




 本文深入解析了Q-Learning算法,一种用于强化学习的行为计算方法。通过两个关键矩阵——奖励矩阵R和经验矩阵Q,详细阐述了算法的工作原理及迭代计算过程。在现实世界中,如棋类游戏中,Q-Learning能够通过不断学习和调整策略,实现最优路径选择。
本文深入解析了Q-Learning算法,一种用于强化学习的行为计算方法。通过两个关键矩阵——奖励矩阵R和经验矩阵Q,详细阐述了算法的工作原理及迭代计算过程。在现实世界中,如棋类游戏中,Q-Learning能够通过不断学习和调整策略,实现最优路径选择。
总结q-learning ,学习的地址https://www.jianshu.com/p/29db50000e3f?utm_medium=hao.caibaojian.com&utm_source=hao.caibaojian.com
q-learning 是一种行为计算的方法。
首先,所有的行为和这行为的后果已经确定下来,向一般在网上举的例子会用简单的迷宫做过程的讲解,现实中比较合适的例子是下棋,因为下棋的步骤行为比较多。
方法是运用两个矩阵做计算:
第一个是奖励矩阵R,这个状态矩阵y轴代表当前位置(也称为state),x轴代表下一个位置(也称为Action),矩阵的记录数据为奖励值,即距离达目的的数据表示值(也称为reward)。
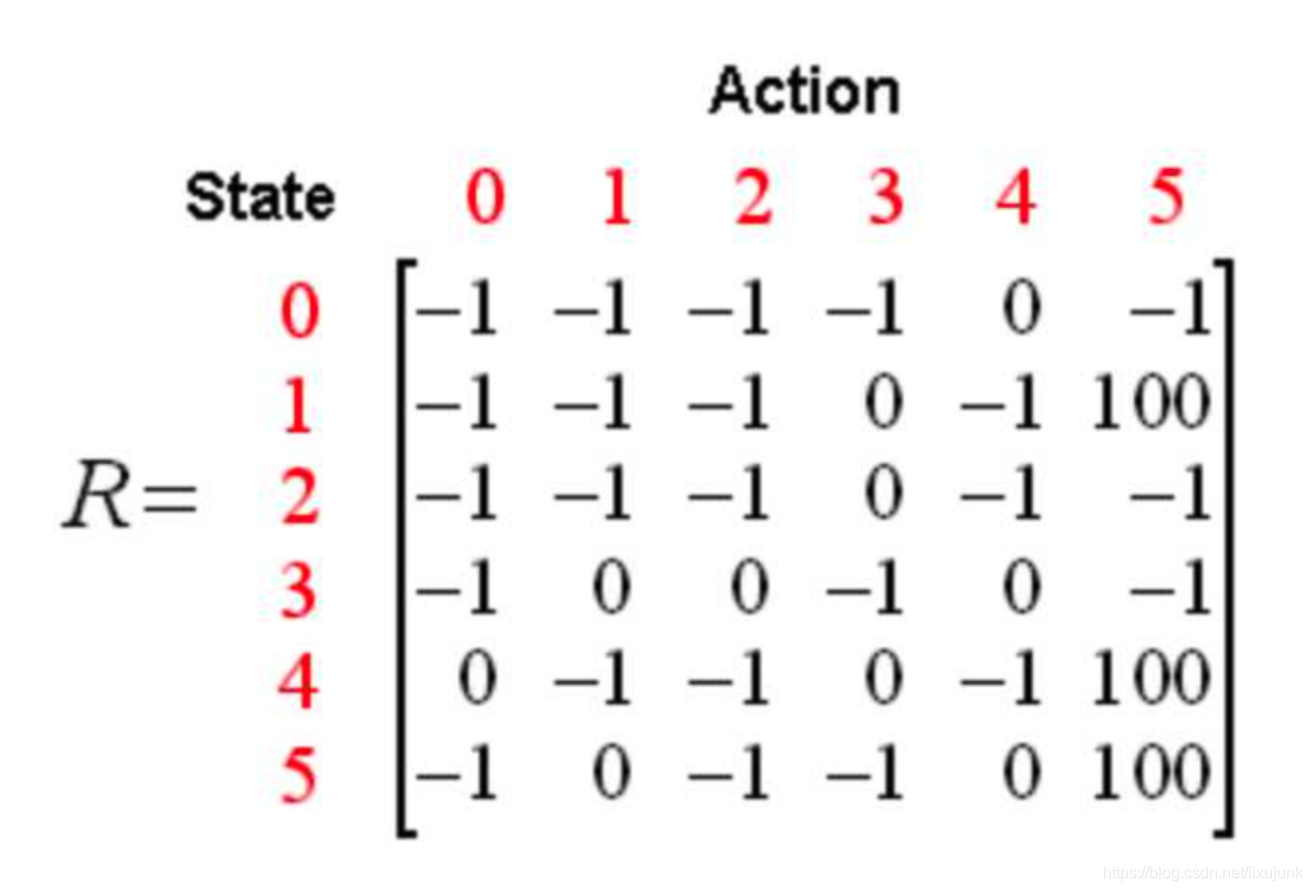
第二个是经验矩阵Q,举证的维度和奖励矩阵R一样。矩阵的每一位代表从x轴到y轴对应位置这个行为能实现可以最后到达目的地的经验值。经验值是计算得到的,矩阵的初始值是0。

迭代计算后的矩阵为
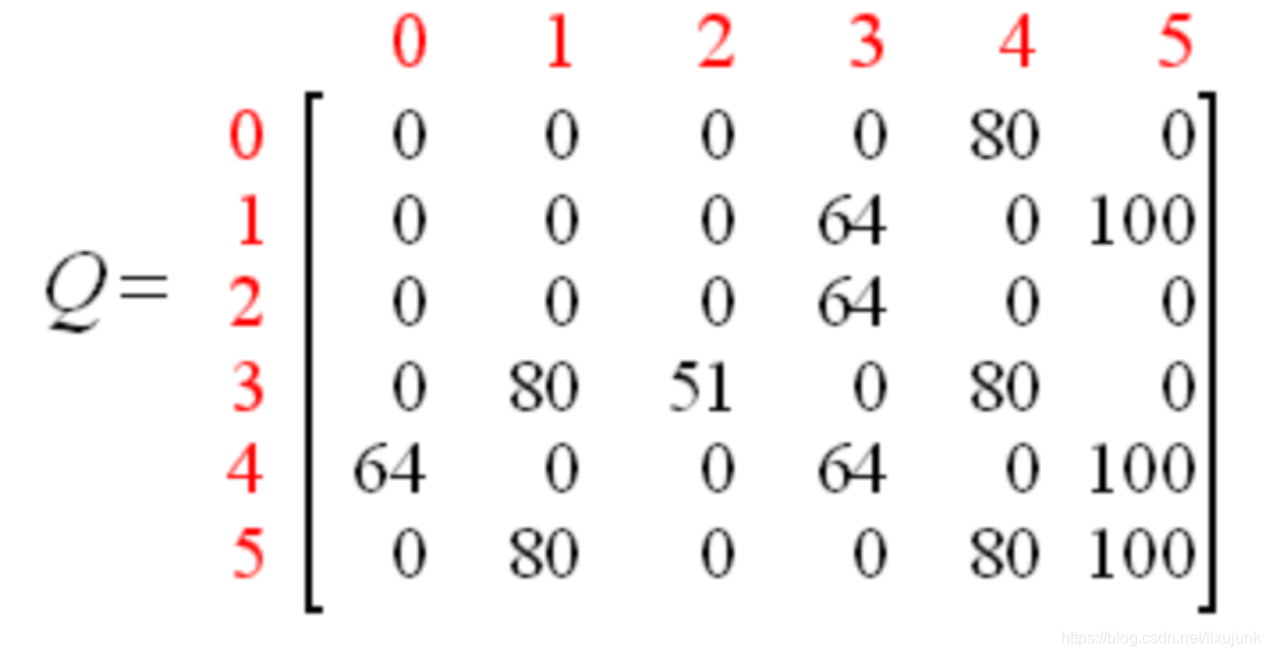
最后的结果就是得到这个经验矩阵,然后对应从x轴到y轴的取最大经验值的路径走。计算的思路就是不管在哪个初始位置上,取当前一步的最大奖励加上已有第一步位置的下一步最大经验值,就好像我们在下棋的时候要多想几步一样,然后加的时候打个折扣。
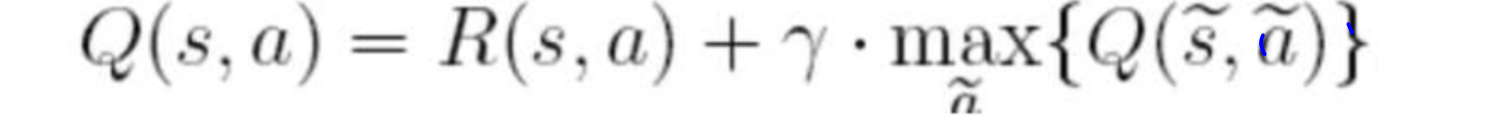
也有用复杂一点的,就是将当前地经验值按比例加上:
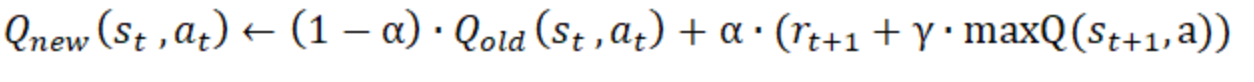

















 2170
2170

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









