









AQS--->AbstractQueuedSynchronizer
作为并发包的奠基类,ReentrantLock等等诸多锁都基于AQS类进行开发
在此之前先膜拜Doug Lea祖师爷一下,祖师爷在AQS中采用了模板设计模式,定义了锁处理的主体流程,将多个类共有的方法和功能抽取出来,封装到抽象类,对于这些公有方法(模板方法)使用final修饰,需要通过子类扩张的定义成抽象(abstract)方法,由子类实现其自有特性。
JDK AQS 抽象队列同步器就是一个构建锁和同步器的模板,使用它可以构建ReentrantLock(独占型),CountDownLacth(共享型),Semaphore(共享型)等同步组件。
AQS定义的可重写的方法:
protected boolean isHeldExclusively() : 是否在独占模式下被线程占用。只有用到condition才需要去实现它
protected boolean tryAcquire(int arg) : 独占方式。尝试获取资源,成功则返回true,失败则返回false
protected boolean tryRelease(int arg) :独占方式。尝试释放资源,成功则返回true,失败则返回false
protected int tryAcquireShared(int arg) :共享方式。尝试获取资源。负数表示失败;0表示成功,但没有剩余可用资源;正数表示成功,且有剩余资源
protected boolean tryReleaseShared(int arg) :共享方式。尝试释放资源,如果释放后允许唤醒后续等待结点返回true,否则返回false
如果我们需要实现一个自定义的同步器,就只需要继承AQS,然后根据需求去重写响应的方法,比如要实现独占锁,就实现tryAcquire(),tryRelease()方法,ReentrantLock就是这样做的,同样,要实现共享锁,就需要实现tryAcquireShared(),tryReleaseShared()方法,比如Semaphore,CountDownLatch,最后在要实现的组件中调用AQS中定义的模板方法。
CLH:
CLH是根据创造出这个机制的人的名字缩写起的,以后我要研发个什么东西就以我媳妇的缩写命名,ohyeah!
提到CLH,就要一起说下MCS锁、Ticket Spinlock、SpinLock
参考:自旋锁(Ticket,CLH,MCS)_zhouweiIT的博客-优快云博客_c语言ticket锁的自然语言解释
自旋锁(Spin lock):
是指当一个线程尝试获取某个锁时,如果该锁已被其他线程占用,就一直循环检测锁是否被释放,而不是进入线程挂起或睡眠状态。由于自旋锁只不进行线程状态的改变,所以当线程竞争不激烈时,它的响应速度极快。自旋锁适用于锁保护的临界区很小的情况,如果线程之间竞争激烈,上下文切换将耗费大量资源,性能会明显下降。
还有个问题是,多线程同时竞争锁时,并不能保证其公平性,因为是谁抢到算谁的。
Ticket Spinlock:
类似于现实中的排队叫号,锁拥有一个服务号,表示正在服务的线程,还有一个排队号;每个线程尝试获取锁之前先拿一个排队号,然后不断轮询锁的当前服务号是否是自己的排队号,如果是,则表示自己拥有了锁,不是则继续轮询。
虽然解决了公平性的问题,但是多处理器系统上,每个进程/线程占用的处理器都在读写同一个变量serviceNum ,每次读写操作都必须在多个处理器缓存之间进行缓存同步,这会导致繁重的系统总线和内存的流量,大大降低系统整体的性能。
CLH:
CLH锁是一种基于链表的可扩展、高性能、公平的自旋锁,申请线程只在本地变量上自旋,它不断轮询前驱的状态,如果发现前驱释放了锁就结束自旋。
CLH在SMP系统结构下该法是非常有效的。但在NUMA系统结构下,每个线程有自己的内存,如果前趋结点的内存位置比较远,自旋判断前趋结点的locked域,性能将大打折扣,一种解决NUMA系统结构的思路是MCS队列锁。

MCS:
MSC与CLH最大的不同并不是链表是显示还是隐式,而是线程自旋的规则不同:CLH是在前趋结点的locked域上自旋等待,而MSC是在自己的结点的locked域上自旋等待。正因为如此,它解决了CLH在NUMA系统架构中获取locked域状态内存过远的问题。

正如上边提到了两个玩意,SMP和NUMA,这是什么呢,他们叫服务器体系,一般来讲有三种SMP, NUMA, MPP
参考 服务器体系(SMP, NUMA, MPP)与共享存储器架构(UMA和NUMA)_CHENG Jian的博客-优快云博客
SMP、NUMA、MPP体系结构介绍 - victoryubo - 博客园
1. SMP(Symmetric Multi-Processor)
SMP (Symmetric Multi Processing),对称多处理系统内有许多紧耦合多处理器,在这样的系统中,所有的CPU共享全部资源,如总线,内存和I/O系统等,操作系统或管理数据库的复本只有一个,这种系统有一个最大的特点就是共享所有资源。多个CPU之间没有区别,平等地访问内存、外设、一个操作系统。操作系统管理着一个队列,每个处理器依次处理队列中的进程。如果两个处理器同时请求访问一个资源(例如同一段内存地址),由硬件、软件的锁机制去解决资源争用问题。Access to RAM is serialized; this and cache coherency issues causes performance to lag slightly behind the number of additional processors in the system.

所谓对称多处理器结构,是指服务器中多个 CPU 对称工作,无主次或从属关系。各 CPU 共享相同的物理内存,每个 CPU 访问内存中的任何地址所需时间是相同的,因此 SMP 也被称为一致存储器访问结构 (UMA : Uniform Memory Access) 。对 SMP 服务器进行扩展的方式包括增加内存、使用更快的 CPU 、增加 CPU 、扩充 I/O( 槽口数与总线数 ) 以及添加更多的外部设备 ( 通常是磁盘存储 ) 。
SMP 服务器的主要特征是共享,系统中所有资源 (CPU 、内存、 I/O 等 ) 都是共享的。也正是由于这种特征,导致了 SMP 服务器的主要问题,那就是它的扩展能力非常有限。对于 SMP 服务器而言,每一个共享的环节都可能造成 SMP 服务器扩展时的瓶颈,而最受限制的则是内存。由于每个 CPU 必须通过相同的内存总线访问相同的内存资源,因此随着 CPU 数量的增加,内存访问冲突将迅速增加,最终会造成 CPU 资源的浪费,使 CPU 性能的有效性大大降低。实验证明, SMP 服务器 CPU 利用率最好的情况是 2 至 4 个 CPU 。
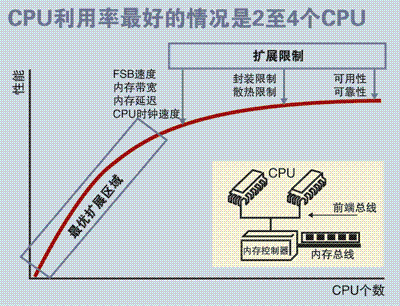
图 1.SMP 服务器 CPU 利用率状态
2. NUMA(Non-Uniform Memory Access)
由于 SMP 在扩展能力上的限制,人们开始探究如何进行有效地扩展从而构建大型系统的技术, NUMA 就是这种努力下的结果之一。利用 NUMA 技术,可以把几十个 CPU( 甚至上百个 CPU) 组合在一个服务器内。其 CPU 模块结构如图 2 所示:
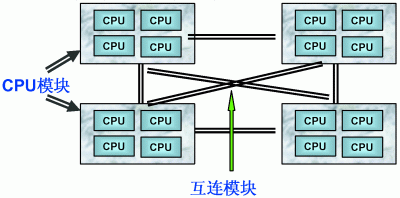
图 2.NUMA 服务器 CPU 模块结构
NUMA 服务器的基本特征是具有多个 CPU 模块,每个 CPU 模块由多个 CPU( 如 4 个 ) 组成,并且具有独立的本地内存、 I/O 槽口等。由于其节点之间可以通过互联模块 ( 如称为 Crossbar Switch) 进行连接和信息交互,因此每个 CPU 可以访问整个系统的内存 ( 这是 NUMA 系统与 MPP 系统的重要差别 ) 。显然,访问本地内存的速度将远远高于访问远地内存 ( 系统内其它节点的内存 ) 的速度,这也是非一致存储访问 NUMA 的由来。由于这个特点,为了更好地发挥系统性能,开发应用程序时需要尽量减少不同 CPU 模块之间的信息交互。
利用 NUMA 技术,可以较好地解决原来 SMP 系统的扩展问题,在一个物理服务器内可以支持上百个 CPU 。比较典型的 NUMA 服务器的例子包括 HP 的 Superdome 、 SUN15K 、 IBMp690 等。
但 NUMA 技术同样有一定缺陷,由于访问远地内存的延时远远超过本地内存,因此当 CPU 数量增加时,系统性能无法线性增加。如 HP 公司发布 Superdome 服务器时,曾公布了它与 HP 其它 UNIX 服务器的相对性能值,结果发现, 64 路 CPU 的 Superdome (NUMA 结构 ) 的相对性能值是 20 ,而 8 路 N4000( 共享的 SMP 结构 ) 的相对性能值是 6.3 。从这个结果可以看到, 8 倍数量的 CPU 换来的只是 3 倍性能的提升。
3. MPP(Massive Parallel Processing)
和 NUMA 不同, MPP 提供了另外一种进行系统扩展的方式,它由多个 SMP 服务器通过一定的节点互联网络进行连接,协同工作,完成相同的任务,从用户的角度来看是一个服务器系统。其基本特征是由多个 SMP 服务器 ( 每个 SMP 服务器称节点 ) 通过节点互联网络连接而成,每个节点只访问自己的本地资源 ( 内存、存储等 ) ,是一种完全无共享 (Share Nothing) 结构,因而扩展能力最好,理论上其扩展无限制,目前的技术可实现 512 个节点互联,数千个 CPU 。目前业界对节点互联网络暂无标准,如 NCR 的 Bynet , IBM 的 SPSwitch ,它们都采用了不同的内部实现机制。但节点互联网仅供 MPP 服务器内部使用,对用户而言是透明的。
在 MPP 系统中,每个 SMP 节点也可以运行自己的操作系统、数据库等。但和 NUMA 不同的是,它不存在异地内存访问的问题。换言之,每个节点内的 CPU 不能访问另一个节点的内存。节点之间的信息交互是通过节点互联网络实现的,这个过程一般称为数据重分配 (Data Redistribution) 。
但是 MPP 服务器需要一种复杂的机制来调度和平衡各个节点的负载和并行处理过程。目前一些基于 MPP 技术的服务器往往通过系统级软件 ( 如数据库 ) 来屏蔽这种复杂性。举例来说, NCR 的 Teradata 就是基于 MPP 技术的一个关系数据库软件,基于此数据库来开发应用时,不管后台服务器由多少个节点组成,开发人员所面对的都是同一个数据库系统,而不需要考虑如何调度其中某几个节点的负载。
MPP (Massively Parallel Processing),大规模并行处理系统,这样的系统是由许多松耦合的处理单元组成的,要注意的是这里指的是处理单元而不是处理器。每个单元内的CPU都有自己私有的资源,如总线,内存,硬盘等。在每个单元内都有操作系统和管理数据库的实例复本。这种结构最大的特点在于不共享资源。

AQS里的CLH其实是个变种,有以下几点变化:
1.CLH里在未拿到锁时,不再是不停地自旋,而是经过几次(具体的次数是有限制的,是AQS代码一系列判断条件限制的)判断之后,还未拿到就会被park掉--阻塞
2.CLH里比较的不再是前一个线程的是否被lock的状态值,而是 p == head作为判断条件,看自己的节点的前一个节点是不是head标记的,如果是,证明自己别歇着了该起来抢锁了tryAcquire(arg)
final boolean acquireQueued(final Node node, int arg) {
boolean failed = true;
try {
boolean interrupted = false;
for (;;) {
final Node p = node.predecessor();
if (p == head && tryAcquire(arg)) {
setHead(node);
p.next = null; // help GC
failed = false;
return interrupted;
}
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
interrupted = true;
}
} finally {
if (failed)
cancelAcquire(node);
}
}3.根据代码来看
AQS的这个方法作为lock时拿锁操作的入口,lock()里调用acquire()
public final void acquire(int arg) {
if (!tryAcquire(arg) &&
acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
selfInterrupt();
}tryAcquire自己实现
如果拿到锁,就结束;
如果没拿到会走acquireQueued(addWaiter(Node.EXCLUSIVE), arg)这个方法,这里要先看addWaiter(Node.EXCLUSIVE)
private Node addWaiter(Node mode) {
//创建一个要放入CLH队列的节点,注意这种构造方法生成的Node,此时,里面有个属性waitStatus是默认为0的
Node node = new Node(Thread.currentThread(), mode);
// Try the fast path of enq; backup to full enq on failure
Node pred = tail;
if (pred != null) {
node.prev = pred;
if (compareAndSetTail(pred, node)) {
pred.next = node;
return node;
}
}
enq(node);
return node;
}这里Node可能要入CLH队列里等待(有可能park,有可能继续尝试获取锁)
创建好Node节点后,把tail尾节点的引用赋值给pred局部变量,
如果tail不是null说明之前有排队的,就把tail搞成指向新来的这个;
如果tail是null表示之前没有过排队的,或者说更新tail指向时出现争抢,就需要走到后边的enq(node)
/**
* Inserts node into queue, initializing if necessary. See picture above.
* @param node the node to insert
* @return node's predecessor
*/
private Node enq(final Node node) {
for (;;) {
Node t = tail;
if (t == null) { // Must initialize
if (compareAndSetHead(new Node()))
tail = head;
} else {
node.prev = t;
if (compareAndSetTail(t, node)) {
t.next = node;
return t;
}
}
}
}正如前边说的enq是在两种情况下才进入的,这里用for去自旋,首先把tail的引用赋值给局部变量t,判断了下是哪种情况进来的,如果是tail为null进来的,就
compareAndSetHead(new Node())
创建一个啥也没有的假节点作为head和tail的引用,都指向了他,CAS操作就不多解释了,并发啥的我也不想多说,自己看吧,毕竟不是讲源码;重新自旋
如果是tail不为null进来的,那就再尝试把这小子挂在这个虚拟的队列最后(其实感觉这种实现像链表。。。只不过只能操作链表的首尾)
干完了就退回到
acquire()
public final void acquire(int arg) {
if (!tryAcquire(arg) &&
acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
selfInterrupt();
}这时候就搞
/**
* Acquires in exclusive uninterruptible mode for thread already in
* queue. Used by condition wait methods as well as acquire.
*
* @param node the node
* @param arg the acquire argument
* @return {@code true} if interrupted while waiting
*/
final boolean acquireQueued(final Node node, int arg) {
boolean failed = true;
try {
boolean interrupted = false;
for (;;) {
final Node p = node.predecessor();
if (p == head && tryAcquire(arg)) {
setHead(node);
p.next = null; // help GC
failed = false;
return interrupted;
}
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
interrupted = true;
}
} finally {
if (failed)
cancelAcquire(node);
}
}这个方法,这里面才会涉及到了我们之前提到的那个Node里的 volatile int waitStatus;
其实也没那么复杂,这里就是拿你放入Node链里最后返回了那个Node,传到了这个方法里,然后final Node p = node.predecessor();获取前置节点,发现前边的要是head的指向,证明,前边那小子干活呢,马上轮到你了,就别休息了看看能不能拿到锁把,
拿到了就正常处理;
拿不到锁,或者说传进来的Node的前置节点不是head,那就往下走,shouldParkAfterFailedAcquire(p, node) && parkAndCheckInterrupt()
/**
* Checks and updates status for a node that failed to acquire.
* Returns true if thread should block. This is the main signal
* control in all acquire loops. Requires that pred == node.prev.
*
* @param pred node's predecessor holding status
* @param node the node
* @return {@code true} if thread should block
*/
private static boolean shouldParkAfterFailedAcquire(Node pred, Node node) {
int ws = pred.waitStatus;
if (ws == Node.SIGNAL)
/*
* This node has already set status asking a release
* to signal it, so it can safely park.
*/
return true;
if (ws > 0) {
/*
* Predecessor was cancelled. Skip over predecessors and
* indicate retry.
*/
do {
node.prev = pred = pred.prev;
} while (pred.waitStatus > 0);
pred.next = node;
} else {
/*
* waitStatus must be 0 or PROPAGATE. Indicate that we
* need a signal, but don't park yet. Caller will need to
* retry to make sure it cannot acquire before parking.
*/
compareAndSetWaitStatus(pred, ws, Node.SIGNAL);
}
return false;
}这里才真正用到了waitStatus
如果前置节点waitStatus是SIGNAL(-1)表示你可以滚蛋了,出去看看别的条件没有就再尝试去拿锁;
如果前置节点waitStatus>0,那就是CANCELLED 被,代表你被取消了,那就得再往前找,找到非0或者小于0的位置,然后退出去再进来就看是 == -1 还是 <0&!=-1。
如果前置节点waitStatus<0(这里不可能是-1),这种情况下就尝试把前置节点置为-1,然后也可以退出去,自旋再进来的时候,就可以舒舒服服park歇着了
/** waitStatus value to indicate thread has cancelled */
static final int CANCELLED = 1;
/** waitStatus value to indicate successor's thread needs unparking */
static final int SIGNAL = -1;
/** waitStatus value to indicate thread is waiting on condition */
static final int CONDITION = -2;
/**
* waitStatus value to indicate the next acquireShared should
* unconditionally propagate
*/
static final int PROPAGATE = -3;所以如果第一个来排队的Node是waitStatus是0,但是第二个来的会把前边的0设置为-1,后边进来的一样会把前边的状态改变,
综上,head节点在第一个没拿到锁的线程进入队列的时候初始化,只有此刻,head指向了一个啥都没有new出来的虚构节点Node,后边随着代码进行,head都指向当前持有锁的线程。当然了作为判断条件有避免重复释放锁的问题。

















 1180
1180

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









