



文章目录
1. 排序的概念及引用
1.1 排序的概念
排序:所谓排序,就是使一串记录,按照其中的某个或某些关键字的大小,递增或递减的排列起来的操作。
稳定性:假定在待排序的记录序列中,存在多个具有相同的关键字的记录,若经过排序,这些记录的相对次序保持 不变,即在原序列中,r[i]=r[j],且r[i]在r[j]之前,而在排序后的序列中,r[i]仍在r[j]之前,则称这种排序算法是稳 定的;否则称为不稳定的。
内部排序:数据元素全部放在内存中的排序。
外部排序:数据元素太多不能同时放在内存中,根据排序过程的要求不能在内外存之间移动数据的排序。
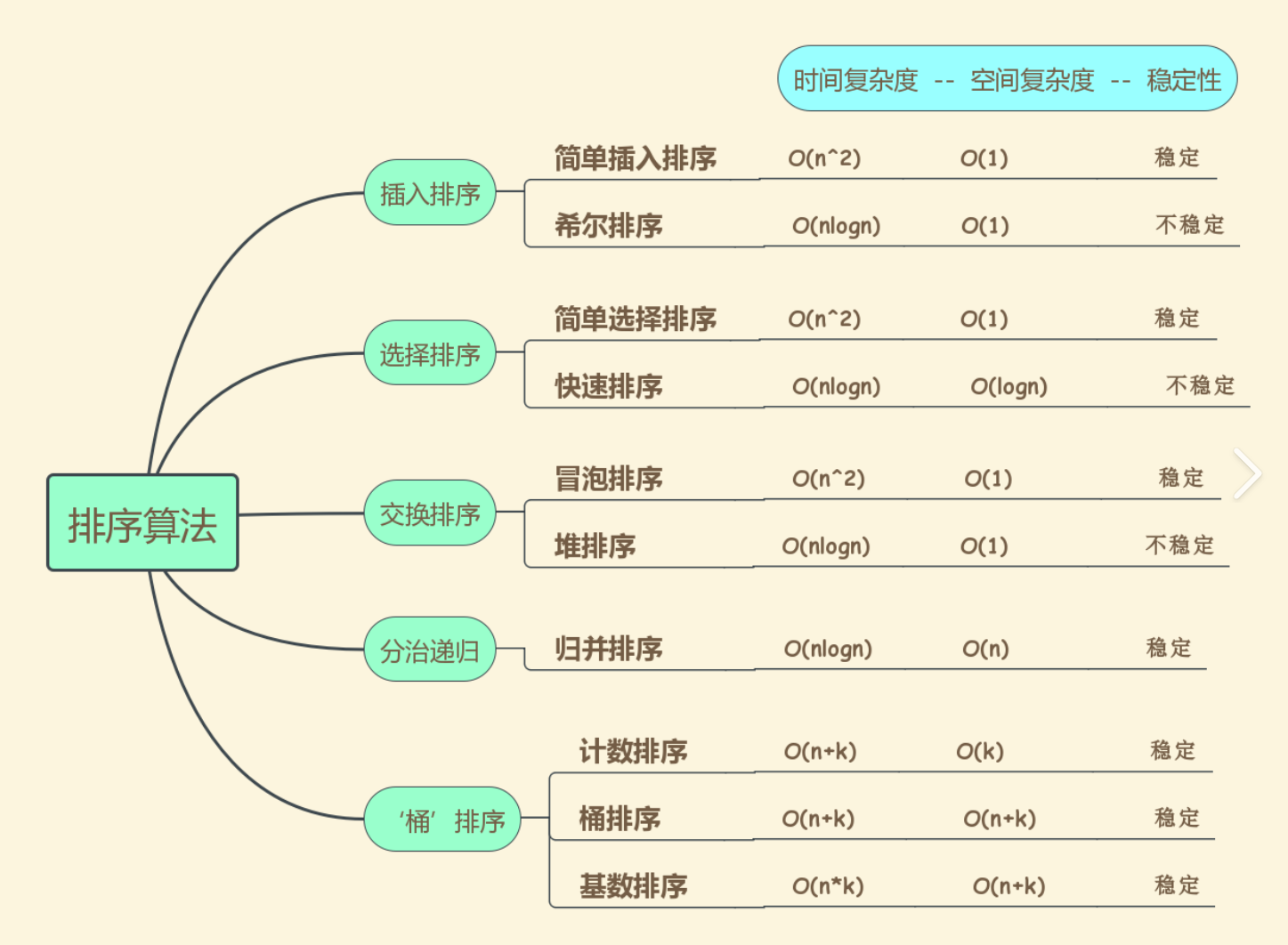
1.2 常见的排序算法
2. 常见排序算法的实现
2.1 插入排序
2.1.1基本思想:
核心思想:将待排序的序列看作一个「有序列表」和一个「无序列表」。开始时,有序列表只包含第一个元素,然后依次将无序列表中的元素「插入」到有序列表中的正确位置,直到无序列表为空,排序完成。
一个非常贴切的现实比喻是:整理手中的扑克牌。
- 你左手一开始是空的(代表无序列表),右手拿着所有牌(代表有序列表,但初始时只有一张)。
- 你从右手中拿起一张牌(无序列表的第一个元素),插入到左手中合适的位置,保证左手牌始终有序。
- 重复这个过程,直到右手所有牌都插入到左手。
2.1.2 直接插入排序
将待排序的元素逐个插入到一个已经排好序的序列中,从而得到一个新的、元素数增1的有序序列,直到所有元素都插入完毕。
直接插入排序的特性总结:
-
元素集合越接近有序,直接插入排序算法的时间效率越高
-
时间复杂度:O(N^2)
-
空间复杂度:O(1),它是一种稳定的排序算法
-
稳定性:稳定
2.1.3 希尔排序( 缩小增量排序 )
- 宏观调整,微观插入:
- 首先,它把较大的数据集合分割成若干个逻辑上的子序列,这些子序列由相隔某个“增量”的元素组成。
- 然后对这些子序列分别进行直接插入排序。
- 由于一开始每组的元素数量很少,所以排序很快。随着增量的减小,整个数组变得越来越“基本有序”。
- 逐步细化:
- 通过逐渐减小这个“增量”,重复上述分组和排序的过程。
- 当增量减至 1 时,整个数组被当作一个序列来进行最后一次直接插入排序。由于此时数组已经“基本有序”,所以这次排序会非常快。
希尔排序的特性总结:
-
希尔排序是对直接插入排序的优化
-
当gap > 1时都是预排序,目的是让数组更接近于有序。当gap == 1时,数组已经接近有序的了,这样就会很 快。这样整体而言,可以达到优化的效果。我们实现后可以进行性能测试的对比。
-
希尔排序的时间复杂度不好计算,因为gap的取值方法很多,导致很难去计算,因此在好些树中给出的希尔排 序的时间复杂度都不固定:
-
稳定性:不稳定
2.2 选择排序
2.2.1基本思想:
每一轮从未排序序列中找出最小(或最大)的元素,将其放到已排序序列的末尾。通过这种“选择”的过程,逐步构建有序序列。
2.2.2 直接选择排序:
对于数组 a[],长度为 n:
- 初始化:已排序序列为空,未排序序列为整个数组
[0...n-1]。 - 外层循环:执行
n-1轮(i从0到n-2)。- 每一轮开始时,
a[0...i-1]是已排序序列,a[i...n-1]是未排序序列。
- 每一轮开始时,
- 内层循环(查找最小值):
- 设定当前最小值位置
min_index = i。 - 从
j = i+1到n-1遍历未排序序列。 - 如果
a[j] < a[min_index],则更新min_index = j。 - 此过程通过顺序比较找出未排序序列中的最小元素的位置。
- 设定当前最小值位置
- 交换:
- 如果
min_index不等于i,则交换a[i]和a[min_index]。 - 此时,
a[i]被纳入已排序序列,且位于正确的位置。
- 如果
直接选择排序的特性总结:
- 时间复杂度:O(N^2)
- 空间复杂度:O(1)
- 稳定性:不稳定
2.2.3 堆排序
- 建堆:将待排序的数组构建成一个大顶堆(或小顶堆)。
- 大顶堆:每个节点的值都大于或等于其子节点的值。堆顶元素是最大值。
- 小顶堆:每个节点的值都小于或等于其子节点的值。堆顶元素是最小值。
- (通常升序排序使用大顶堆,降序排序使用小顶堆)
- 排序:
- 交换:将堆顶元素(最大值)与堆的最后一个元素交换。
- 调整:此时,最大值已位于其最终排序位置。将剩余的元素重新调整成一个大顶堆。
- 重复:重复上述交换和调整过程,直到堆中只剩下一个元素。
堆排序的特性总结:
- 堆排序使用堆来选数,效率就高了很多。
- 时间复杂度:O(N*logN)
- 空间复杂度:O(1)
- 稳定性:不稳定
2.3 交换排序
是通过比较两个元素的关键字,如果它们的顺序错误,就交换它们的位置,直到整个序列有序为止。
2.3.1冒泡排序
对于一个数组 arr,长度为 n:
- 从头开始:从数组的第一个元素开始,比较相邻的元素。
- 比较与交换:
- 如果第一个元素比第二个元素大 (
arr[j] > arr[j+1]),就交换它们的位置。 - 如果顺序正确,则不做任何操作。
- 如果第一个元素比第二个元素大 (
- 向后移动:移动到下一对相邻元素,重复步骤2。
- 完成一轮:当对数组的最后一对相邻元素完成操作后,这一轮中最大的元素就已经被“冒泡”到了数组的末尾。
- 重复过程:针对所有的元素重复以上的步骤,除了最后一个(因为它已经是最大的了)。
- 终止条件:直到没有任何一对数字需要交换,则排序完成。
冒泡排序的特性总结
- 时间复杂度:O(N^2)
- 空间复杂度:O(1)
- 稳定性:稳定
2.3.2 快速排序
- 分解:
- 从数列中挑出一个元素,称为 “基准”。
- 重新排列数列,将所有比基准小的元素放在基准前面,所有比基准大的元素放在基准后面(相等的数可以到任一边)。这个操作称为 分区 操作。
- 分区操作结束后,基准元素就处于数列的最终位置上。
- 递归求解:
- 递归地对基准值左边的子数列和右边的子数列进行快速排序。
- 合并:
- 因为子数列都是原地排序的,所以不需要合并操作,整个序列已经有序。
简单来说就是:选一个数当“标杆”,把小的放左边,大的放右边,然后递归处理左右两边。
常见写法有:
- Hoare版
private static int partitonHoare(int[] array, int left, int right){
int tmp = array[left];
int tmpLeft = left;
while(left < right){
while (left < right && array[right] >= tmp){
right--;
}
while (left < right && array[left] <= tmp){
left++;
}
swap(array,left,right);
}
swap(array,left,tmpLeft);
return left;
}
- 挖坑法(常用)
private static int partiton(int[] array, int left, int right) {
int tmp = array[left];
while (left < right){
while (left < right && array[right] >= tmp){
right--;
}
array[left] = array[right];
while (left < right && array[left] <= tmp){
left++;
}
array[right] = array[left];
}
array[left] = tmp;
return left;
}
- 前后指针
private static int partition2(int[] array, int left, int right){
int prev = left;
int cur = left+1;
while(cur <= right){
if (array[cur] < array[left] && array[++prev] != array[cur]){
swap(array,cur,prev);
}
cur++;
}
swap(array,prev,left);
return prev;
}
快速排序优化:
- 三数取中法选key
- 递归到小的子区间时,可以考虑使用插入排序
冒泡排序的特性总结:
- 快速排序整体的综合性能和使用场景都是比较好的,所以才敢叫快速排序
- 时间复杂度:O(N*logN)
- 空间复杂度:O(logN)
- 稳定性:不稳定
2.4 归并排序
2.4.1 基本思想
- 分解:
- 将当前待排序的数组递归地分成两个长度相等(或相差1)的子数组。
- 持续进行分解,直到每个子数组只包含一个元素。此时,可以认为这些单元素数组都是有序的。
- 解决:
- 递归地对两个子数组分别进行归并排序。
- 当子数组被分解到只剩一个元素时(自然有序),递归“开始回升”。
- 合并:
- 将两个已经排序好的子数组合并成一个新的有序数组。
- 这是归并排序的核心操作,通过比较两个子数组的元素,依次选择较小的元素放入新数组中,直到所有元素都被处理。
简单来说就是:先拆到最小(一个元素),再两两有序合并,最终合并成一个完整的有序数组。
一个形象的比喻是:整理两叠已经按学号排好序的作业本。
- 你不需要重新对所有作业本排序。
- 你只需要每次比较两叠最上面的那本作业,取出学号较小的那本,放到新的位置上。重复这个过程,就能将两叠有序的作业本合并成一叠更大的有序作业本。
归并排序总结
- 归并的缺点在于需要O(N)的空间复杂度,归并排序的思考更多的是解决在磁盘中的外排序问题。
- 时间复杂度:O(N*logN)
- 空间复杂度:O(N)
- 稳定性:稳定
2.4.3 海量数据的排序问题
外部排序:排序过程需要在磁盘等外部存储进行的排序
前提:内存只有 1G,需要排序的数据有 100G
因为内存中因为无法把所有数据全部放下,所以需要外部排序,而归并排序是最常用的外部排序
- 先把文件切分成 200 份,每个 512 M
- 分别对 512 M 排序,因为内存已经可以放的下,所以任意排序方式都可以
- 进行 2路归并,同时对 200 份有序文件做归并过程,最终结果就有序了
2.排序算法复杂度及稳定性分析
| 排序算法 | 平均时间复杂度 | 最坏时间复杂度 | 最好时间复杂度 | 空间复杂度 | 稳定性 | 核心思想 |
|---|---|---|---|---|---|---|
| 冒泡排序 | O(n²) | O(n²) | O(n) | O(1) | 稳定 | 相邻比较交换,最大/小值冒泡到端 |
| 选择排序 | O(n²) | O(n²) | O(n²) | O(1) | 不稳定 | 每次选最小/大元素放到前面 |
| 插入排序 | O(n²) | O(n²) | O(n) | O(1) | 稳定 | 将元素插入已排序序列中的正确位置 |
| 希尔排序 | O(n log n) ~ O(n²) | O(n²) | O(n log n) | O(1) | 不稳定 | 分组插入排序(缩小增量) |
| 归并排序 | O(n log n) | O(n log n) | O(n log n) | O(n) | 稳定 | 分治法,先分后合 |
| 快速排序 | O(n log n) | O(n²) | O(n log n) | O(log n) | 不稳定 | 分治法,选取基准分区 |
| 堆排序 | O(n log n) | O(n log n) | O(n log n) | O(1) | 不稳定 | 将数组构建成堆结构进行排序 |
4. 其他非基于比较排序(了解)
1.计数排序
- 统计:遍历待排序数组,统计每个整数出现的次数,存入一个计数数组中。
- 求位置:对计数数组进行顺序求和,此时计数数组中的每个值表示小于等于该索引值的元素个数。
- 放置:根据计数数组中的位置信息,将每个元素放到输出数组中正确的位置上。
计数排序的特性总结:
- 计数排序在数据范围集中时,效率很高,但是适用范围及场景有限。
- 时间复杂度:O(MAX(N,范围))
- 空间复杂度:O(范围)
- 稳定性:稳定
2.基数排序
- 从最低位开始:先按照最低有效位进行排序。
- 依次向高位推进:然后按照次低有效位排序,依此类推,直到最高位。
- 稳定性关键:每一轮的排序必须是稳定的,这样才能保证高位排序时,低位的顺序得以保持。
- 一个形象的比喻:整理扑克牌
- 先按花色排序(稳定),再按点数排序(稳定)
- 或者先按点数排序(稳定),再按花色排序(稳定)
- 只要每次排序都是稳定的,最终就能得到完全有序的结果
基数排序的特性总结:
- 计数排序在数据范围集中时,效率很高,但是适用范围及场景有限。
- 时间复杂度:O(n * k) ,k 是最大数字的位数
- 空间复杂度:O(n + k)
- 稳定性:稳定
3.桶排序
- 分桶:将待排序元素分散到一定数量的"桶"中。
- 桶内排序:对每个非空桶中的元素进行排序(可以使用不同的排序算法)。
- 合并:按顺序将各个桶中的元素合并成一个有序序列。
- 一个形象的比喻:整理图书馆的书籍
- 先按书籍类别(文学、科学、历史等)将书分到不同的书架上(分桶)
- 然后对每个书架上的书按书名排序(桶内排序)
- 最后按类别顺序将各个书架合并起来(合并)
桶排序的特性总结:
- 计数排序在数据范围集中时,效率很高,但是适用范围及场景有限。
- 时间复杂度:O(N*(log(N/M)+1))
- 空间复杂度:O(N+ M) ,M为桶的数量
- 稳定性:稳定

















 7743
7743

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









