




 博客探讨了误差的来源,包括Bias和Variance的概念,解释了如何判断过拟合和欠拟合,并介绍了梯度下降法,如L损失函数、学习率调整和自适应学习率策略。此外,还提到了特征缩放对随机梯度下降模型收敛速度的影响。
博客探讨了误差的来源,包括Bias和Variance的概念,解释了如何判断过拟合和欠拟合,并介绍了梯度下降法,如L损失函数、学习率调整和自适应学习率策略。此外,还提到了特征缩放对随机梯度下降模型收敛速度的影响。
误差的来源
Bias + Variance
模型最理想状态是没有bias,而且Variance 很小
Variance 方差
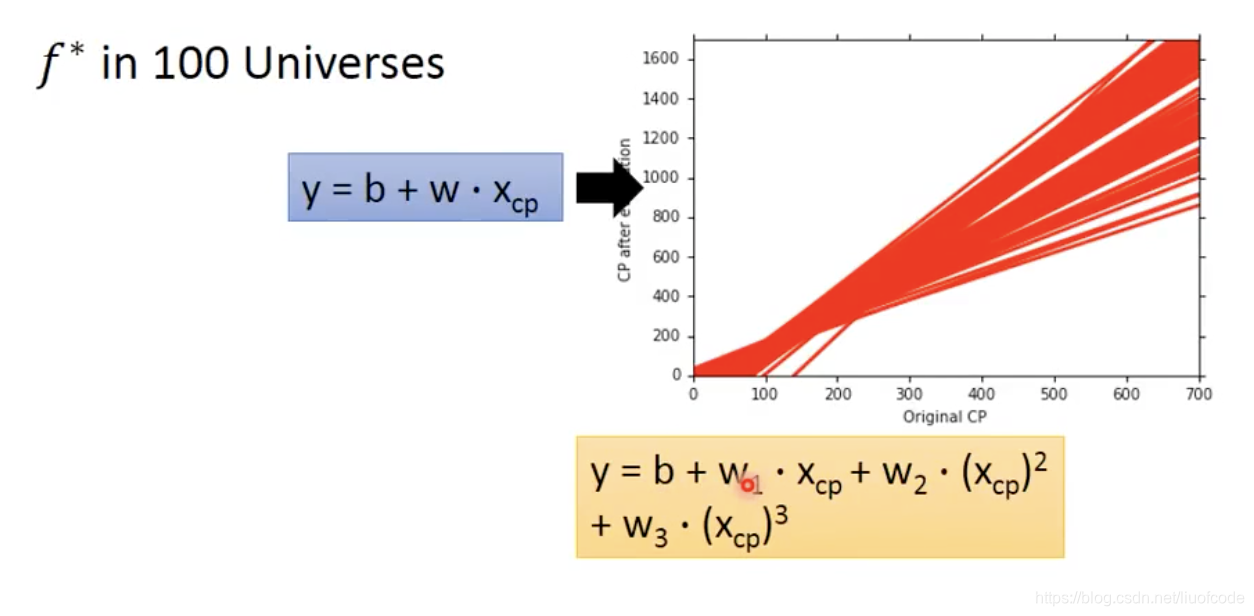
简单的模型的variance 就偏小。
模型越简单,特征越少,所以受数据的方法影响越小
Bias
数据集的均值和测试集的均值的欧式距离就是Bias的大小
模型越复杂,特征越多,Bias 越小
Bias 和 Variance 造成了过拟合和和欠你和。Bias 大就是欠拟合,Variance 就是过拟合
判断过拟合或者欠拟合的方法
方差大 加数据,正则化,流型,PCA
Bias大 加特征
模型选择
交叉验证
梯度下降 Gradient Descent
L loss function

调整学习率
学习率不能太大防止跨过收敛值,学习率太小,模型训练时间太长
自适应学习率
举一个简单的思想:随着次数的增加,通过一
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 551
551

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









