









show PROCESSLIST;
SHOW engine INNODB STATUS;
mysql语法基础:
rand()*数字;//获取随机数
floor//只取整数 select floor(2.35) from dual;----2
round(数字,保留位数);//四舍五入
select round(2.5) from dual;---3
select round(2.537,1) from dual; ---2.5 保留一位小数
select round(2.537,2) from dual; ---2.54 保留两位小数
SELECT floor(RAND() * (SELECT MAX(id) FROM `table`))




有关delete truncate
1.truncate无论大小都非常快,用rollback命令delete可以撤销,而truncate则不会被撤销
2。truncate是ddl语句【被隐式提交】,不能对truncate使用rollback
3.truncate将重新设置所有的索引【成初始大小】,对整个表和索引进行浏览时,经过truncate操作后的表比delete快很多
4.truncate不触发任何delete触发器
视图:
一,什么是视图:
查看数据表中数据的一种方式
提供了存储预定义的查询语句作为数据库中对象,以备以后使用的准备
视图只是一种逻辑对象,不是物理对象,因此不占物理存储空间
视图中被查询的表叫基表
二,视图的优点:
1.集中用户使用的数据
2.简化用户权限管理
3.为向其他应用程序输出而重新组织数据
三,创建视图:
实例1。
create view dbo.vw_cjd(name,cid,result)
as select name ,report.cid,report.result
from student join report on student.sid = report.sid
实例2.
create view dbo.vw_avg(sepciality,avage)
as select speciality,avg(age)
from student
group by speciality
四。修改删除视图
修改视图
ALTER VIEW vw_cjd
AS Select name, report.cid, report.result, address
From student join report ON student.sid=report.sid
删除视图:
drop view vw_cjd
==========================================================================================================
业务需求,
更新一张表的某个字段,赋值为一个字符串和另外一个字段的某些字符串的拼接
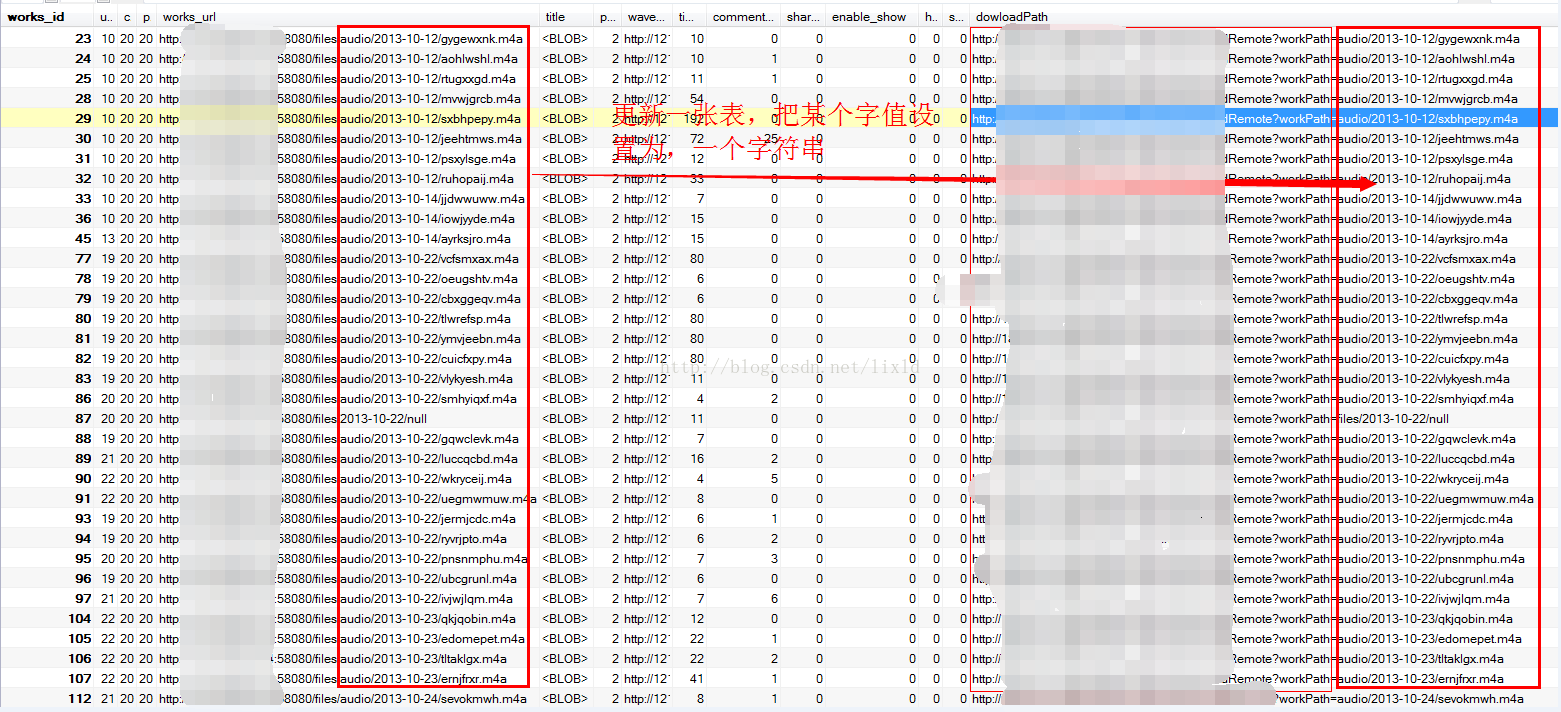
update xy_works a,
(select b.works_id,concat('http://xxxxxxxx/downloadRemote? workPath=',substring_index(b.works_url,'/',-3) ) as downloadPath from xy_works b) x
set a.dowloadPath = x.downloadPath
where a.works_id = x.works_id
折腾半天根本原因在于:
1,首先对update认识不足,update后面写的就是多个表【有关联关系的】
好友数量修正脚本:
update xy_user ,(select initiative_user_id, count(*) friendnumber from xy_user_friend where status=1 group by initiative_user_id) friendCount
set friend_count = friendCount.friendnumber
where xy_user.user_id = friendCount.initiative_user_id
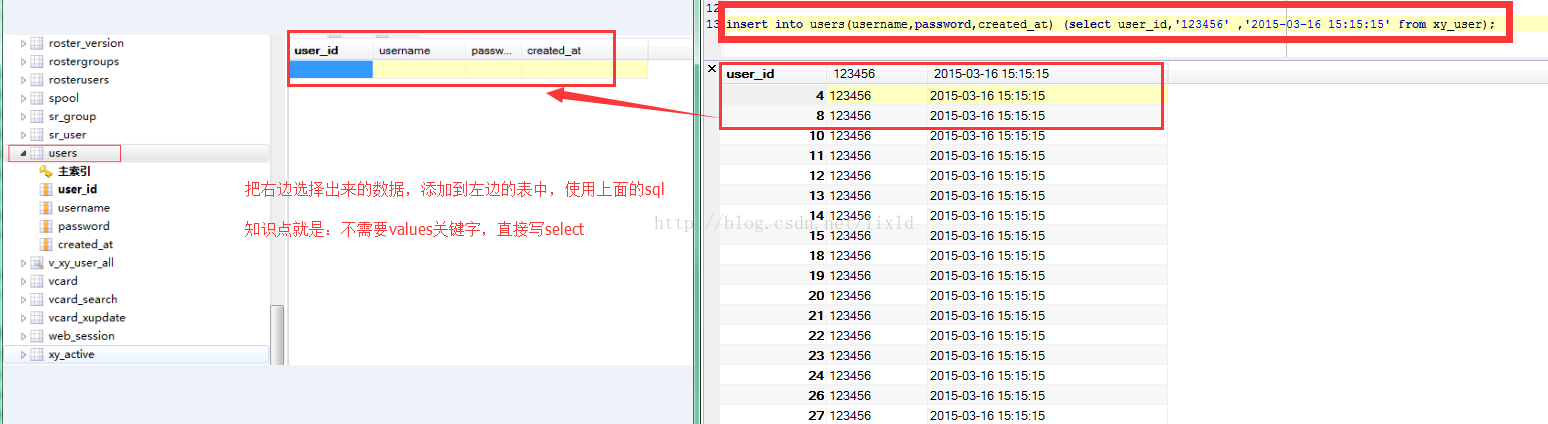
新的业务需求:把一张表的某个字段,复制到另外一张表的某个字段,
技术点注意:没有value关键字
insert into users(username,password,created_at ) (select user_id ,'123456','2015-03-16 15:15:15' from xy_user);
今天清理垃圾数据用到的group by 字句:
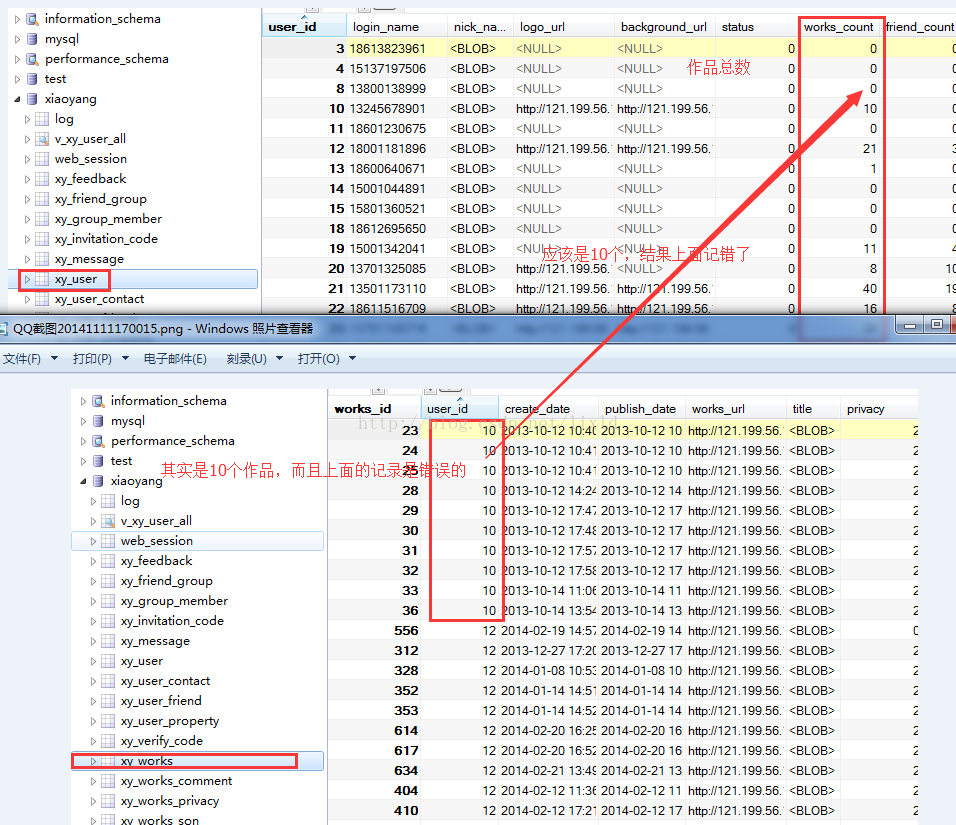
说白了就清理数据吧,真实的值写到主表的字段里面:
用到sql语句
update xy_user a ,
(select user_id,count(works_id) as worksrealCount from xy_works group by user_id ) b
set a.works_count = b.worksrealCount
where a.user_id = b.user_id and a.works_count!= b.worksrealCount
核心语句在这里:groupby 和count()函数配合使用
还注意有个having的用法
一般这样用:having count(*) > 1
今天遇到一个mysql报错:too many connection
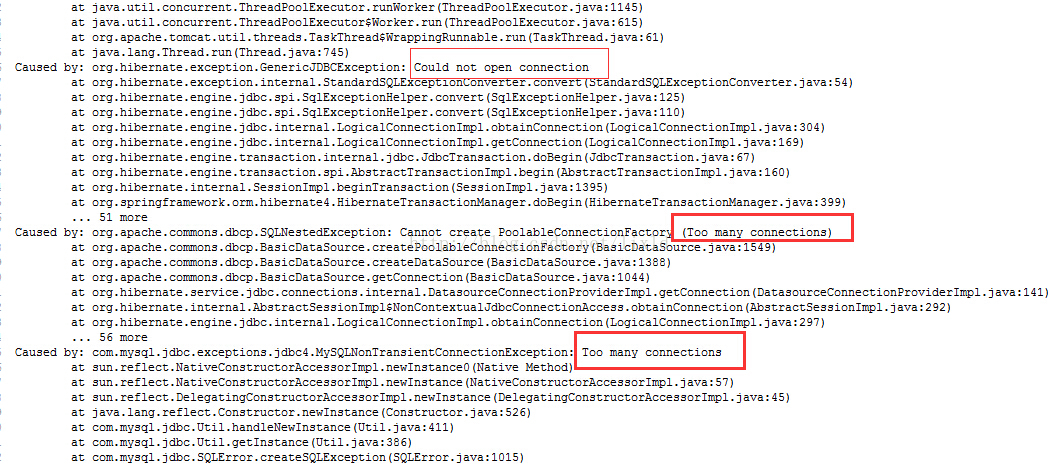
解决办法:
show variables like '%max_connections%'----查看目前连接数有多少
set GLOBAL max_connections=500-----重新设置最大连接数【前提是admin用户】
=============union 和union all 和or 和in=================
作用:将两个或更多查询的结果组合为单个结果集,该结果集包含联合查询中的所有查询的全部行
使用前提:所选记录的两个表的字段要一致【所有查询中的列数和列的顺序必须相同。】
union 系统会自动将重复的元素去掉【隐藏着对结果的排序】,因为去重,所以明显效率低,
union all 则只是简单合并,保留重重复元组,效果高多了\
Or 实现union同样的功能
区别:
or用不上索引,而用union all可以用上索引
推荐一篇好文章:union uion all or in效率比较
下面是示例:

如下SQL语句:
SELECT irdno FROM birdird
WHERE irdid='RD' AND (irdserial='833006' OR irdmodel='833020')【or造成全表扫描,用不上索引,所以效率不高】
1.分别搜索irdserial='833006'与irdmodel='833020'(两次扫描),这时在非聚集索引上进行处理结果存入临时数据库的工作表中
2.排序去重,得到irdserial='833006'与irdmodel='833020'的结果集
3.再在这个结果集上搜索irdno='RD'
SELECT irdno FROM birdird WHERE irdid='RD' AND irdserial='833006'
UNION ALL
SELECT irdno FROM birdird WHERE irdid ='RD' AND irdmodel='833020'
1.分别搜索 irdid='RD' AND irdserial='833006'与irdid ='RD' AND irdmodel='833020'()
2.合并得到结果
SELECT irdno FROM birdird WHERE irdid='RD' AND irdserial='833006'
UNION
SELECT irdno FROM birdird WHERE irdid ='RD' AND irdmodel='833020'
1.分别搜索 irdid='RD' AND irdserial='833006'与irdid ='RD' AND irdmodel='833020'()
2.合并得到的结果
3.对结果排序,然后去重
该表建立了聚集索引irdno,并且在irdserial和irdmodel上分别建立了非聚集索引
为何UNION ALL的性能最高,而OR的性能最差了?????【or造成全表扫描,用不上索引,所以效率不高】
下面是梳理现网用户昵称二级制昵称到varchar字段中,用于搜索时不分大小写
搜索的时候,不区分大小写,sql写法:关键词upper
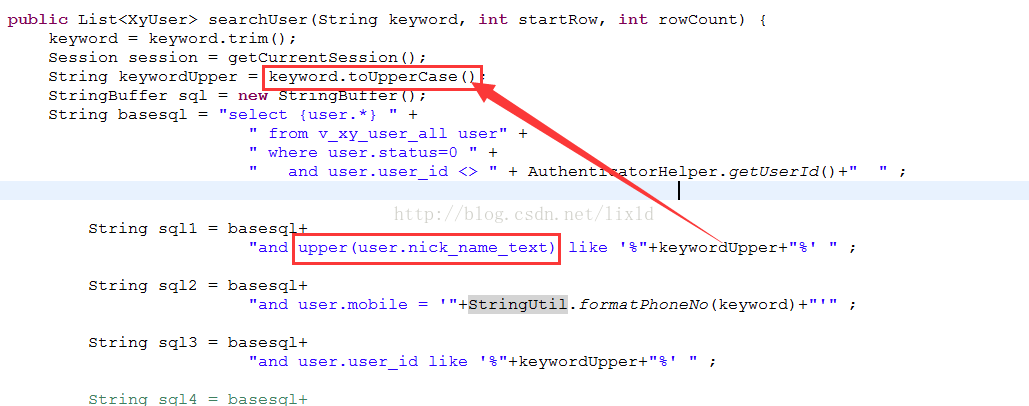
mysql获取系统时间:
select now();
2015-04-09 12:13:37
mysql获取当前的和当天的数据【注意有个mysql函数TO_DAYS()】,思路就是和当前时间做减法
select count(*)
from xy_user a,xy_user_property b
where a.user_id = b.user_id and TO_DAYS(NOW())-TO_DAYS(b.register_datetime) =0
mysql获取当前的和前一天的数据【注意有个mysql函数TO_DAYS()】,思路就是和当前时间做减法
select count(*)
from xy_user a,xy_user_property b
where a.user_id= b.user_id and TO_DAYS(NOW())-TO_DAYS(b.register_datetime) = 1
mysql获取当前的和前一个小时的数据【注意有个mysql函数data_sub()】,思路就是和当前时间做减法
works.create_date>date_sub(now(), interval 1 hour)
=============================================================
实现中文和英文排序用convert 函数
select * from xy_user where user_id in(
select a.passive_user_id
from xy_user_friend a
where a.initiative_user_id = 1821 and a.status=1)
order by convert(nick_name USING gbk) COLLATE gbk_chinese_ci
这样的顺序是:数字,英文,汉字,都是按这样a-z的顺序排列!
replace函数的使用
修改表中某个字段--把双空格,变为单空格
UPDATE `xy_user_property`
SET `last_login_ip_address` = replace (`last_login_ip_address`,' ',' ') WHERE `last_login_ip_address` LIKE '% %'
2.0.1版本上线工作
1,执行脚本,把所有用户的位置信息都加上
http://localhost:8080/xiaoyangNew/user/setRealAddress.do
2.数据库表结构更新
3.标签库这里的改动
步骤1:上线后把,首先把用户之前的标签都清掉。
脚本:update xy_user_property set tag_id = null
步骤2:修改接口
public List<UserTagVO> getAllUserTags() throws Exception{
public List<WorkTag> getAllWorkTags()
上线后把这个接口的调用改为和getAllUserTags()_v2_0_1一样的逻辑
目的是保证现在网用户也用新的标签库,打标签
今天遇到下面个这个异常:
com.mysql.jdbc.exceptions.jdbc4.MySQLSyntaxErrorException: You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'O' union
select user.* from xy_user_property user where mobile like '%RE'O%' or' at line 1
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
解决办法:在程序里对查询条件进行处理,如果把当引号,都替换为两个单引号,这样就ok了,下面是脚本测试结果:
同样的道理,所以如果sql语句中查询条件是用双引号,则如果查询条件中包含双引号也报错
解决办法就是把一个双引号换成两个双引号
总结:查询条件中的转义字符,应该是根据你所写的sql来判断java中如何转换:
如果是sql条件用“"引起来,sql.replaceAll(""","""")用两个双引号代替一个
如果是sql条件用’‘引起来,sql.replaceAll("‘","’‘")用两个单引号代替一个
=====================mysql随机获取几条记录================================
【主要用到一个特殊的order by】 order by rand();
同事添加条数限制 limit xxx
示例:
select * from xy_user order by rand() limit 8;
这样的写法效率低下
下面改进用join方法 连接一张自动生成id的表
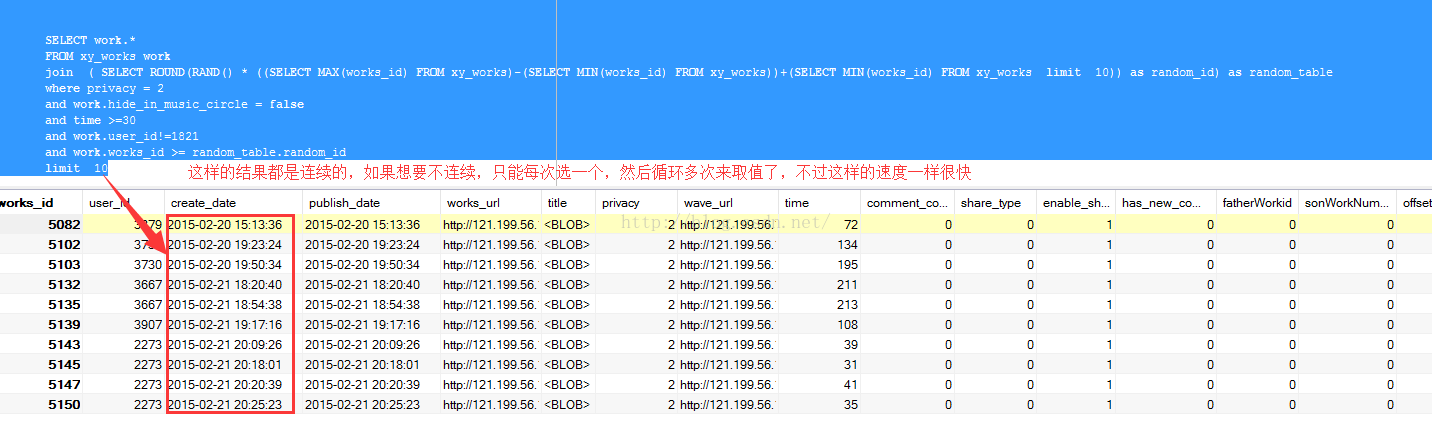
但是遇到的问题是:查询的结果都是连续的
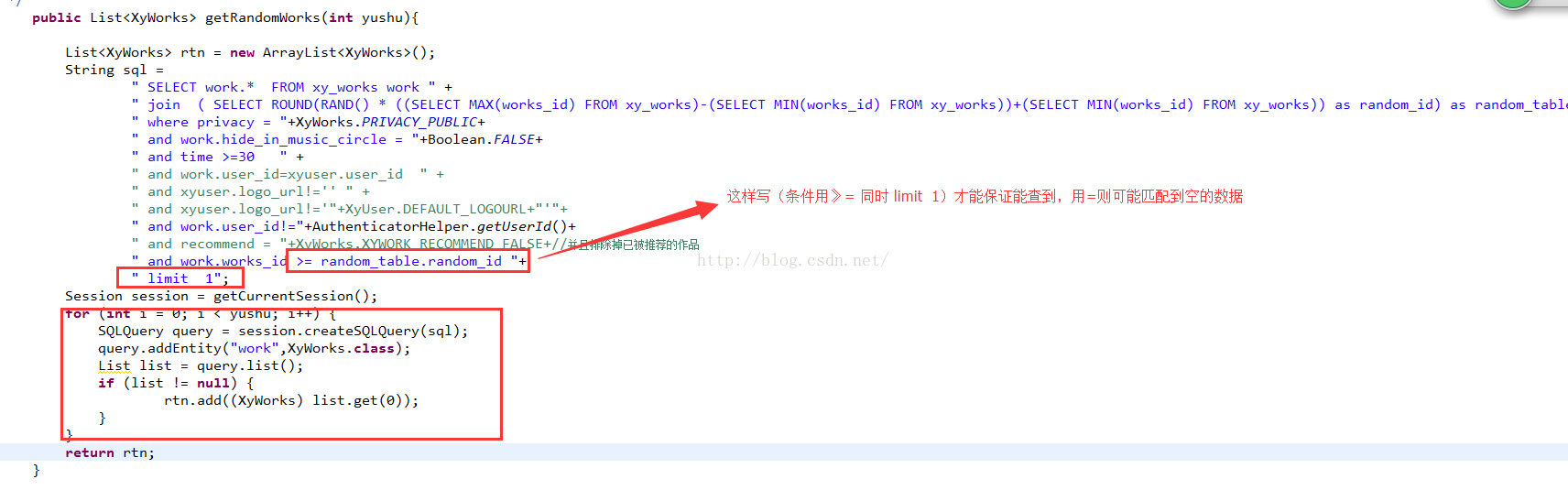
===================================查询某字段中是否包含有某些字符============================
用到sql的instr函数instr(字段,‘包含的字符串’)>1则证明存在
select xy_works.*
from xy_works
where instr(xy_tag_ids,'13')>1
order by recommend desc,create_date desc
有关去重的专辑:http://www.jb51.net/article/23964.htm
mysql给表添加联合唯一约束
ALTER TABLE jw_resource
ADD UNIQUE KEY(resource_name, resource_type);
查询使用
case
when **** then **
when **** then **
end as xxxCASE
WHEN uq.answer=1 THEN '能'
WHEN uq.answer=2 THEN '不能'
WHEN uq.answer=3 THEN '不清楚'
END AS answer
from cp_user_question uq
LEFT JOIN cp_question cp on uq.question_id = cp.id
where uq.user_id = 669169

















 2490
2490

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









