






RabbitMQ作为一个开源的消息中间件,在大数据量服务中起到关键作用,它可以将耗时的操作转为异步执行,来提升系统的吞吐量,在高峰时段,RabbitMQ可以缓存大量的消息,从而避免系统崩溃,并在低峰时段处理这些消息,提高了系统的稳定性。
rabbitmq虽然可以缓存消息,但是也不能无限制、大量的缓存消息而不进行消费,否则会导致mq内存耗尽,服务down机,因此一个高效、稳定的消费者程序对于服务稳定显得尤为重要。

该消费者设计的总思路如下:
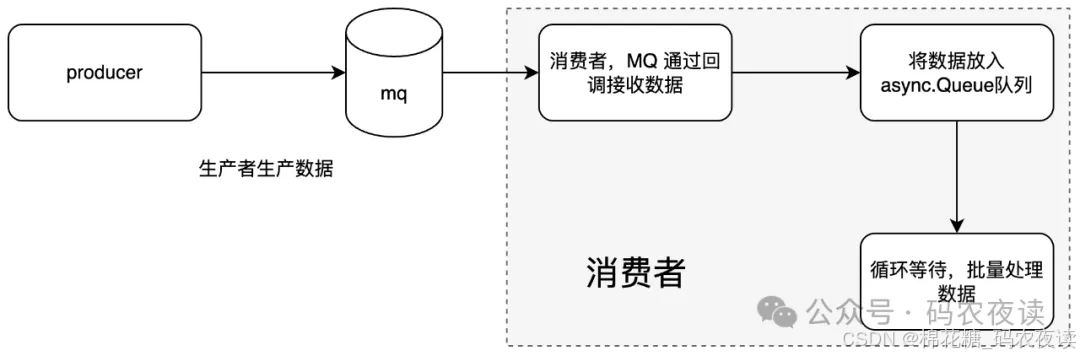
重点要说明的是,消息接收与消息处理要分开,消息接收只做接收,消息处理要批量进行。
1、代码实现
下面就以一个具体的实例来实现此消费者的设计,首先是写了一个类,实现基本对rabbitmq的操作(这个类可以拿去直接使用):
class DwRabbitMQ:
def __init__(self, url, exchange, queue_name):
self.async_queue = asyncio.Queue()
self.url = url
self.exchange = exchange
self.queue_name = queue_name
self.connection = None
self.channel = None
self.queue = None
async def connect(self):
try:
self.connection = await aio_pika.connect_robust(
self.url
)
self.channel = await self.connection.channel()
self.exchange = await self.channel.declare_exchange(name=self.exchange, type='fanout')
self.queue = await self.channel.declare_queue(name=self.queue_name, durable=True)
except Exception as e:
print(e)
async def queue_bind_exchange(self):
try:
await self.queue.bind(exchange=self.exchange)
except Exception as e:
print(e)
async def set_callback(self, callback):
try:
await self.queue.consume(callback)
except Exception as e:
print(e)
async def callback(self, message: aio_pika.IncomingMessage):
try:
# print(f"Consumer 1 received: {message.body.decode()}")
self.async_queue.put_nowait((message,message.body.decode()))
except Exception:
print(f" [!] Rejected: {message.body.decode()}")
async def is_connected(self):
return self.connection.is_closed
def get_msg(self):
return self.async_queue.get_nowait()在上面代码中,重点看callback这个回调函数,我们发现,这个函数的实现逻辑非常简单,就是把消息放入到队列中,没有任何其他业务逻辑:
async def set_callback(self, callback):
try:
await self.queue.consume(callback)
except Exception as e:
print(e)那消息的处理在哪呢?如开始所说,消息接收和消息处理分开,消息处理是业务逻辑,必定会耦合业务需求,每个需求都会各不相同,因此分开是正确的选择。
那我们接下来看一下如何利用上面的类实现对消息的处理:
async def main():
buffer = []
batch_size = 10
last_time = time.time()
url = "amqp://guest:guest@localhost:5672/"
dwmq = DwRabbitMQ(url, "exchange_fan", "dw_clip_insert")
await dwmq.connect()
await dwmq.queue_bind_exchange()
await dwmq.set_callback(dwmq.callback)
print(" [*] Waiting for messages. To exit press CTRL+C")
while True:
# if await dwmq.is_connected():
# try:
# print("reconnecting...")
# dwmq = DwRabbitMQ(url, "exchange_fan", "dw_clip_insert")
# await dwmq.connect()
# await dwmq.set_callback(dwmq.callback)
# except Exception as e:
# print(e,",retry to connect")
# await asyncio.sleep(1)
# continue
try:
msg = dwmq.get_msg()
except asyncio.QueueEmpty:
await asyncio.sleep(1)
msg = None
if msg is not None:
buffer.append(msg)
if len(buffer) < batch_size and time.time() - last_time < 60:
continue
last_time = time.time()
print("batch size : {},real size : {}, begin to process".format(batch_size,len(buffer)))
# 根据实际需求,批量
for msg in buffer:
try:
await msg[0].ack()
except Exception as e:
print(e)
print(msg[1])
buffer = []在消费处理中需要说明的有两点:
-
对消息进行打包处理
-
如果消息不够设置的『包』,也要有处理策略,这里是按时间处理的,如果等待超过一定时间没有凑够这个『包』,那么就有多少算多少,先处理了。
代码实现在这里:
try:
msg = dwmq.get_msg()
except asyncio.QueueEmpty:
await asyncio.sleep(1)
msg = None
if msg is not None:
buffer.append(msg)
if len(buffer) < batch_size and time.time() - last_time < 60:
continue2、代码的健壮性考虑
一般情况下,消费者都会设计成后台任务常驻,来消费队列中的消息,假如rabbitmq因某种异常导致了重启,后台任务与mq的连接就会失效,因此任务在运行过程中需要考虑mq异常断开的情况,mq恢复正常时,后台任务具有重连的能力,来保证消费的恢复,因此我们需要在代码中增加以下逻辑:
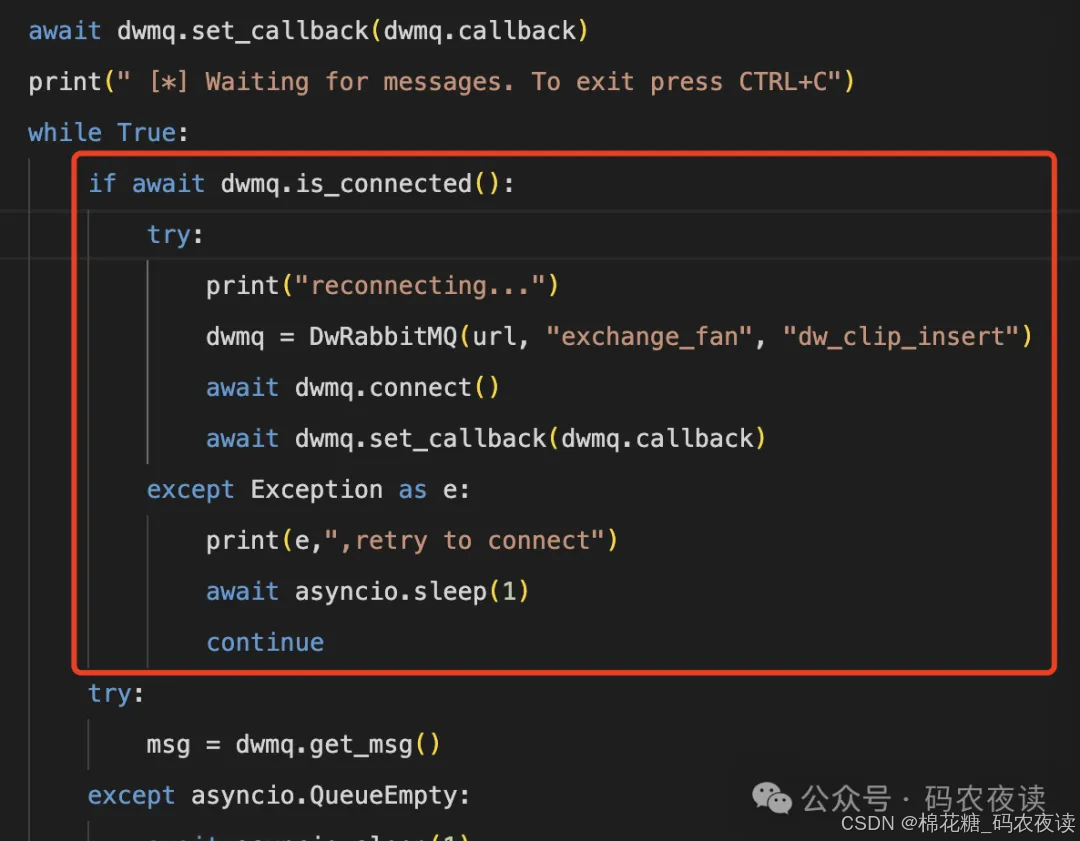
在循环消费的过程中,我们增加了对连接状态的判断,如果连接已断开,则启动重连。
在实际测试过程中,当关闭mq时,没有这部分代码,mq也会自动重连,这应该是【aio_pika】包内部实现了重连的机制。
但是为了保险起见,建议还是增加这部分代码。
以上就是这个异步消费者的全部了,这个思路以及代码可以直接拿来上线使用,只需要按照自己的业务逻辑进行适配就可以了,全部代码在这里:
https://github.com/liupengh3c/career/tree/main/rabbitmq/async
期待小伙伴们点个关注,聊聊技术,聊聊跑步,聊聊家常~~~~~~。
往期推荐:
Python web框架sanic+tortoise服务框架搭建(MVP版本)
命令行参数的艺术:Python、Golang、C++技术实现
借助tritonserver完成gpt2模型的本地私有化部署
【续】开发triton客户端,访问clip-vit-large-patch14模型抽取图片特征。
NVIDIA tritonserver实现CLIP-ViT模型工程化:轻松获取图片特征(by grpc or http)
吭哧一天才搞定:elasticsearch向量检索需要的数据集以及768维向量生成
elasticsearch查询语言DSL构建包使用及实现原理(golang)
Elasticsearch写入、读取、更新、删除以及批量操作(golang)
tritonserver学习之四:tritonserver运行流程

















 2512
2512

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









