






当我们在第三方软件或者在黑窗口中运行hive sql中的insert语句时,弹出这样的错误:[08S01][2] Error while processing statement: FAILED: Execution Error, return code 2 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask。
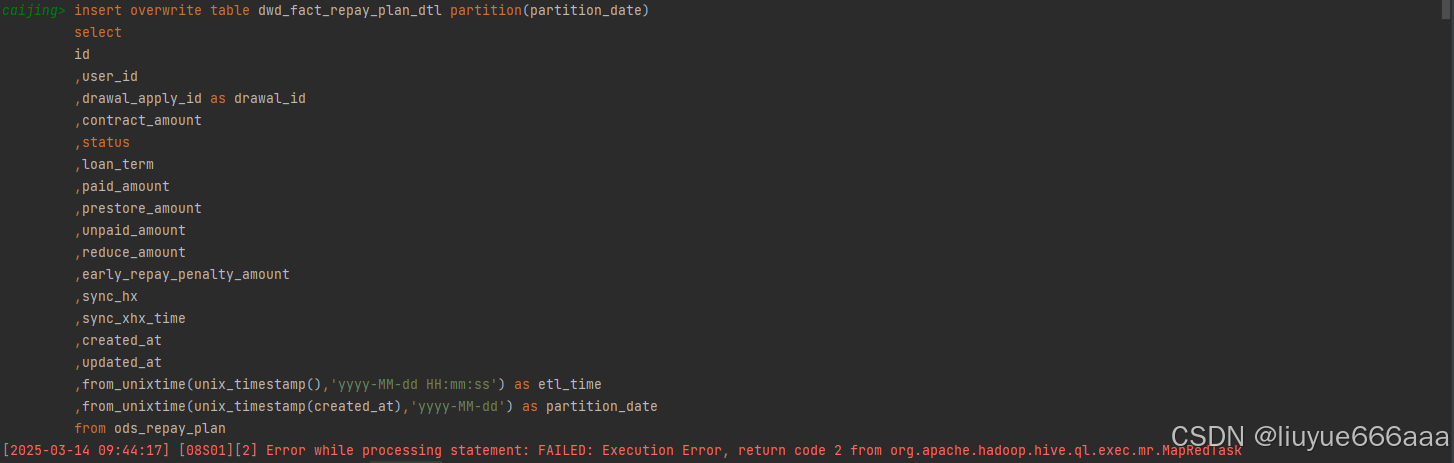
出现这样的错误的原因一般是因为hive中MapReduce任务执行默认单个节点(Node)可以创建的最大动态分区数为100,此时执行任务所需要的超过100了(由于我的日志给清除了,没办法给出具体日志信息),此时我们只需要设置如下几行代码:
SET hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
set hive.exec.max.dynamic.partitions = 100000;
set hive.exec.max.dynamic.partitions.pernode=10000;第一行代码用于开启动态分区
第二行代码用于设置动态分区的非严格模式,允许所有分区字段都是动态的(即分区字段的值来自查询结果)。 如果所有分区字段都是动态的(如 PARTITION(partition_date) 中的 partition_date 来自查询结果),必须设置为 nonstrict。
第三行代码用于设置单个查询可以创建的最大动态分区数为100000。如果查询结果中分区字段的值很多(如按天分区,数据跨越多天),需要增加该值以避免报错。设置过大会增加 Hive 元数据和 HDFS 的压力,需根据实际数据量调整。
第四行代码用于设置单个节点(Node)可以创建的最大动态分区数为10000。如果单个节点处理的数据量较大,需要增加该值以避免报错。该值不能超过 hive.exec.max.dynamic.partitions。
这些配置可以帮助优化动态分区插入操作,避免因分区数量过多而导致的错误。根据实际数据量和集群规模,可以适当调整这些参数的值。

















 2621
2621

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









