









 本文介绍如何在MacOS/Linux环境下,使用Java+Eclipse+Maven开发SparkSQL应用程序,重点讲解SparkSQL与Hive的集成,包括所需依赖库、配置文件的添加,以及在Eclipse中进行开发调试的方法。
本文介绍如何在MacOS/Linux环境下,使用Java+Eclipse+Maven开发SparkSQL应用程序,重点讲解SparkSQL与Hive的集成,包括所需依赖库、配置文件的添加,以及在Eclipse中进行开发调试的方法。
操作系统:Mac OS/Linux
开发环境:java + eclipse + maven
spark SQL是spark的一个模块,可以用来操作结构化数据(如JSON、Hive、Parquet)和半结构化数据。
1、DataFrame
spark SQL使用的最核心的数据类型是DataFrame,DataFrame结构如下图
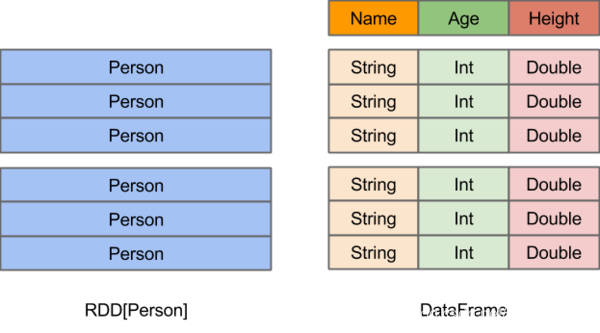
在DataFrame上支持直接运行SQL查询。可以从外部数据源创建一个DataFrame,也可以从数据库查询结果或普通RDD中创建。
2、spark SQL支持范围
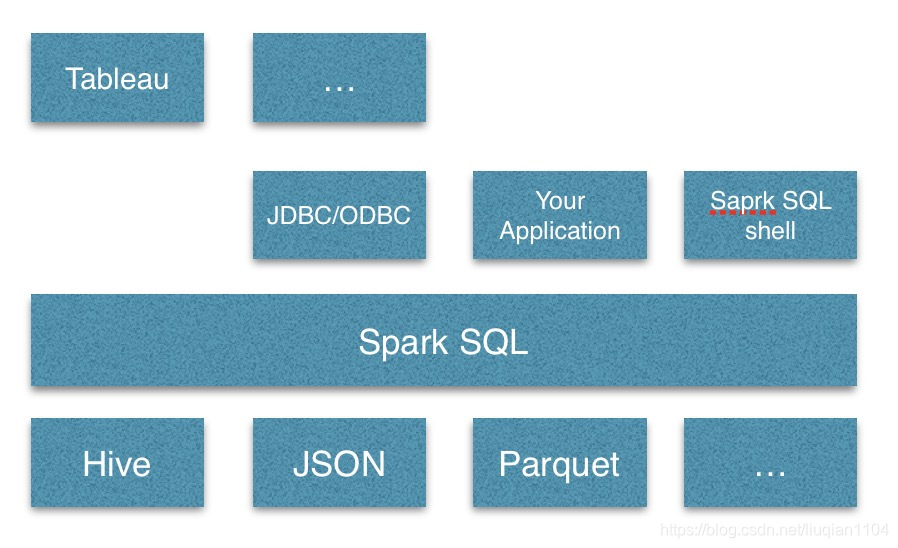
在spark里访问Hive可以直接连,不需要JDBC,JDBC主要用来连接mysql这种传统关系型数据库,网上很多资料用JDBC连接的Hive,容易混淆。
3、连接远程服务器上已部署好的Hive
(1)在maven项目里添加spark SQL所需的库:
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.2.0</version>
<scope>provided</scope>
</dependency>
<!-- spark-hive -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.11</artifactId>
<version>2.2.0</version>
<scope>provided</scope>
</dependency>
</dependencies>
spark-hive的版本是指的spark的,而不是hive的版本。
(2)复制集群的配置文件
网上很多资料说,若要把spark SQL连接到一个部署好的Hive上,必须把服务器上的hive-site.xml复制到spark的配置文件目录中。我没这样做,而是在eclipse的maven工程里直接添加的,经测试可行,方法如下:
将已经搭好Hadoop、Hive、Spark环境的集群上的hive-site.xml、core-size.xml、hdfs-site.xml复制一份,放到maven项目的资源文件夹里(src/main/resources),必须,否则找不到服务器上的hive。
注意:
a)如果没有安装hive,spark SQL也能用,它会在当前的工作目录中创建出自己的hive元数据仓库,叫做metastore_db。如果在命令行执行spark-shell,再执行spark.sql("show databases").show(),能看到有个叫default的默认库,可以通过spark.sql执行任何标准sql语句,例如创建表,这个表会放在你默认的文件系统中,如果你的classpath中有配好的hdfs-site.xml,默认的文件系统就是HDFS,否则就是本地文件系统。
b)集群间互相访问一般不使用ip,而是主机名,所以要在本地的电脑上修改/etc/host文件,添加集群中各个节点的hostname和ip的映射。
(3)使用spark SQL
在spark的早期版本中,我们需要使用不同的context来访问不同类型的数据源。Spark 2.0之后引入了新的概念SparkSession,为用户提供了统一的切入点。
先来看下各种不同的context用处:
SparkContext:它是spark的主要切入点,通过sparkcontext来创建和操作RDD。
StreamingContext:针对Streming使用。
SQLContext:针对sql使用,如mysql。
HiveContext:对于Hive使用。
随着DataSet和DataFrame的API逐渐成为标准的API,就需要为他们建立接入点。所以在spark2.0中,引入SparkSession作为DataSet和DataFrame API的切入点,SparkSession封装了SparkConf、SparkContext和SQLContext。为了向后兼容,SQLContext和HiveContext也被保存下来。
SparkSession:实质上是SQLContext和HiveContext的组合(未来可能还会加上StreamingContext),所以在SQLContext和HiveContext上可用的API在SparkSession上同样是可以使用的。SparkSession内部封装了sparkContext,所以计算实际上是由sparkContext完成的。
代码:
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
public class TestHive {
public static void main(String[] args) {
SparkSession ss = SparkSession.builder()
.appName("Java Spark Hive Example")
.master("local")
.config("hive.execution.engine", "mr")
.enableHiveSupport()//如果需要访问hive,则需要添加这一个
.getOrCreate();
Dataset<Row> rs = ss.sql("select * from hive.ds_shop");
rs.show();
ss.stop();
}
}
注意:
a)hive.execution.engine参数可以设置Hive使用的计算引擎,支持三种,mr是mapreduce计算引擎、tez是tez 计算引擎、spark是spark计算引擎。
b)在eclipse里开发调试时设置master("local"),当打包用spark-submit提交到服务器上时,需要注释掉这句,在提交任务时设置master为yarn主节点。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









