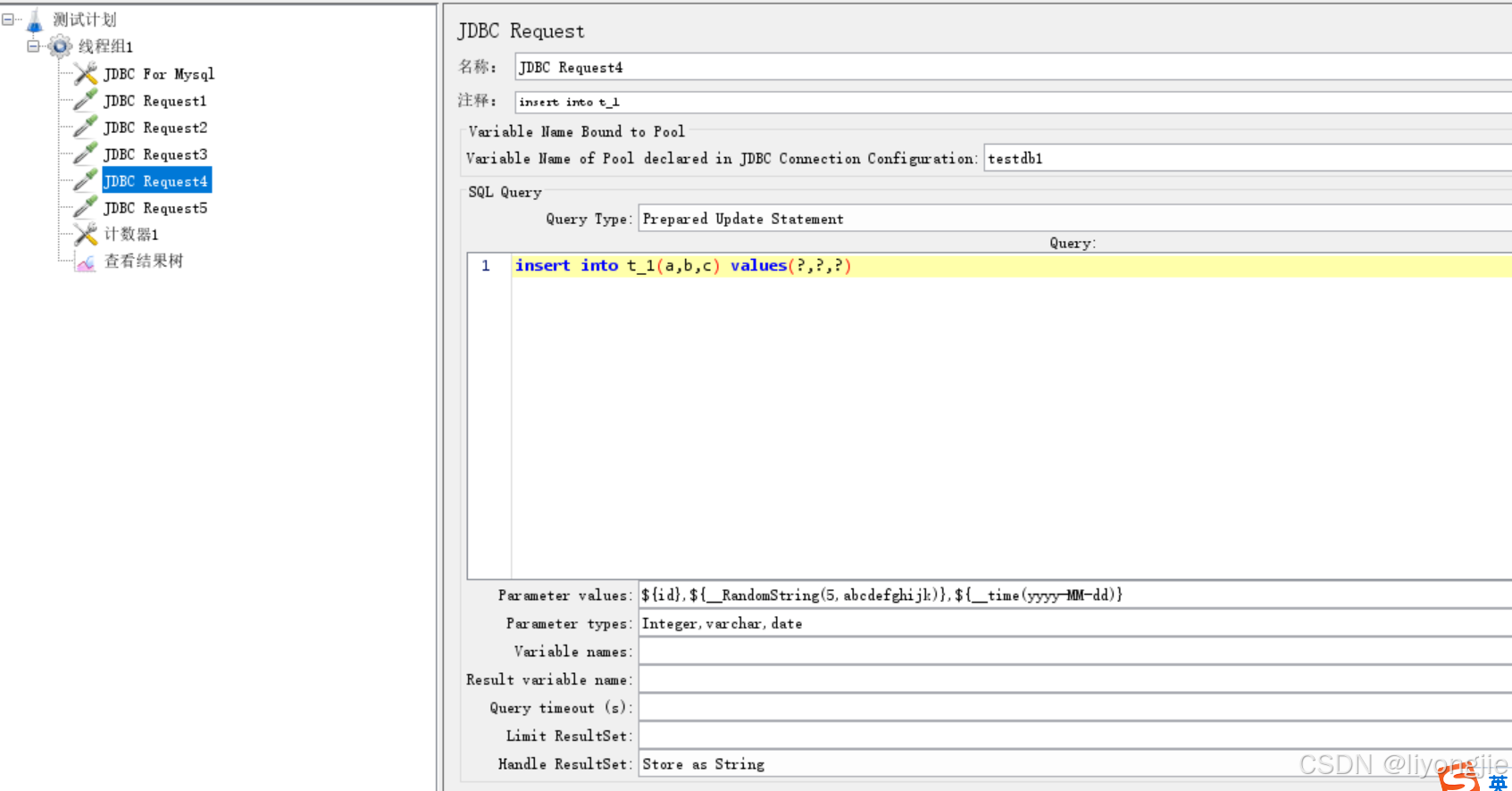
例子4:随机生成字符串
JMeter 还提供了__RandomString函数,可以生成指定长度的随机字符串。该函数有多个参数,可以指定生成字符串的长度、字符集和前缀等。语法如下:${__RandomString(length,charsToUse,prefix)}
其中,length是生成字符串的长度,charsToUse是可用字符集合,prefix是字符串的前缀。
例如,${__RandomString(10,abcdefghijklmnopqrstuvwxyz,TEST)}会生成一个以“TEST”为前缀、长度为 10、由小写字母组成的随机字符串。
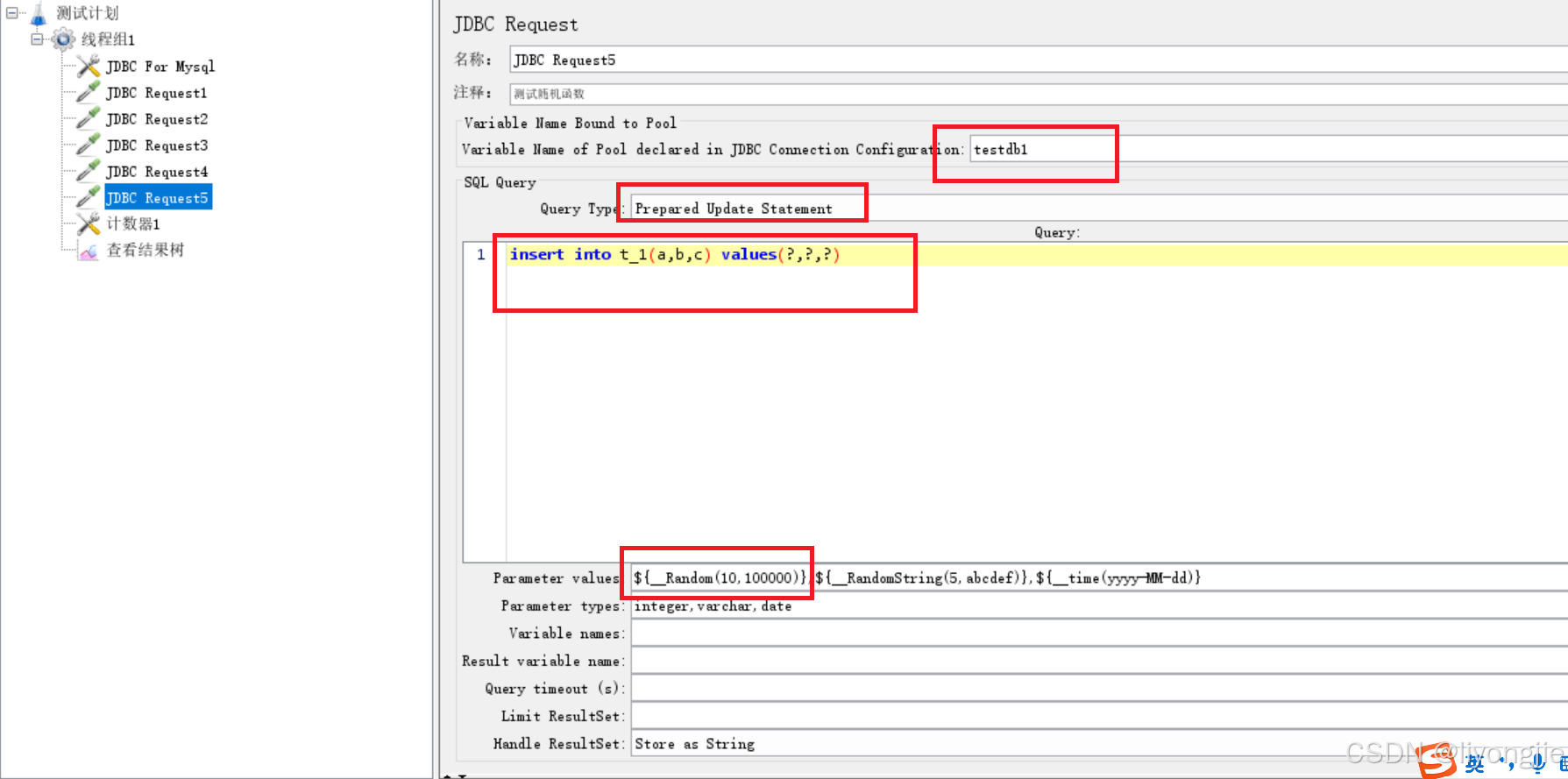
例子5:随机生成数字
JMeter 提供了多个用于生成随机数的函数,其中最常用的是__Random函数。该函数可以生成一个指定范围内的随机整数或浮点数。语法如下:${__Random(min,max)}
其中,min和max是生成随机数的范围,可以是整数或浮点数。例如,${__Random(1,100)}会生成一个 1 到 100 之间的随机整数。
例子6:计数器使用
在 Jmeter 中,通过函数 ${__counter(,)} 可以实现每次加 1 11 的计数效果。但如果步长不为 1,则要利用到我们的计数器。
新建计数器:右键线程组,然后点击:添加->配置元件->计数器
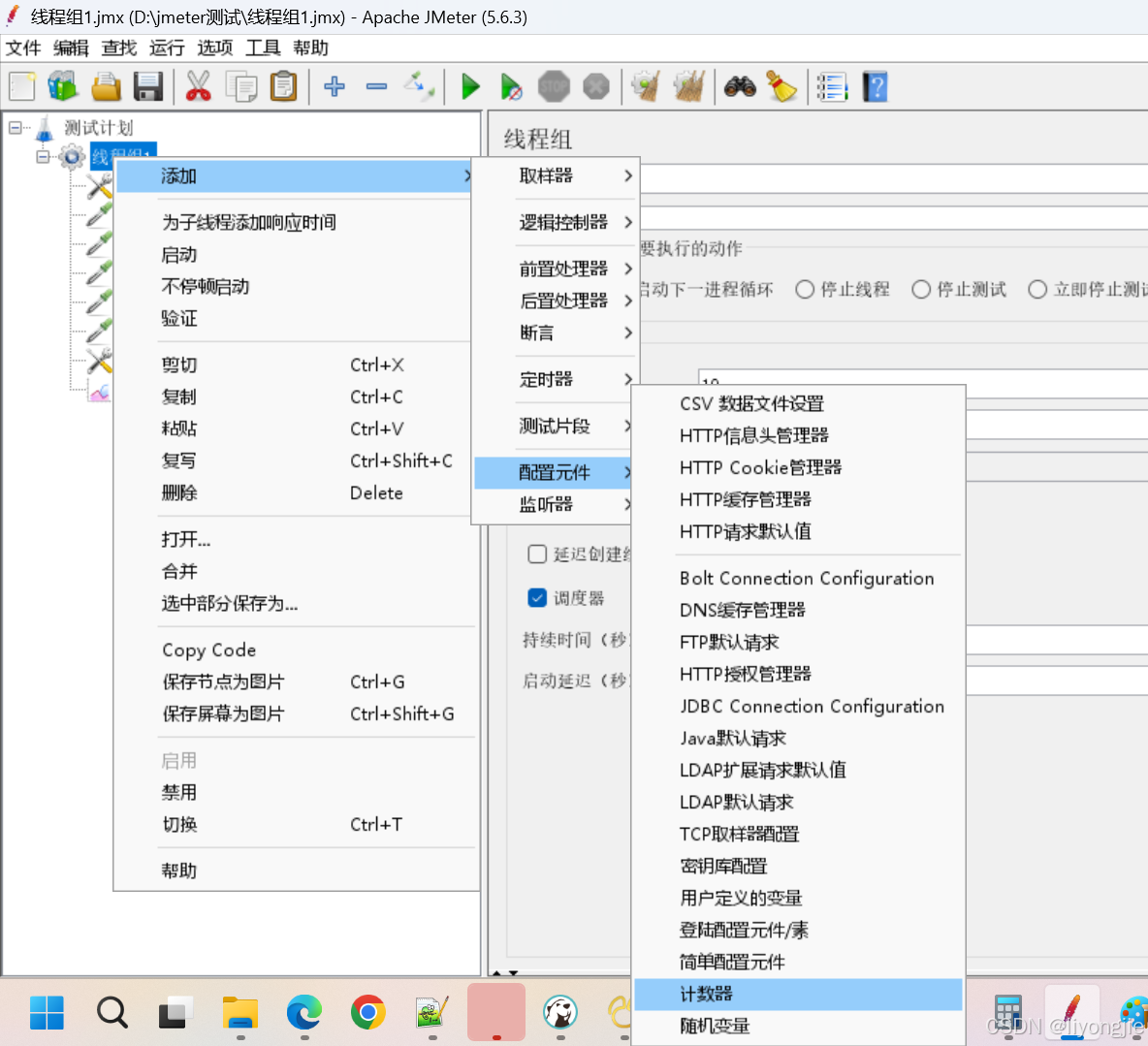
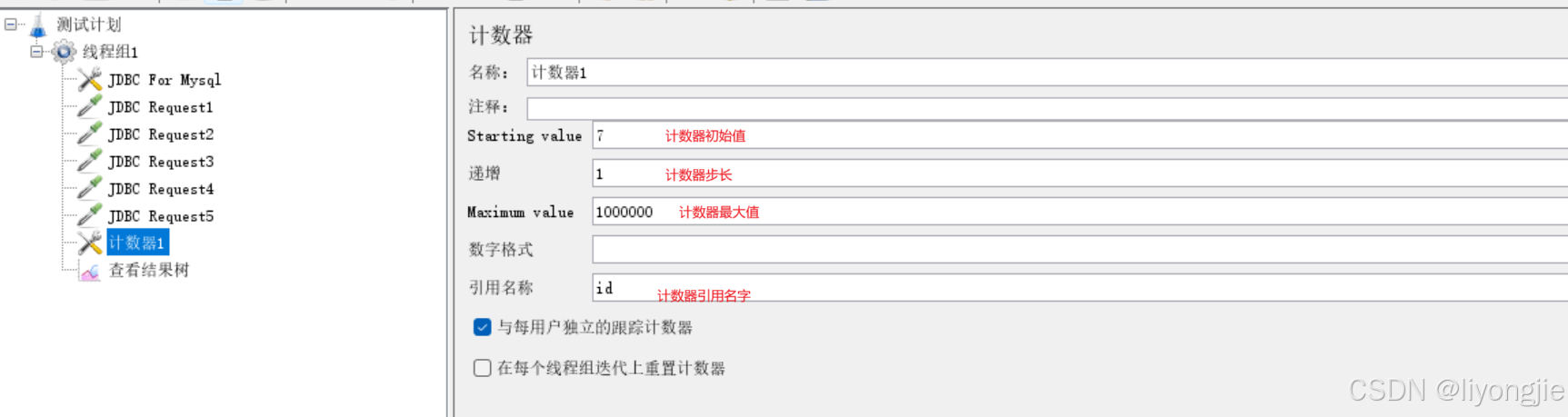
参数说明:
- 开始值(
Starting value):给定计数器的起始值、初始值,第一次迭代时,会把该值赋给计数器。 - 递增(
Increment):每次迭代后,给计数器增加的值。 -
最大值(
Maximum value):达到最大值时,自动重置初始值;默认最大值是2的63次方-1,即Long.MAX_VALUE - 数字格式(
Number format):可选格式,比如 000,格式化为 001,002 … 三位,不足补 0;默认格式为Long.toString(),但是默认格式下,还是可以当作数字使用。 - 引用名称(
Exported Variable Name):用于控制在其它元素中引用该值,比如:变量名称为reference_name,形式:${reference_name}。 -
与每用户独立的跟踪计数器(Track Counter Independently for each User):如果不勾选,即全局的计数器,比如用户 #1 获取值为 1 11,用户 #2 获取值则为 2 22;如果勾选,即独立的计数器,则每个用户有自己的值:比如用户 #1 获取值为 1 11,用户 #2 获取值也为 1 11(注:网上很多帖子这个参数都解释反了,估计是某一篇说错了,然后其他人直接搬过去都没有验证过,本文有验证)。
- 在每个线程组迭代上重置计算器(
Reset counter on each Thread Group Iteration):可选,仅勾选与每用户独立的跟踪计数器时可用。
引用计数器:
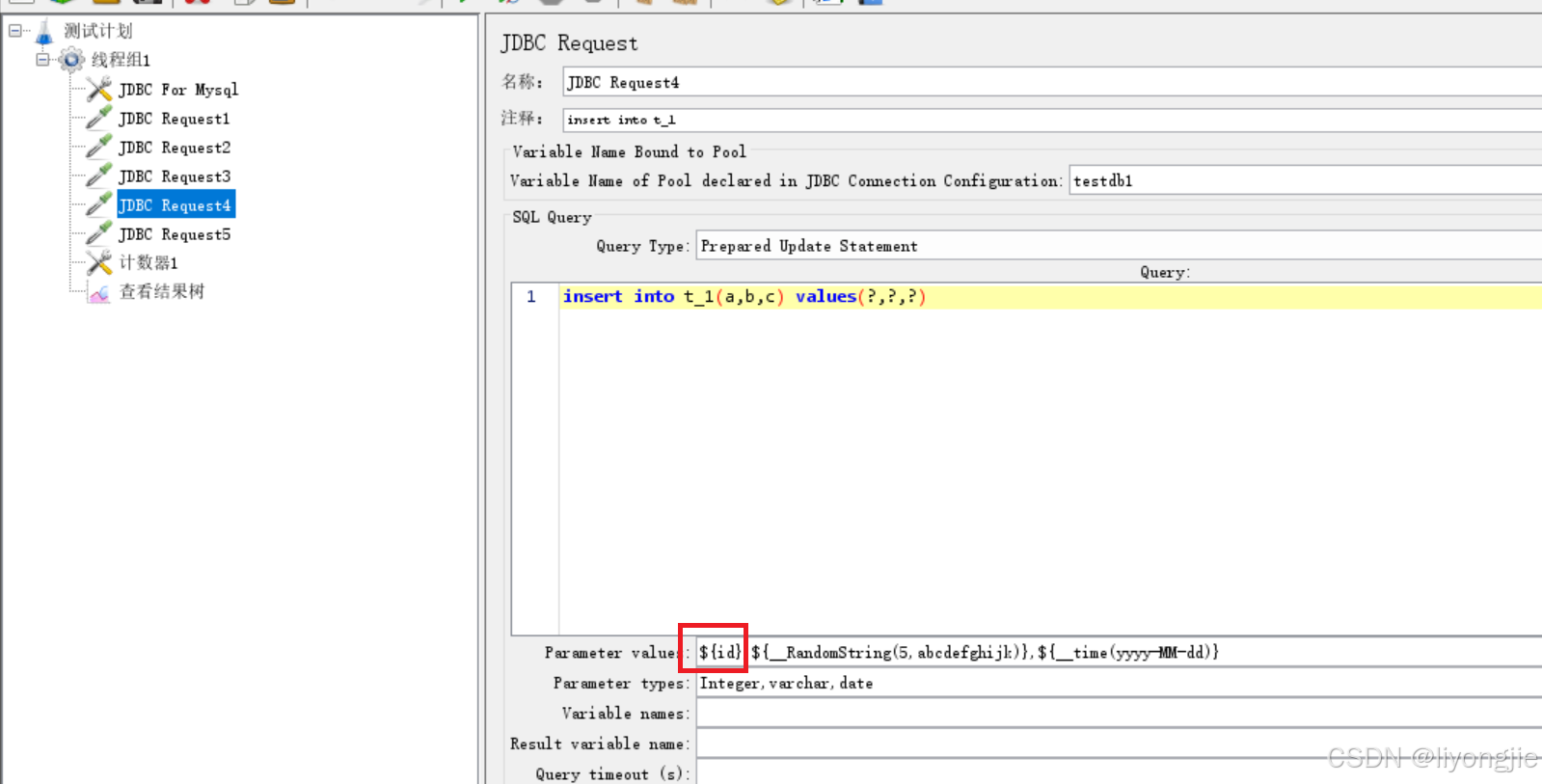
例子7:随机变量函数
除了使用内置函数生成随机数外,JMeter 还支持使用随机变量生成随机数。随机变量可以通过 CSV 数据 文件、用户定义的变量等方式进行定义。语法如下:
${__V(myVar_${__Random(1,5)})}
其中,myVar_是变量名的前缀,__Random(1,5)会生成一个 1 到 5 之间的随机整数,最终生成的随机变量名如myVar_3。
使用随机变量可以更加灵活地控制生成的随机数。
例子8:UUID 函数
UUID 用来生成一个随机 ID。UUID 和 Random 函数的区别是:Random 生成随机数,是可能会重复的。UUID 是一定不会重复的。语法如下:${__UUID()}
例子9:日期时间函数
time函数的使用方法:${__time(日期时间格式,自定义变量名)}
年:yyyy年,MM 月,dd日,时:HH(24小时制) hh(12小时制) 分:mm 秒:ss 毫秒:SSS
例如:
${__time(yyyy-MM-dd)}
${__time(dd-MM-yyyy)}
${__time(yyyyMMdd)}
${__time(dd/MM/yyyy)}
3.添加查看结果树,执行测试
【执行测试】-增加查看结果树
- 右击线程组 → 添加 → 监听器 → 查看结果树
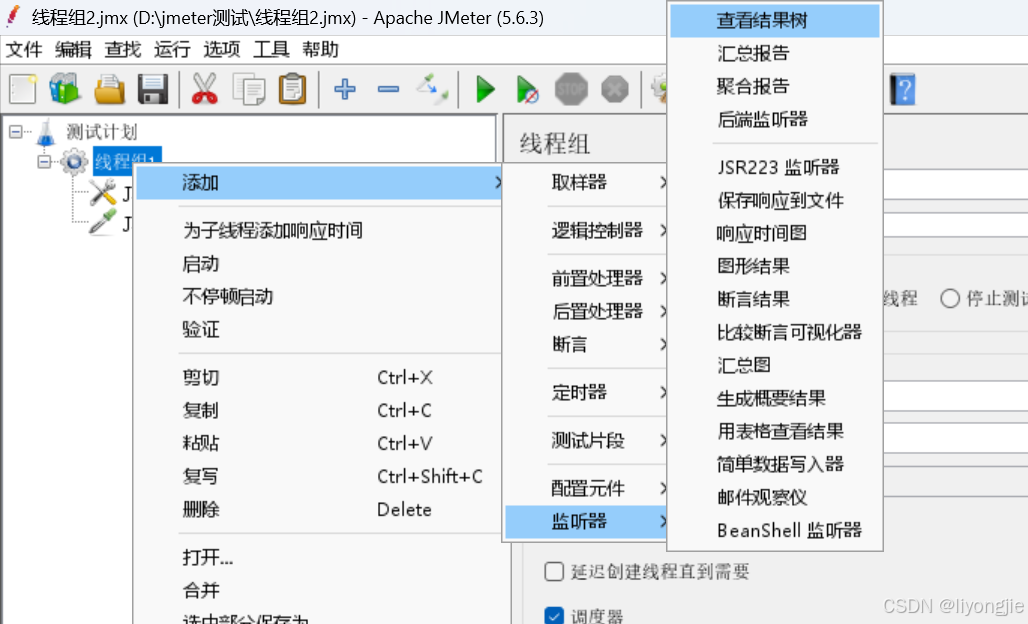
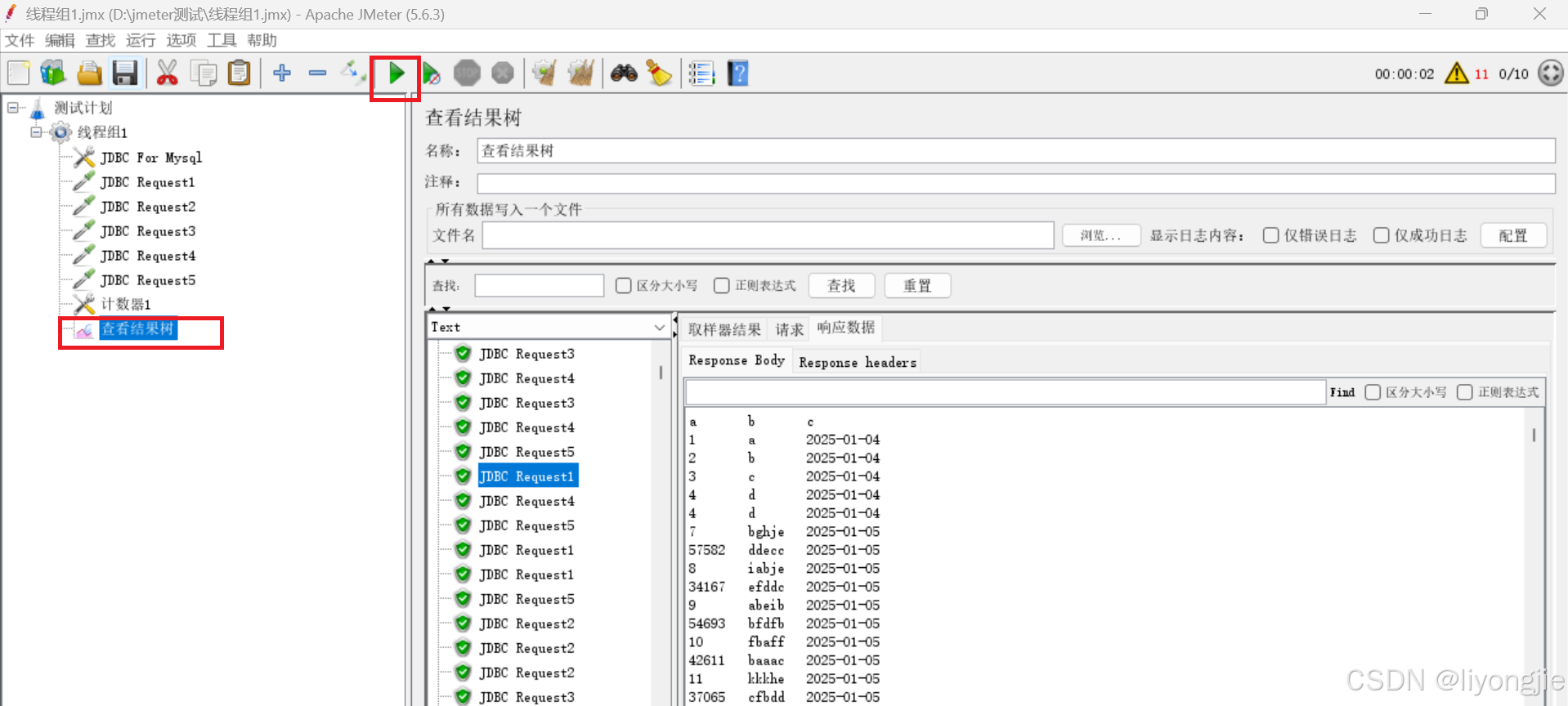
【查看结果树】-请求语句

【查看结果树】-响应数据
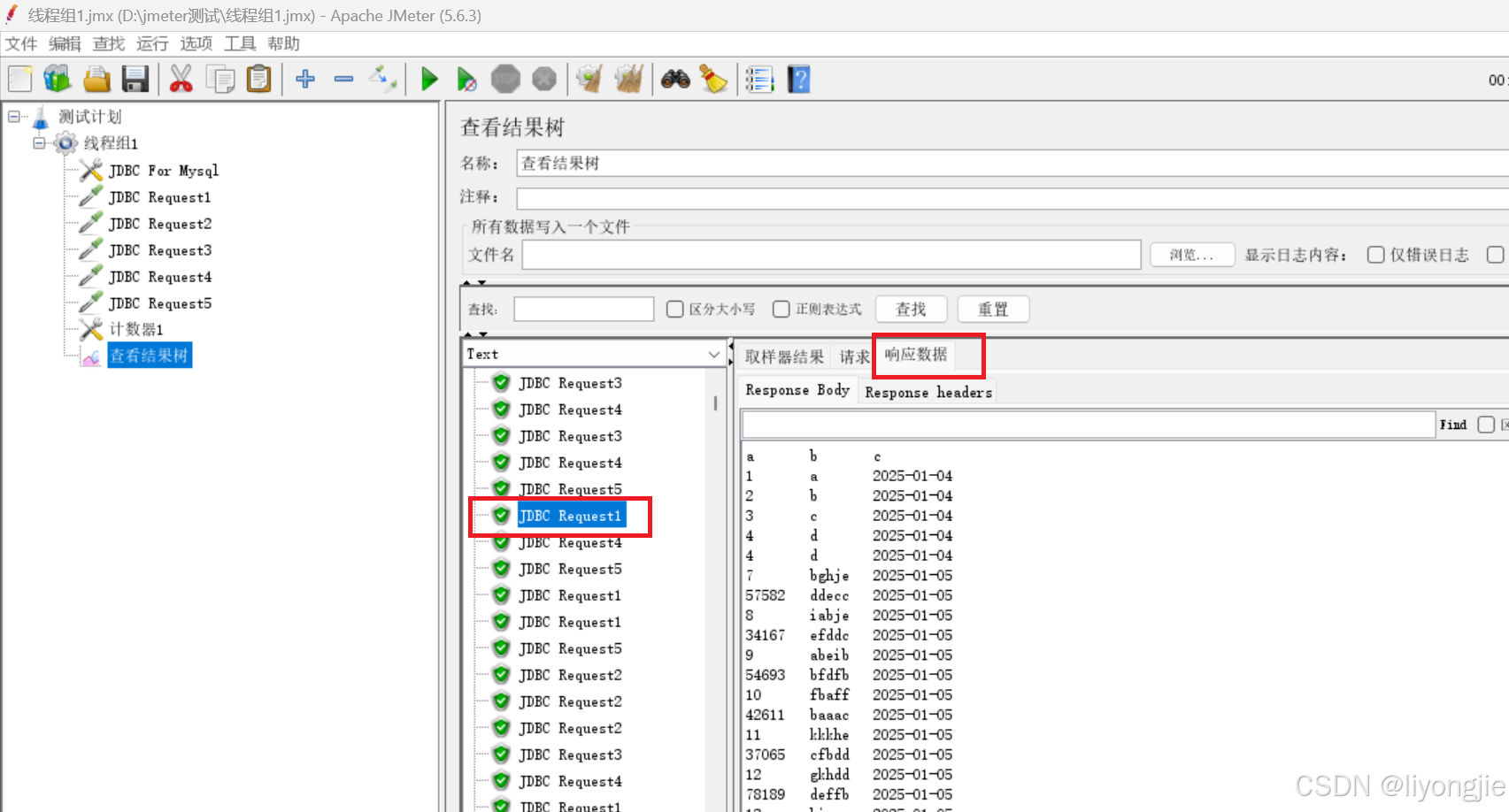
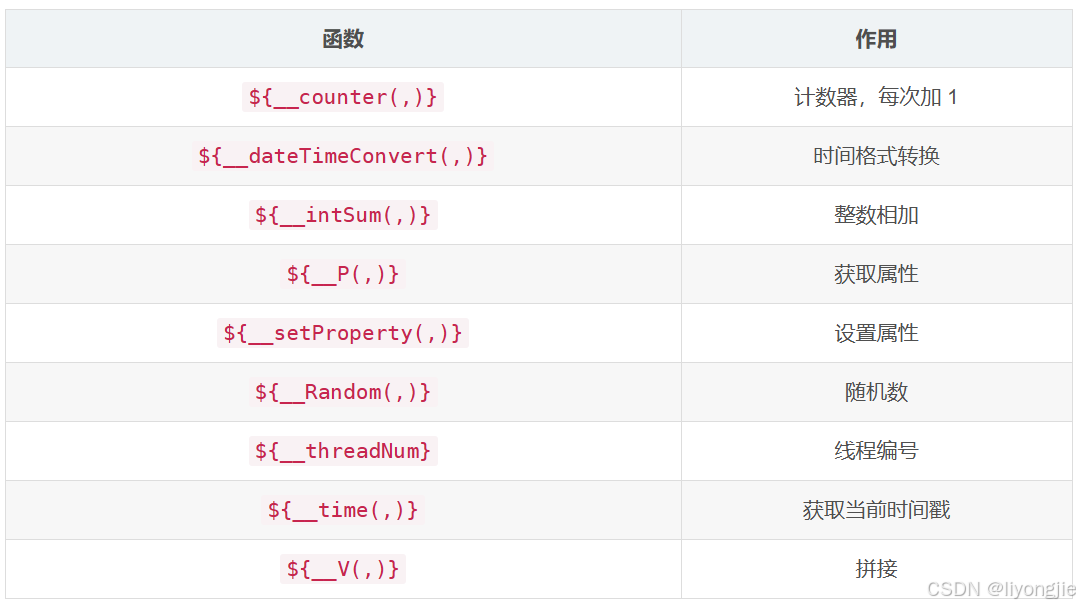
4.JMeter常用系统函数
5.linux命令行下运行
部署jmeter
将jmeter安装包上传到服务器/opt/software/jmeter/package目录下
然后解压:
tar -zxvf apache-jmeter-5.6.3.tgz 设置环境变量
vi /etc/profile
增加以下内容:
export JMETER_HOME=/opt/software/jmeter/package/apache-jmeter-5.6.3
export CLASSPATH=${JMETER_HOME}/lib/ext/ApacheJMeter_core.jar:${JMETER_HOME}/lib/jorphan.jar:${CLASSPATH}
export PATH=${JMETER_HOME}/bin:$PATH
保存后使之生效:source /etc/profile
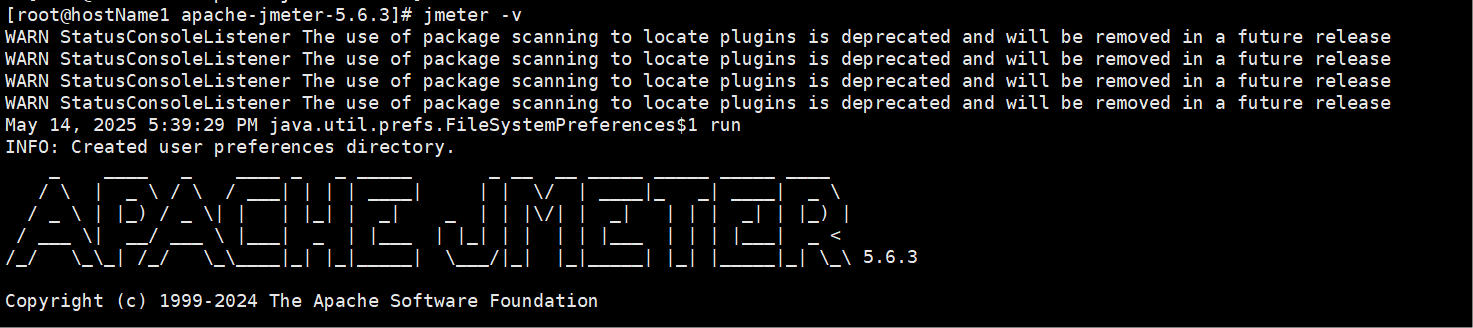
检测部署是否成功:
执行命令:jmeter -v
执Jmeter测命令:
sh jmeter.sh -n -t xxx.jmx -l /xx/log/xxx.jtl -e -o /xx/html/report –r
例如:
jmeter -n -t 线程组1-openGauss.jmx -l /opt/software/jmeter/jmeter_log/线程组1-openGauss_`date +%Y%m%d_%H%M%S`.jtl -e -o /opt/software/jmeter/jmeter_report
后台运行jmeter命令:
nohup ./jmeter -n -t test.jmx -l ./test-`hostname`_`date +%Y%m%d_%H%M%S`.log > jmeter-`hostname`_`date +%Y%m%d_%H%M%S`.out 2 > &1 &
命令解释:
-n:非GUI模式执行Jmeter
-t:执行测试文件所在的位置及文件名
-l:指定生成测试结果的保存文件,jtl文件格式
-e:测试结束后,生成测试报告
-o:指定测试报告的存放位置,注意:执行命令前,report文件夹下内容必须清空,否则会报错
-r:启动所有在remote_hosts配置的服务器。注意:不需要分布式测试,只是单点就不输 -r 即可
实例:
在GUI界面配置测试计划
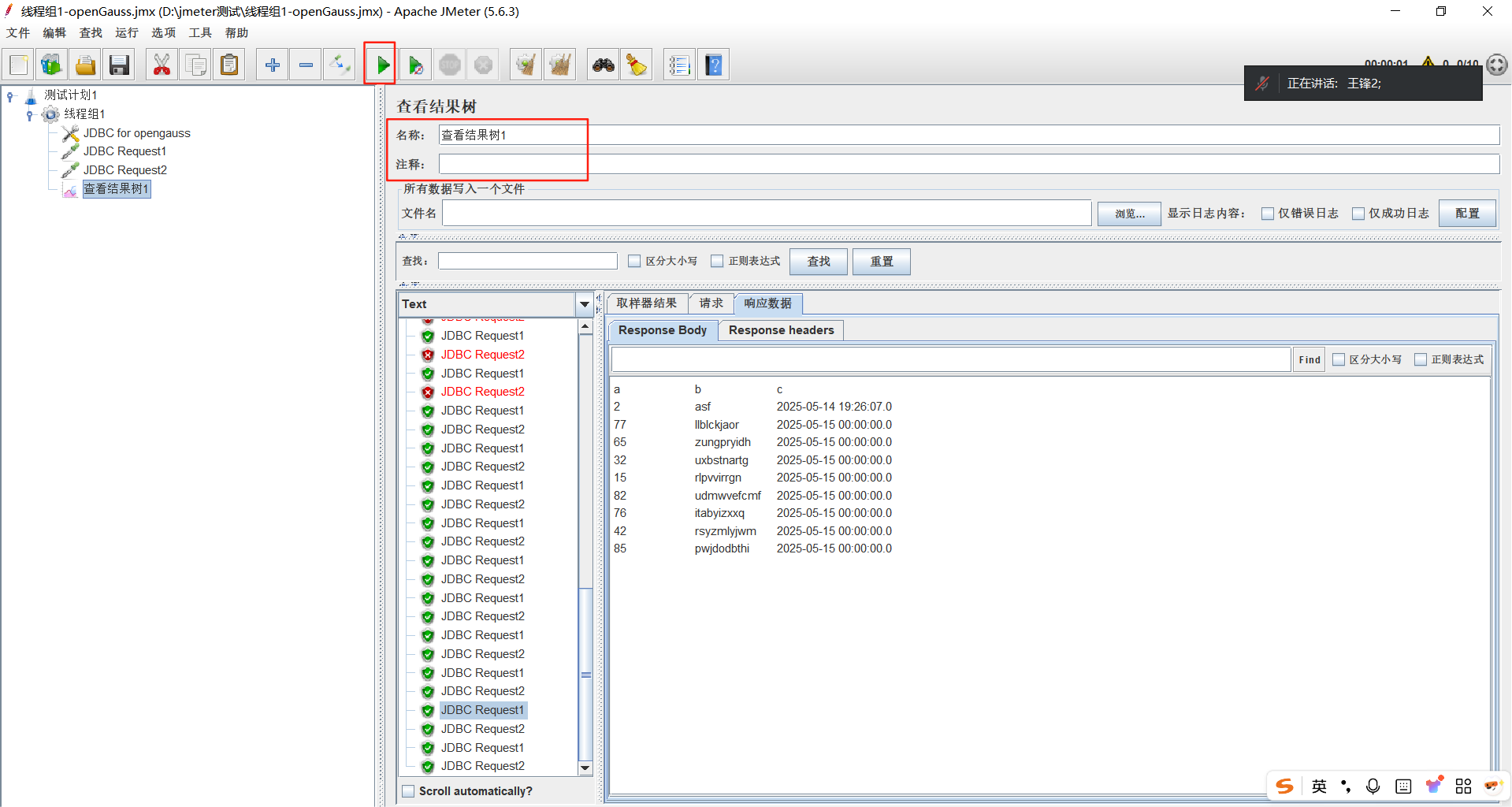
保存配置:线程组1-openGauss.jmx
将配置文件上传至服务器

在服务器上执行jmeter:
进入目录:
cd /opt/software/jmeter/jmeter_script
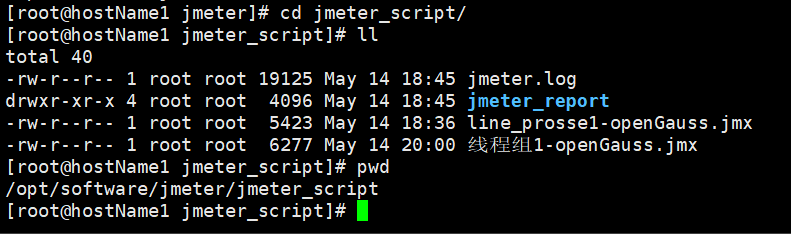
执行命令:
jmeter -n -t 线程组1-openGauss.jmx -l /opt/software/jmeter/jmeter_log/线程组1-openGauss_`date +%Y%m%d_%H%M%S`.jtl -e -o /opt/software/jmeter/jmeter_report
执行结果

查看日志
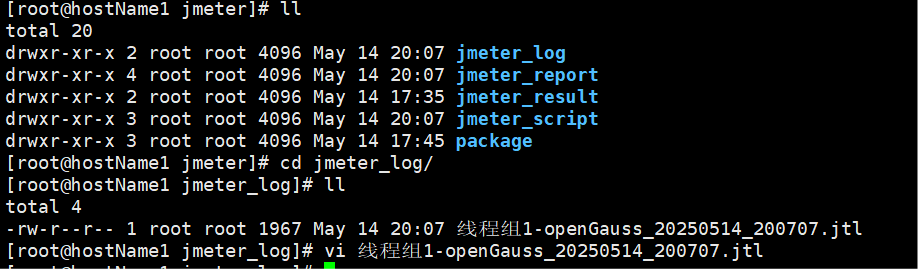
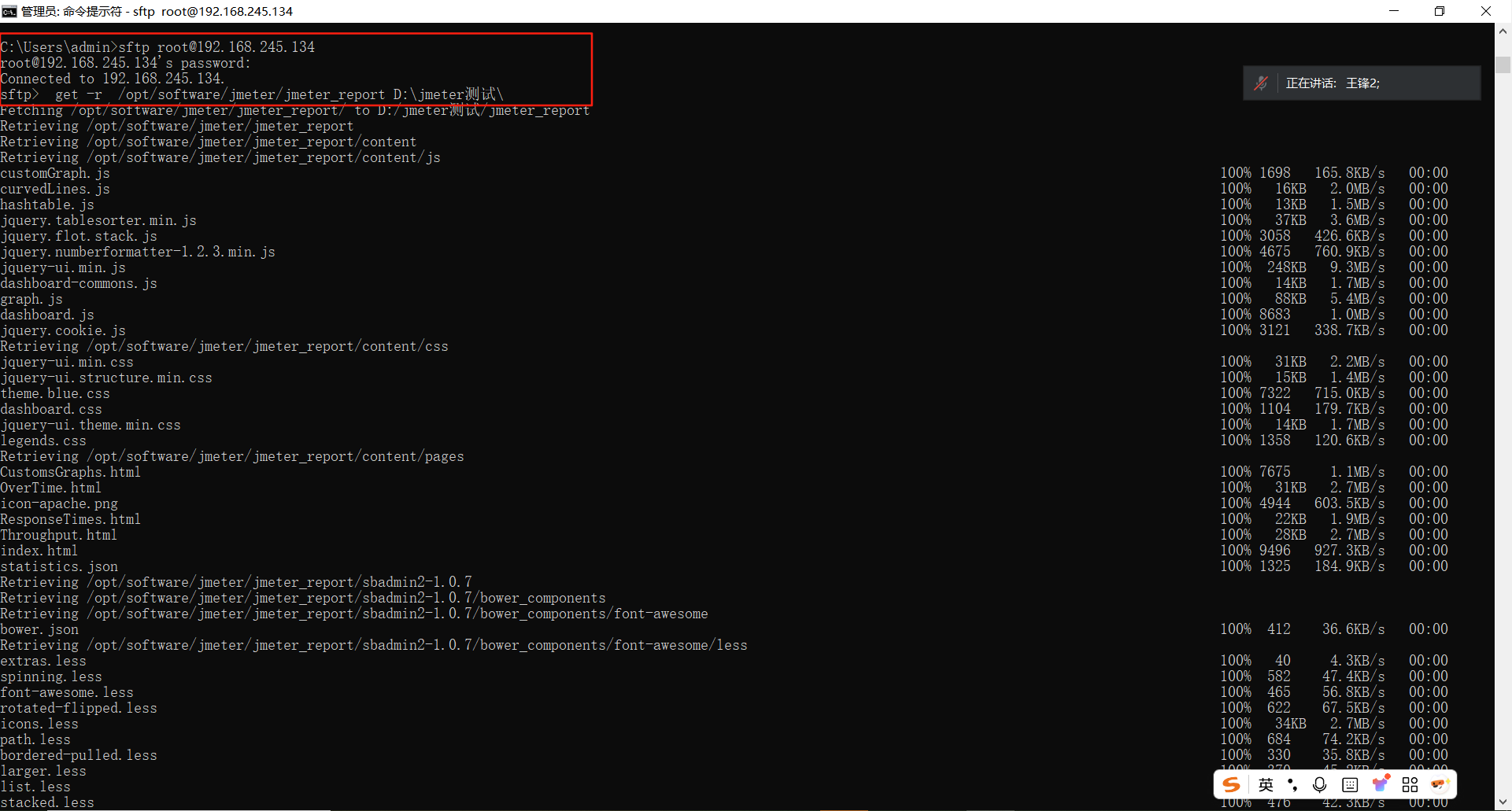
下载报告文件:
在windows命令下执行sftp命令和get命令下载jmeter报告文件,如下图:
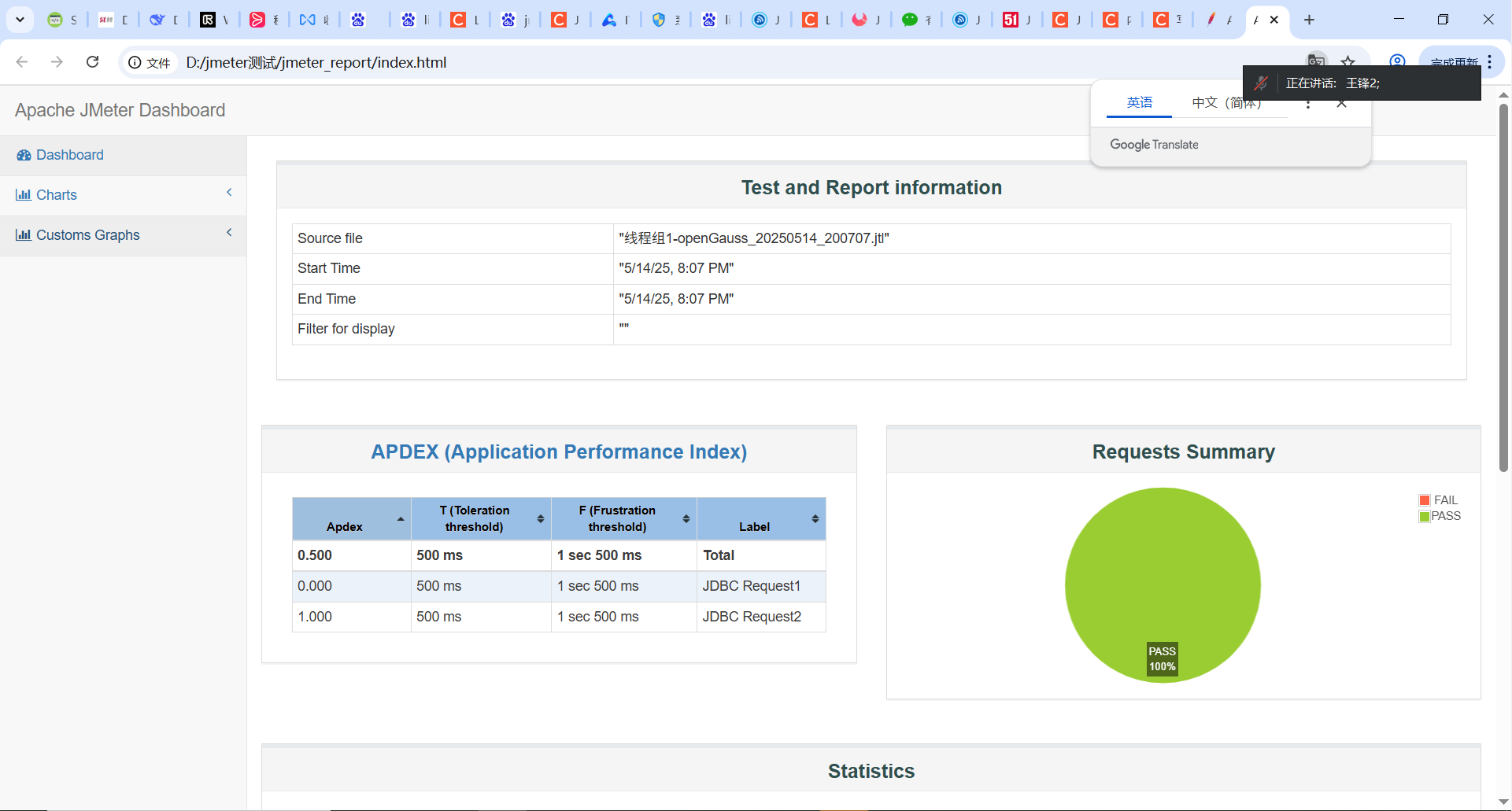
查看报告
Jmeter常见的监听器
查看结果树
查看结果树 View Results Tree,展示的是较为详细的请求 request、返回 response 信息。
在调试接口的时候,可以使用查看结果树 View Results Tree 来查看请求和返回的详细信息,但是在实际的压测中,尽量不要使用查看结果树。正是因为查看结果树 View Results Tree 展示结果详细,会占用系统资源,可能会影响压测性能。
取样器结果:
Thread Name: 线组名称
Sample Start: 启动开始时间
Load time: 加载时长
Latency: 等待时长
Size in bytes: 发送的数据总大小
Headers size in bytes: 发送头大小
Body size in bytes: 发送数据的其余部分大小
Sample Count: 发送统计
Error Count: 错误统计
Response code: 返回码
Response message: 返回消息
Response headers:返回头信息
汇总报告
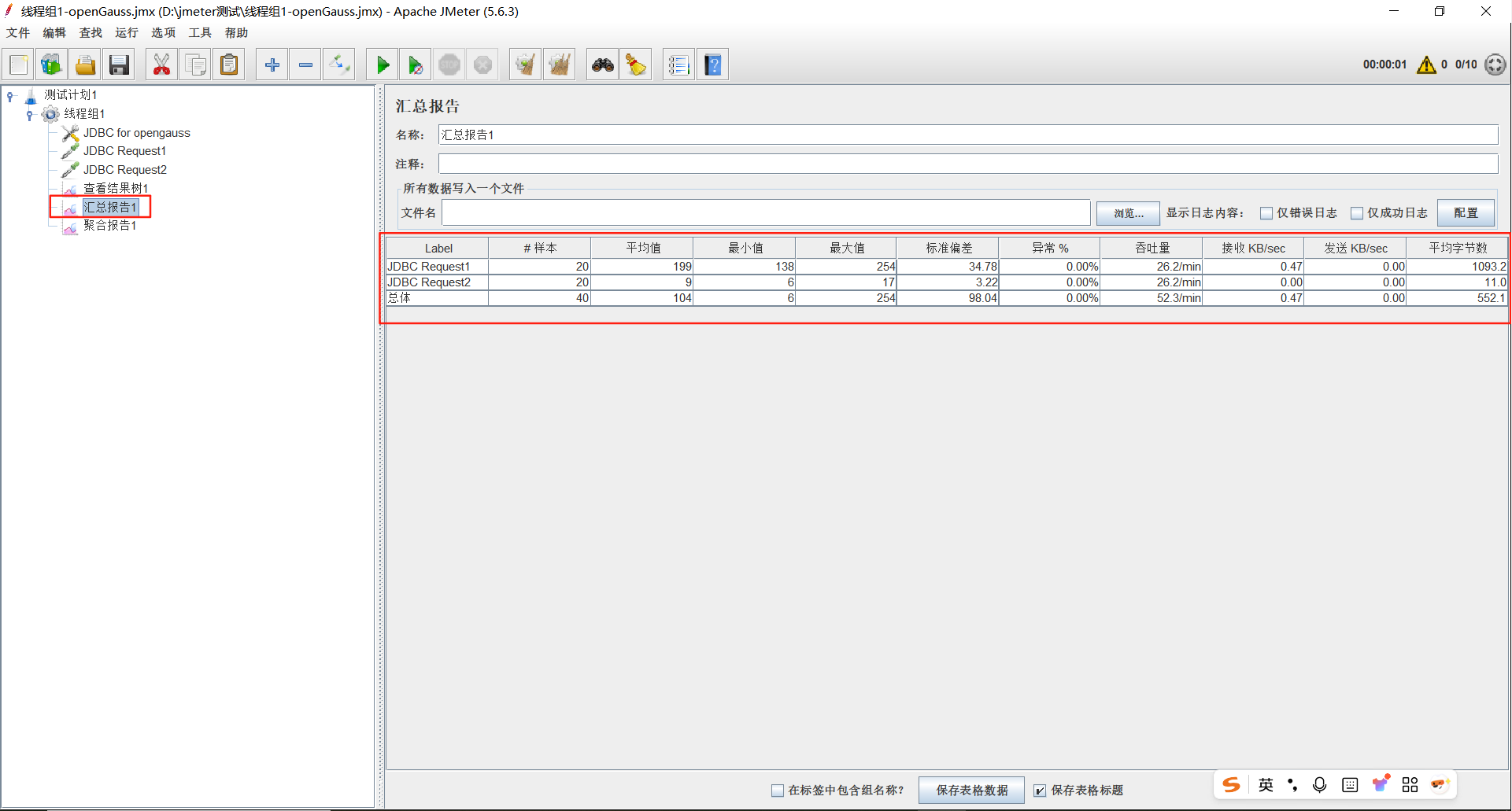
汇总报告,为测试中的每个不同命名的请求创建一个表行。这与聚合报告类似,只是它使用更少的内存。提供了最简要的测试结果信息,同时可以配置将相应的信息保存至指定的文件中(支持xml、csv格式的文件)。
关键参数说明如下:
Label 取样器别名,如果勾选Include group name ,则会添加线程组的名称作为前缀
样本:取样器运行次数
平均值: 请求(事务)的平均响应时间
最小值:请求的最小响应时间
最大值;请求的最大响应时间
标准偏差:响应时间的标准方差
异常%:事务错误率
吞吐量:也就是TPS
接收 KB/sec:每秒收到的千字节
发送 KB/sec:每秒发送的千字节
平均字节数:响应平均流量
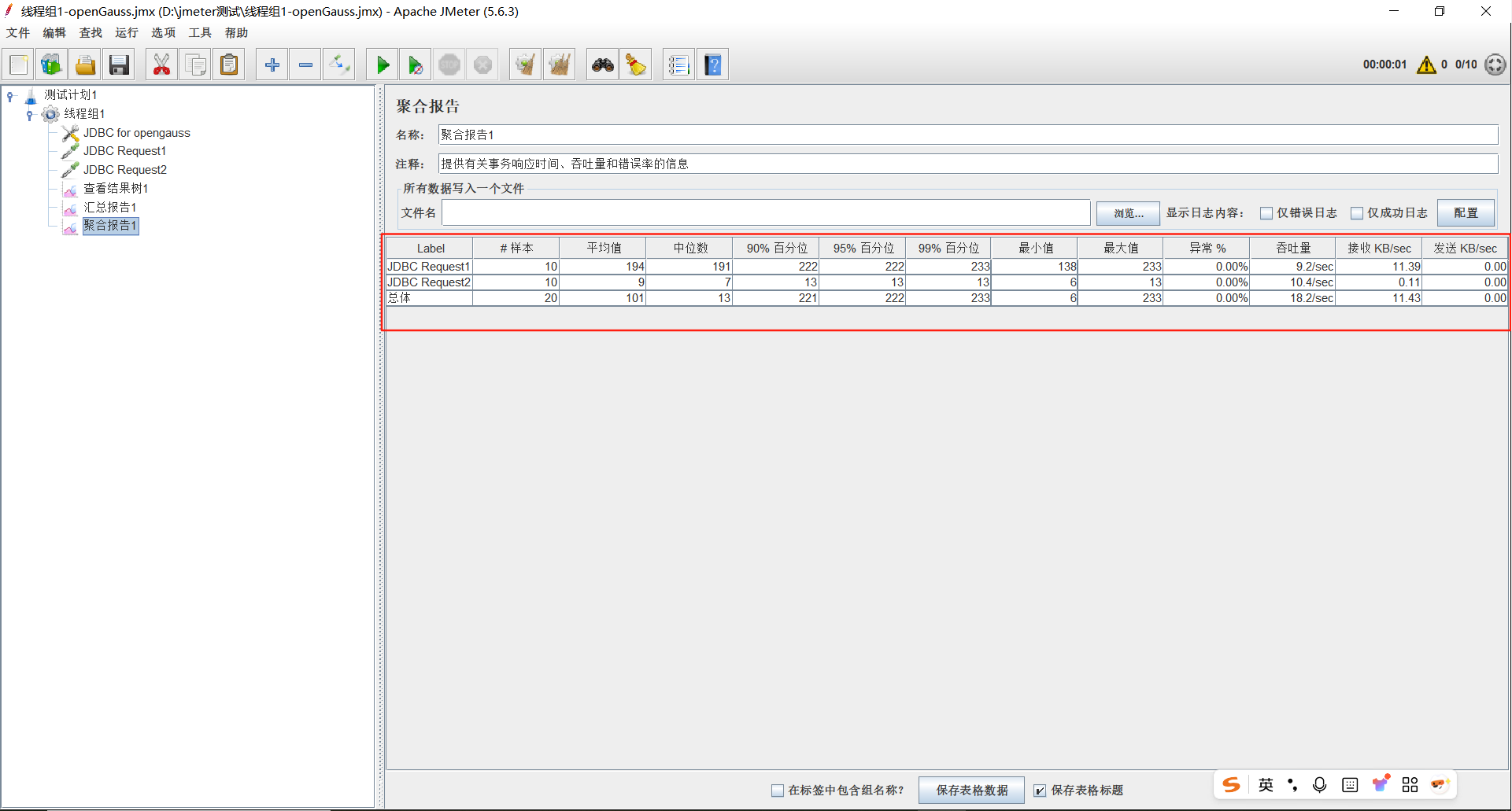
聚合报告
聚合报告,记录这次性能测试的总请求数、错误率、用户响应时间(中间值、90%、最少、最大)、吞吐量等,用以帮助分析被测试系统的性能。在聚合报告中,各个响应时间不能超过客户的要求,就是合格,例如不能超过响应时间2s,大于2s就是不合格的。
聚合报告应该是最详细的报告了,也是最为常用的报告。是大家在压测过程中最常用的监听器。
该监听器对于每个请求,它统计响应信息并提供请求数,平均值,最大,最小值,中位数、90%、95%、错误率,吞吐量(以请求数/秒为单位)和以kb/秒为单位的吞吐量。
关键参数说明如下:
Label:每个 JMeter 的 element(例如 HTTP Request)都有一个 Name 属性,这里显示的就是 Name 属性的值
#样本:表示测试中一共发出了多少个请求,如果模拟10个用户,每个用户迭代10次,那么这里就显示对应的 HTTP Request的执行次数是100
平均值:平均响应时间——默认情况下是单个 Request 的平均响应时间,当使用了 Transaction Controller 时,也可以以Transaction 为单位显示平均响应时间
中位数:50%用户的响应时间
90%百分位:90%用户的响应时间
95%百分位:95%用户的响应时间
99%百分位:99%用户的响应时间
最小值:最少响应时间
最大值:最大响应时间
异常%:本次运行测试中出现错误的请求的数量/请求的总数
吞吐量:默认情况下表示每秒完成的请求数(Request per Second),当使用了 Transaction Controller 时,也可以表示类似 LoadRunner 的 Transaction per Second 数
(接收/发送)KB/sec :每秒从服务器端接收到的数据量,相当于LoadRunner中的Throughput/Sec
插件使用
Jmeter 自带的监听器 Listener,可以查看结果数据,这些数据更多的是业务指标,具体包括:请求数、请求失败率、响应时间、TPS(或 QPS)、接收速率等。
但是,除了检测业务指标外,还需要检测服务器机器性能,包括:CPU、内存、磁盘、网络 IO 等。这些指标的检测,可以评估系统的容量,比如:需要加多少台设备,或设备的配置(2 核 8G)预期应达到怎样的标准,才能承载业务的发展,在运维层面,可通过压测来评估系统的扩容,是水平扩容(加机器)还是垂直扩容(提高系统配置)。
检测机器性能,包括:CPU、内存、磁盘、网络 IO,需要安装 Jmeter 插件,同时还需要在被检测的机器上安装 ServerAgent 包。
安装插件管理器:
下载插件管理器地址:
- 下载jar包plugins-manager.jar;
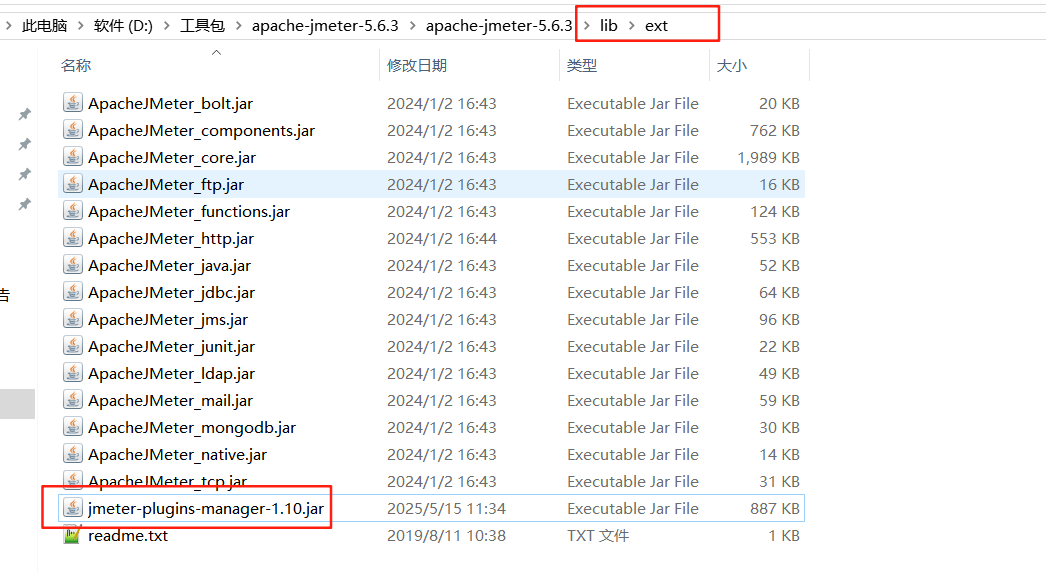
- 将该jar包放入Jmeter的lib/ext目录下;
- 重启Jmeter,
/bin/.jmeter &; - 完成1-3步骤后,可查看 jmeter 面板中 Options -> Plugins Manager,如下图:

下载插件
在插件管理器面板中,可以看到已经安装的插件和可安装的插件,以及可升级的插件
我们选择需要安装的插件,然后点击apply change and restart jmeter
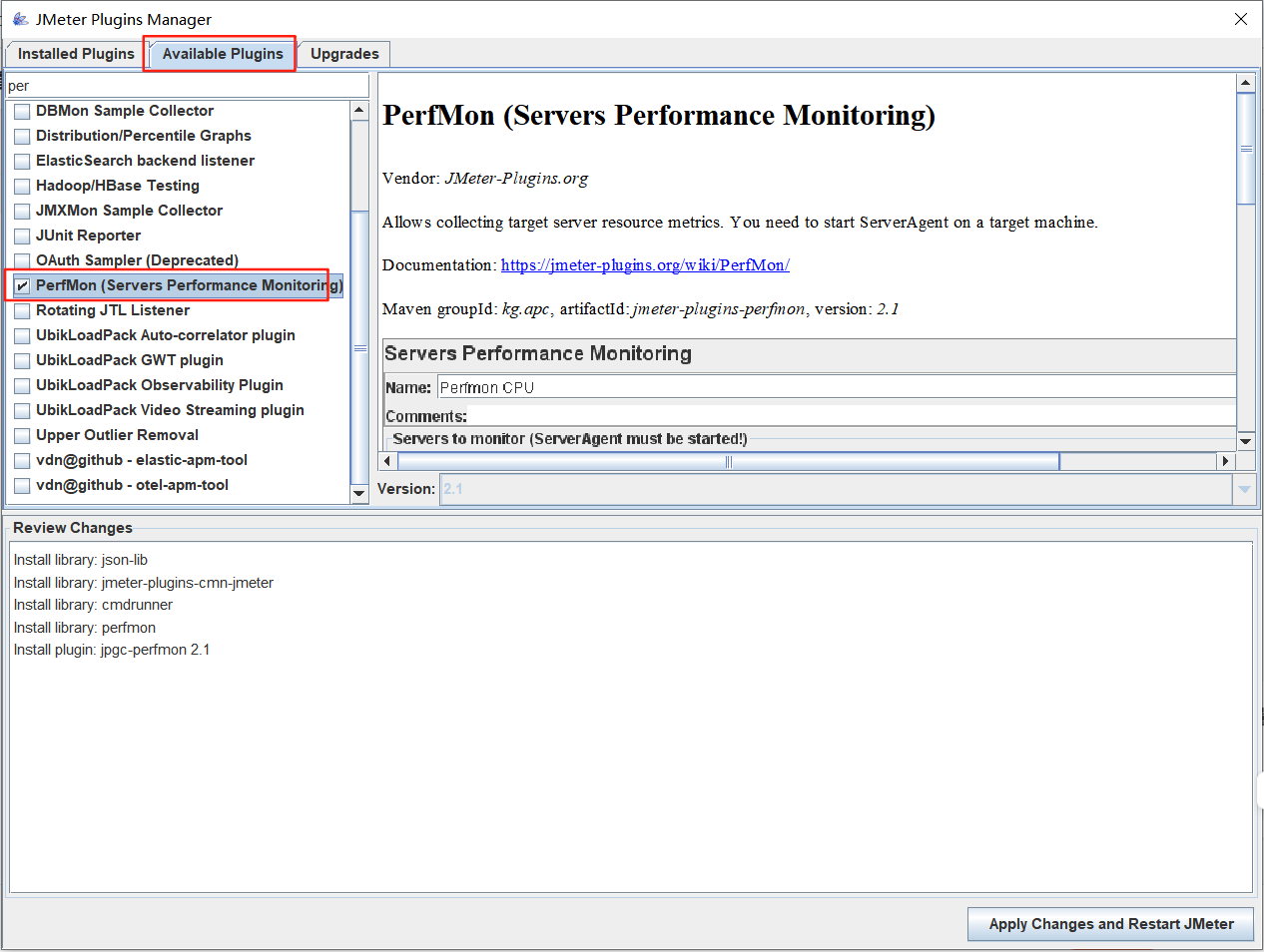
性能监控插件:
- PerfMon (Servers Performance Monitoring)
- jpgc - Standard Set
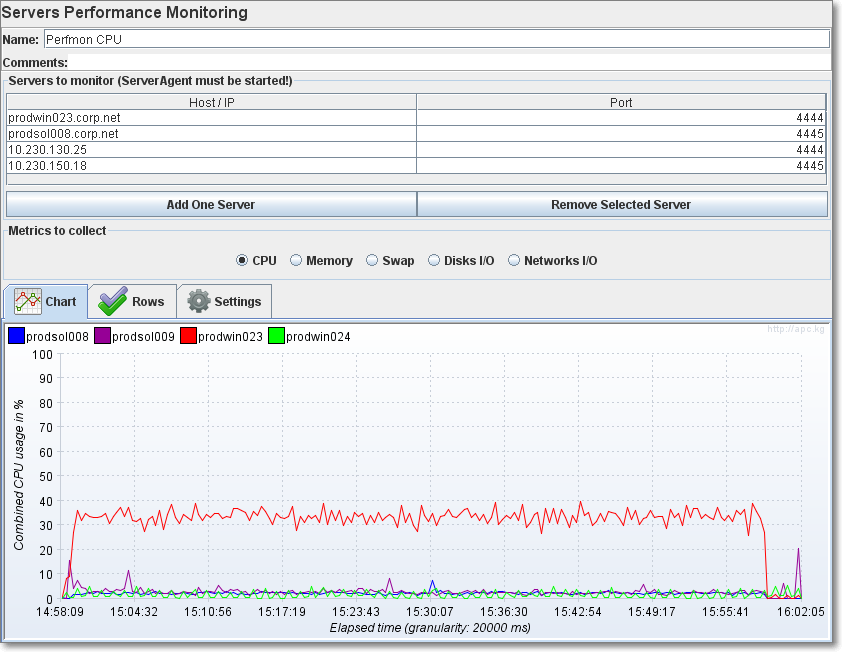
添加性能监控:

下载 ServerAgent
被监听的服务器上,也需要安装ServerAgent包。
ServerAgent 包下载地址:https://github.com/undera/perfmon-agent
注意:被监控的服务器中安装了 ServerAgent 包,这个包自身也会占用 CPU 等资源。ServerAgent 包的作用是,监控 CPU、内存、磁盘、网络 IO 的指标,并将这些指标回传到客户端机器,其自身也会消耗资源,不建议使用

















 821
821

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









