









 本文详细介绍了如何通过SSH登录到Hadoop集群的Master节点,并在本地配置hosts文件以实现节点间通过主机名访问。此外,还演示了如何使用Hadoop上传文件到HDFS,以及在Spark shell中使用Scala进行WordCount的全过程。
本文详细介绍了如何通过SSH登录到Hadoop集群的Master节点,并在本地配置hosts文件以实现节点间通过主机名访问。此外,还演示了如何使用Hadoop上传文件到HDFS,以及在Spark shell中使用Scala进行WordCount的全过程。
1、ssh登录到master节点
ssh -p端口 用户名@ip,例如:ssh -p22 root@192.168.0.50
2、修改本地host文件
hadoop中访问各个节点一般不直接只用ip,而是用主机名,所以复制master节点上已经配置好的host文件到本地
执行 cat /etc/hosts,将内容复制到本机的host文件里
3、登录hadoop,上传一个文件到HDFS,用于wordCount
hadoop fs -ls / 查看hadoop根目录下所有文件
hadoop fs -put hello.txt /hello2.txt 把本地hello.txt文件上传到hdfs根目录下,重命名为hello2.txt
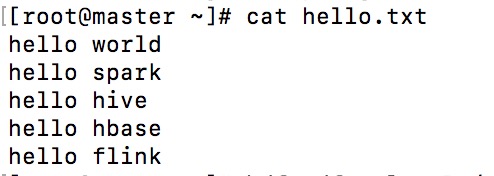
hello.txt文件的内容如下
4、进入Spark-shell交互式命令行
spark-shell
5、用scala写wordCount
scala> val lines=sc.textFile("hdfs://master.hadoop.frilab/hello2.txt") //master.hadoop.frilab为主机名
scala> s.count
scala> val wordCount = lines.flatMap(row=>row.split(" ")).map(word=>(word,1)).reduceByKey{case(x,y)=>x+y}
scala> wordCount.collect
执行结果如下:

将结果保存到hdfs的话用:
counts.saveAsTextFile("hdfs://master.hadoop.frilab/wordCountResult.txt")

















 1150
1150

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









