




 该实验通过Python调用聆心云心理健康服务平台API获取沙盘游戏数据,统计游戏次数,并将操作数据写入文本文件。接着使用jieba分词和wordcloud库生成词云图,展示了数据可视化的应用,加深了对数据可视化的理解和Python的使用。
该实验通过Python调用聆心云心理健康服务平台API获取沙盘游戏数据,统计游戏次数,并将操作数据写入文本文件。接着使用jieba分词和wordcloud库生成词云图,展示了数据可视化的应用,加深了对数据可视化的理解和Python的使用。
实验题目:聆心云心理健康服务平台数据可视分析和可视化
实验目的和要求:统计出在聆心云平台做沙盘游戏的次数、根据各次沙盘游戏所使用的沙具和进行的操作数据进行词云可视化,掌握Python词云制作方法
实验步骤:
1.定义函数getUserInfo(),获取用户输入的聆心云平台用户名和密码
def getUserInfo(): #获取用户输入(聆心云平台用户名和密码)
userInfo={}
userInfo['mobile']=input("请输入聆心云用户名(注册账号的手机号码):")
userInfo['passwd']=input("请输入密码:")
return userInfo
2. 定义函数getIdList(userInfo),参数为步骤1获取的用户名和密码,通过聆心云心理健康服务平台API获取所有沙盘游戏id,并统计出游戏次数:
def getIdList(userInfo): #获取所有沙盘id
idList=[]
url='https://lingxinyun.cn/sp/getIdByAuth'
try:
r=requests.get(url,params=userInfo,timeout=30)
r.raise_for_status()
ls=json.loads(r.text)
for e in ls:
idList.append(e['id'])
print("共做了{}次沙盘游戏。".format(len(idList))) #打印做沙盘的次数
return idList
except:
return "服务器异常!"
效果如下:
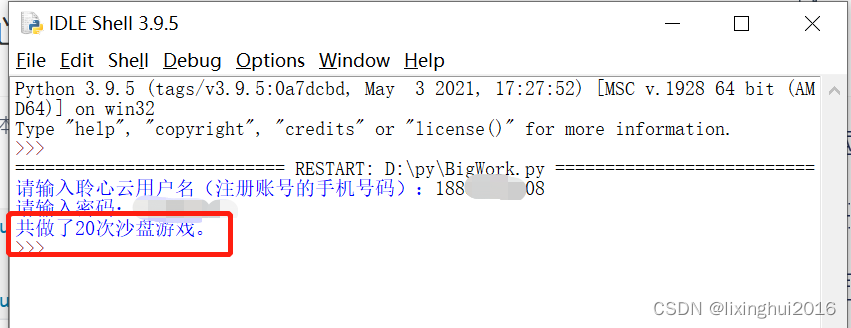
3. 定义函数generateTextFile(idList),入参为步骤2获取的所有沙盘id,该函数的作用是通过这些id依次获取所有沙盘游戏所使用的沙具和进行的操作数据,并输出到文本文件data.txt。
def generateTextFile(idList): #获取所有沙盘游戏所使用的沙具和进行的操作数据,输出到文本文件
begin=time.time()
text=""
url='https://lingxinyun.cn/sp/getSandPlay?id='
try:
fo=open("data.txt","w",encoding='utf-8')
for id in idList:
r=requests.get(url+str(id),timeout=30)
r.raise_for_status()
r.encoding='utf-8'
fo.writelines(r.text+"\n")
fo.close()
end=time.time()
s=end-begin
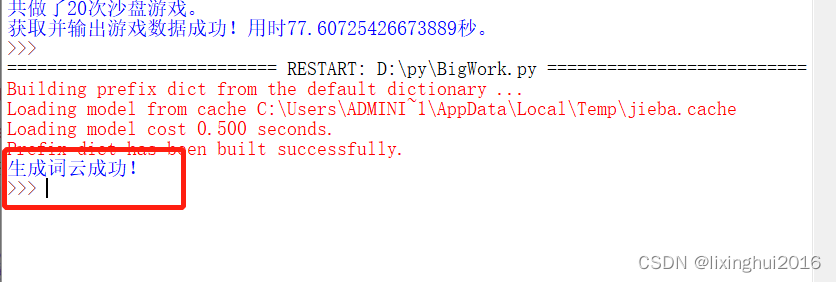
print("获取并输出游戏数据成功!用时{}秒。".format(s))
except:
return "服务器异常!"
运行结果如下:
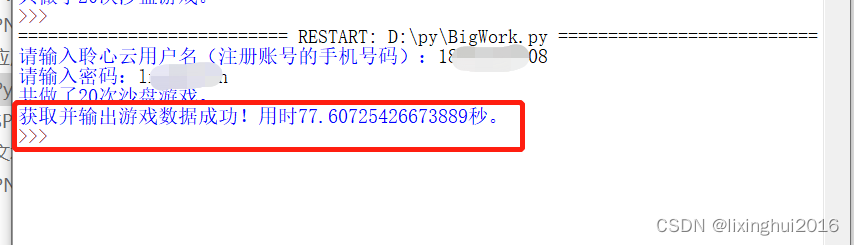
生成的文件如下:

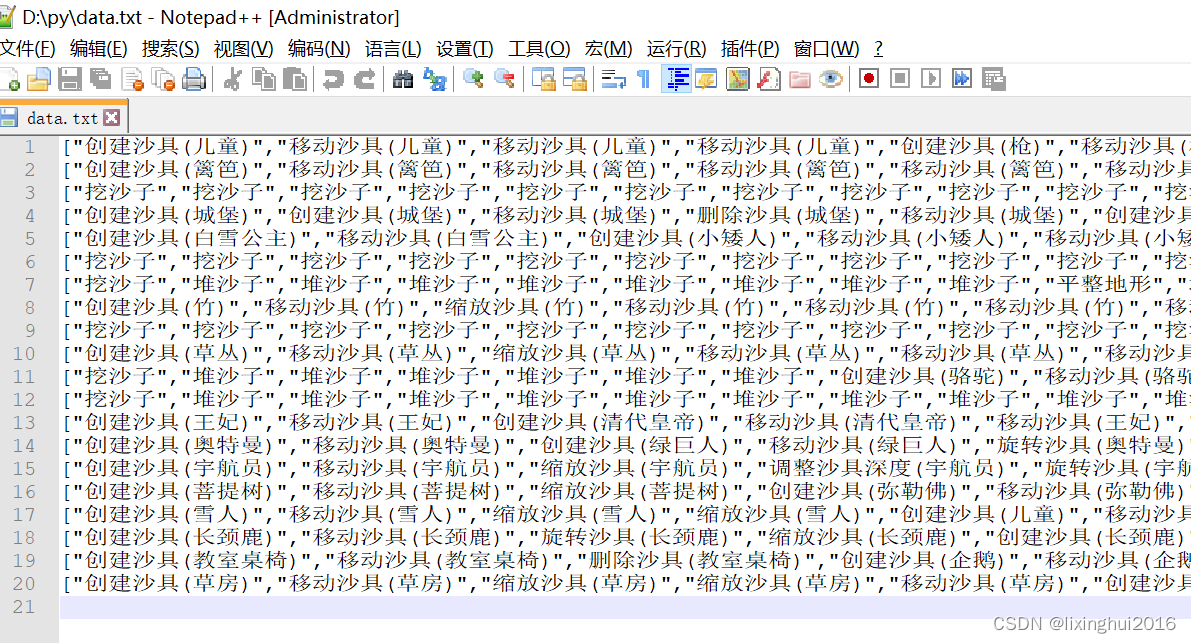
4.词云生成前的准备工作,安装第三方库wordcloud、jieba、imageio,jieba库用来对中文进行分词处理,imageio库用来读取背景图片,wordcloud库用来生成词云图片,windows下分别在命令行输入以下命令进行安装:
pip install wordcloud
pip install jieba
pip install imageio
准备一张背景图放到目录下,可根据背景图生成词云的形状
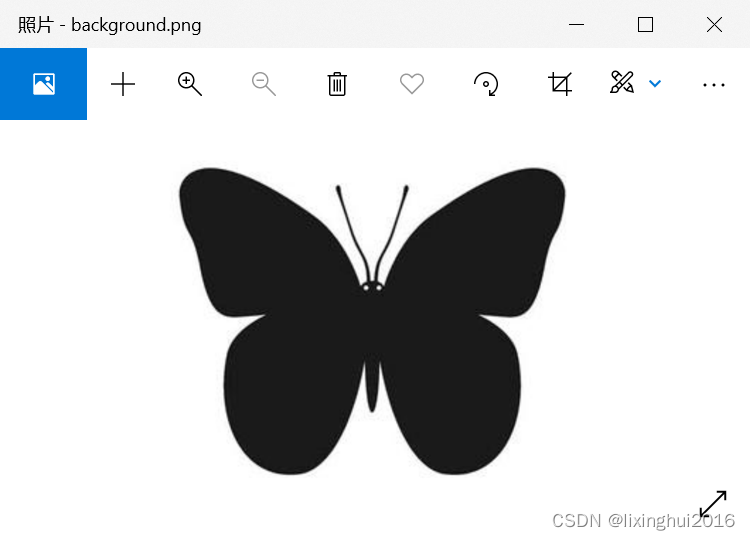
5. 定义函数generateWordcloud(),根据文本文件和背景图片生成词云。
def generateWordcloud(): #根据文本文件生成词云
fo=open('data.txt',encoding='utf-8')
t=fo.read() #读取操作数据
fo.close()
words = jieba.lcut(t) # 使用jieba库进行分词
txt = ' '.join(words) # 使用join()方法,将分词生成的字符串以空格进行分割。因为在生成词云时,字符串之间需要为空格
background_image=imageio.imread('background.png') #读取背景图片
w=wc.WordCloud(background_color='white',# 设置背景颜色
font_path = 'C:/Waedows/Fonts/simfang.ttf',# 设置字体
mask=background_image # 设置背景图片
)
w.generate(txt) #生成词云
w.to_file('WordCloud.png') # 生成图片
print("生成词云成功!")
运行结果如下:
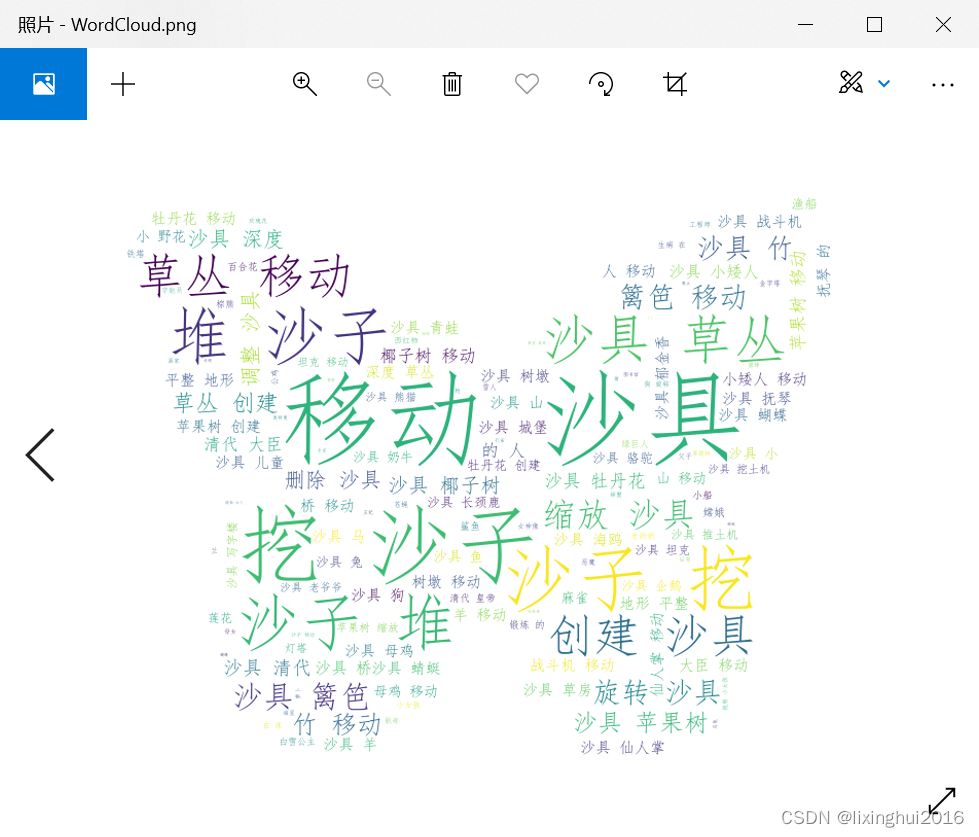
最后生成的词云效果:
附完整代码:
import requests
import json
import time
import wordcloud as wc
import jieba
import imageio
def getUserInfo(): #获取用户输入(聆心云平台用户名和密码)
userInfo={}
userInfo['mobile']=input("请输入聆心云用户名(注册账号的手机号码):")
userInfo['passwd']=input("请输入密码:")
return userInfo
def getIdList(userInfo): #获取所有沙盘id
idList=[]
url='https://lingxinyun.cn/sp/getIdByAuth'
try:
r=requests.get(url,params=userInfo,timeout=30)
r.raise_for_status()
ls=json.loads(r.text)
for e in ls:
idList.append(e['id'])
print("共做了{}次沙盘游戏。".format(len(idList))) #打印做沙盘的次数
return idList
except:
return "服务器异常!"
def generateTextFile(idList): #获取所有沙盘游戏所使用的沙具和进行的操作数据,输出到文本文件
begin=time.time()
text=""
url='https://lingxinyun.cn/sp/getSandPlay?id='
try:
fo=open("data.txt","w",encoding='utf-8')
for id in idList:
r=requests.get(url+str(id),timeout=30)
r.raise_for_status()
r.encoding='utf-8'
fo.writelines(r.text+"\n")
fo.close()
end=time.time()
s=end-begin
print("获取并输出游戏数据成功!用时{}秒。".format(s))
except:
return "服务器异常!"
def generateWordcloud(): #根据文本文件生成词云
fo=open('data.txt',encoding='utf-8')
t=fo.read() #读取操作数据
fo.close()
words = jieba.lcut(t) # 使用jieba库进行分词
txt = ' '.join(words) # 使用join()方法,将分词生成的字符串以空格进行分割。因为在生成词云时,字符串之间需要为空格
background_image=imageio.imread('background.png') #读取背景图片
w=wc.WordCloud(background_color='white',# 设置背景颜色
font_path = 'C:/Waedows/Fonts/simfang.ttf',# 设置字体
mask=background_image # 设置背景图片
)
w.generate(txt) #生成词云
w.to_file('WordCloud.png') # 生成图片
print("生成词云成功!")
userInfo=getUserInfo()
idList=getIdList(userInfo)
generateTextFile(idList)
generateWordcloud()
实验总结:通过本次实验加深了对数据可视化的理解,学到了文本数据可视化——词云图的制作方法,感受到用Python制作词云的方便快捷,代码简洁,Python安装第三方库也快速高效,体现了Python语言的庞大的计算生态,对Python语言有了更深刻的认识。


















 911
911




 到【灌水乐园】发言
到【灌水乐园】发言







