







GaussDB技术解读高性能——列式存储和向量化引擎
传统关系型数据库中对数据模式都是以元组(记录)的形式进行理解和存取,但是在大数量偏分析类的OLAP应用场景中,属于以列方式存储能够获得更高的执行效率,GaussDB Kernel支持行存储和列存储两种存储模型,用户可以根据应用场景,建表的时候选择行存储还是列存储表。一般情况下,如果表的字段比较多(大宽表),查询中涉及到的列不是很多,适合列存储;如果表的字段个数比较少查询大部分字段,那么选择行存储比较好,以下是行存表、列存表在存储模型上的对比。
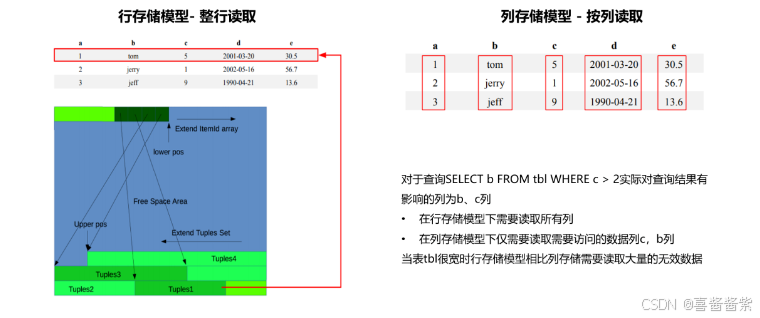
可以看到通常在大宽表、数据量比较大的场景中,查询少数特定的列、行时,行存引擎查询性能比较差。例如单表有200~800个列,经常查询访问的仅其中10个列,在这种情况下,向量化执行技术和列存储引擎可以极大地提升性能,减少存储空间。
向量化执行引擎
针对数据的列式存储,GaussDB在执行层改进了传统的执行引擎数据流遵循一次一元组的VectorBatch模式,而向量化引擎VectorEngine将这个执行器算子数据传递、计算模型改成VectorBatch模式,这种看似简单的修改却带来非常明显的性能提升。

其中的主要提升原因可以应对上面介绍的CPU架构里影响性能的几个关键因素:
(1)Batch模式的函数模型在控制流的调动下,每次都需要进行函数调用,调用次数随着数据增长而增长,而一批元组的模式则大大降低了执行节点的函数调用开销,如果我们设定Batch元组数量为1000,函数调用相对于一次一元组能减少三个数量级。
(2)VectorBatch模式在内部实现通过数组来表达,数组对于CPU的预取非常友好,能够让数组在后续的数据处理
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 232
232

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









