




 本文详细解释了卡尔曼滤波中的关键概念,包括方差、协方差和相关系数,阐述了它们在衡量随机变量间关系和预测中的作用,以及如何通过公式理解这些统计量。
本文详细解释了卡尔曼滤波中的关键概念,包括方差、协方差和相关系数,阐述了它们在衡量随机变量间关系和预测中的作用,以及如何通过公式理解这些统计量。
背景
卡尔曼滤波预测中用到协方差,查了相关资料,以此记录。

协方差
协方差(Covariance)在概率论和统计学中用于衡量两个变量的总体误差。而方差是协方差的一种特殊情况,即当两个变量是相同的情况。
协方差表示的是两个变量的总体的误差,这与只表示一个变量误差的方差不同。如果两个变量的变化趋势一致,也就是说如果其中一个大于自身的期望值,另外一个也大于自身的期望值,那么两个变量之间的协方差就是正值。如果两个变量的变化趋势相反,即其中一个大于自身的期望值,另外一个却小于自身的期望值,那么两个变量之间的协方差就是负值。
协方差公式

一、 方差
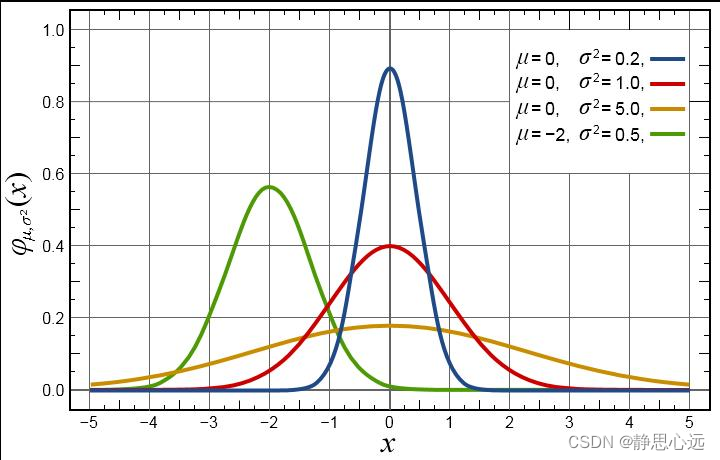
方差是各个数据与平均数之差的平方的平均数。在概率论和数理统计中,方差(英文Variance)用来度量随机变量和其数学期望(即均值)之间的偏离程度。在许多实际问题中,研究随机变量和均值之间的偏离程度有着很重要的意义。
二、标准差
方差开根号。
三、协方差
在概率论和统计学中,协方差用于衡量两个变量的总体误差。而方差是协方差的一种特殊情况,即当两个变量是相同的情况。
可以通俗的理解为:两个变量在变化过程中是否同向变化?还是反方向变化?同向或反向程度如何?
- 你变大,同时我也变大,说明两个变量是同向变化的,这是协方差就是正的。
- 你变大,同时我变小,说明两个变量是反向变化的,这时协方差就是负的。
- 如果我是自然人,而你是太阳,那么两者没有相关关系,这时协方差是0。
从数值来看,协方差的数值越大,两个变量同向程度也就越大,反之亦然。
可以看出来,协方差代表了两个变量之间的是否同时偏离均值,和偏离的方向是相同还是相反。
公式:如果有X,Y两个变量,每个时刻的“X值与其均值之差”乘以“Y值与其均值之差”得到一个乘积,再对这每时刻的乘积求和并求出均值,即为协方差。
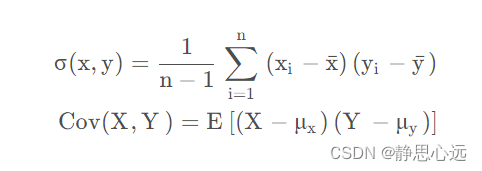
中间省略若干,数字基础太差。。。
- 卡尔曼滤波(Kalman Filtering)——(2)基础知识(方差、协方差与相关系数)
四、方差,标准差与协方差之间的联系与区别 - 1.方差和标准差都是对一组(一维)数据进行统计的,反映的是一维数组的离散程度;而协方差是对2组数据进行统计的,反映的是2组数据之间的相关性。
- 2.标准差和均值的量纲(单位)是一致的,在描述一个波动范围时标准差比方差更方便。比如一个班男生的平均身高是170cm,标准差是10cm,那么方差就是10cm^2。可以进行的比较简便的描述是本班男生身高分布是170±10cm,方差就无法做到这点。
- 3.方差可以看成是协方差的一种特殊情况,即2组数据完全相同。
协方差的计算公式为:
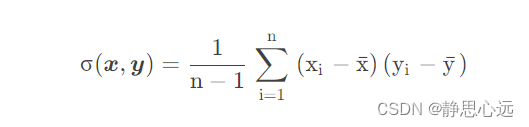

4.协方差只表示线性相关的方向,取值正无穷到负无穷
四、相关系数
相关度的大小了:相关系数
协方差的相关系数,不仅表示线性相关的方向,还表示线性相关的程度,取值[-1,1]。也就是说,相关系数为正值,说明一个变量变大另一个变量也变大;取负值说明一个变量变大另一个变量变小,取0说明两个变量没有相关关系。同时,相关系数的绝对值越接近1,线性关系越显著。
相关系数:
1、也可以反映两个变量变化时是同向还是反向,如果同向变化就为正,反向变化就为负。
2、由于它是标准化后的协方差,因此更重要的特性来了:它消除了两个变量变化幅度的影响,而只是单纯反应两个变量每单位变化时的相似程度。
计算公式为:就是用X、Y的协方差除以X的标准差乘以Y的标准差。
在概率论中,两个随机变量 X 与 Y 之间相互关系,大致有下列3种情况:

当 X, Y 的联合分布像左图那样时,我们可以看出,大致上有: X 越大 Y 也越大, X 越小 Y 也越小,这种情况,我们称为 “正相关”。
当X, Y 的联合分布像中图那样时,我们可以看出,大致上有:X 越大Y 反而越小,X 越小 Y 反而越大,这种情况,我们称为 “负相关”。
当X, Y 的联合分布像右图那样时,我们可以看出:既不是X 越大Y 也越大,也不是 X 越大 Y 反而越小,这种情况我们称为 “ 不相关”。
怎样将这3种相关情况,用一个简单的数字表达出来呢?
- 在图中的区域(1)中,有 X>EX ,Y-EY>0 ,所以(X-EX)(Y-EY)>0;
- 在图中的区域(2)中,有 X<EX ,Y-EY>0 ,所以(X-EX)(Y-EY)<0;
- 在图中的区域(3)中,有 X<EX ,Y-EY<0 ,所以(X-EX)(Y-EY)>0;
- 在图中的区域(4)中,有 X>EX ,Y-EY<0 ,所以(X-EX)(Y-EY)<0。
当X 与Y 正相关时,它们的分布大部分在区域(1)和(3)中,小部分在区域(2)和(4)中,所以平均来说,有E(X-EX)(Y-EY)>0 。
当 X与 Y负相关时,它们的分布大部分在区域(2)和(4)中,小部分在区域(1)和(3)中,所以平均来说,有(X-EX)(Y-EY)<0 。
当 X与 Y不相关时,它们在区域(1)和(3)中的分布,与在区域(2)和(4)中的分布几乎一样多,所以平均来说,有(X-EX)(Y-EY)=0 。
所以,我们可以定义一个表示X, Y 相互关系的数字特征,也就是协方差。
cov(X,Y)=E(X−EX)(Y−EY)
- 当 cov(X, Y)>0时,表明 X与Y 正相关;
- 当 cov(X, Y)<0时,表明X与Y负相关;
- 当 cov(X, Y)=0时,表明X与Y不相关。
这就是协方差的意义。
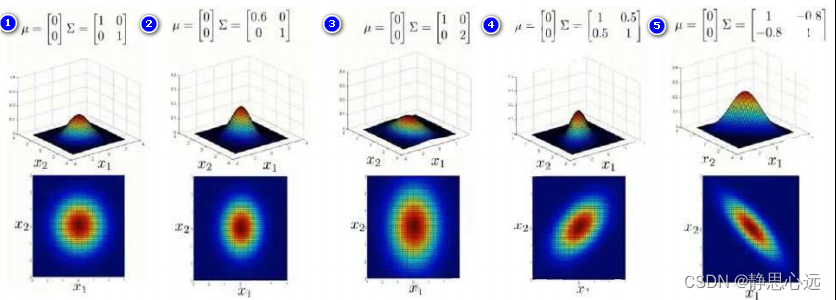
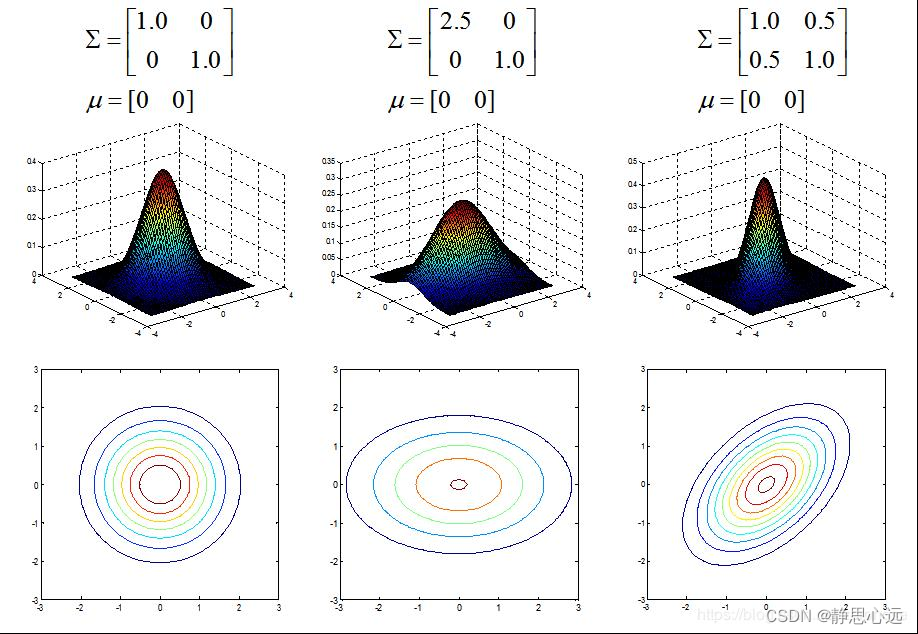
协方差矩阵的主对角线就是方差,反对角线上的就是两个变量间的协方差。
就上面的二元高斯分布而言,协方差越大,图像越扁,也就是说两个维度之间越有联系。
特别提示
上面的公式和数据并非我推导或者验证,仅做参考。


















 7万+
7万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









