







 SpringAI的嵌入式客户端接口提供了一种简便方式,将文本转换为数值向量,支持多种模型集成。它强调可移植性和简单性,便于开发者在不同技术间切换,特别适合AI新手。API包含了请求和响应类,以及各种嵌入实现,如OpenAI、AzureOpenAI等。
SpringAI的嵌入式客户端接口提供了一种简便方式,将文本转换为数值向量,支持多种模型集成。它强调可移植性和简单性,便于开发者在不同技术间切换,特别适合AI新手。API包含了请求和响应类,以及各种嵌入实现,如OpenAI、AzureOpenAI等。
https://docs.spring.io/spring-ai/reference/api/embeddings.html
嵌入式API
嵌入式客户端接口旨在与人工智能和机器学习中的嵌入式模型进行直接集成。
其主要功能是将文本转换为数值向量,通常称为嵌入。
这些嵌入对于语义分析和文本分类等各种任务至关重要。
嵌入式客户端接口的设计围绕两个主要目标:
-
可移植性:此接口确保易于适应各种嵌入模型。
它允许开发人员在不同的嵌入技术或模型之间切换,代码更改最小。
这种设计与Spring的模块化和可互换性的哲学相一致。 -
简单性:EmbeddedClient简化了将文本转换为嵌入的过程。
通过提供像embed(String text)和embed(Document document)这样的直接方法,它消除了处理原始文本数据和嵌入算法的复杂性。
这个设计选择使得开发人员更容易,特别是那些对AI新手,能够在他们的应用程序中使用嵌入,而不需要深入研究底层机制。
API概览
嵌入式API建立在通用的Spring AI模型API之上,这是Spring AI库的一部分。
因此,嵌入式客户端接口扩展了模型客户端接口,提供了与AI模型交互的标准方法集。嵌入请求和响应类扩展了模型请求和模型响应,分别用于封装嵌入式模型的输入和输出。
嵌入式API反过来被更高层次的组件用来实现特定嵌入模型的嵌入客户端,如OpenAI、Titan、Azure OpenAI、Ollie等。
下图说明了嵌入式API与Spring AI模型API和嵌入客户端的关系:
图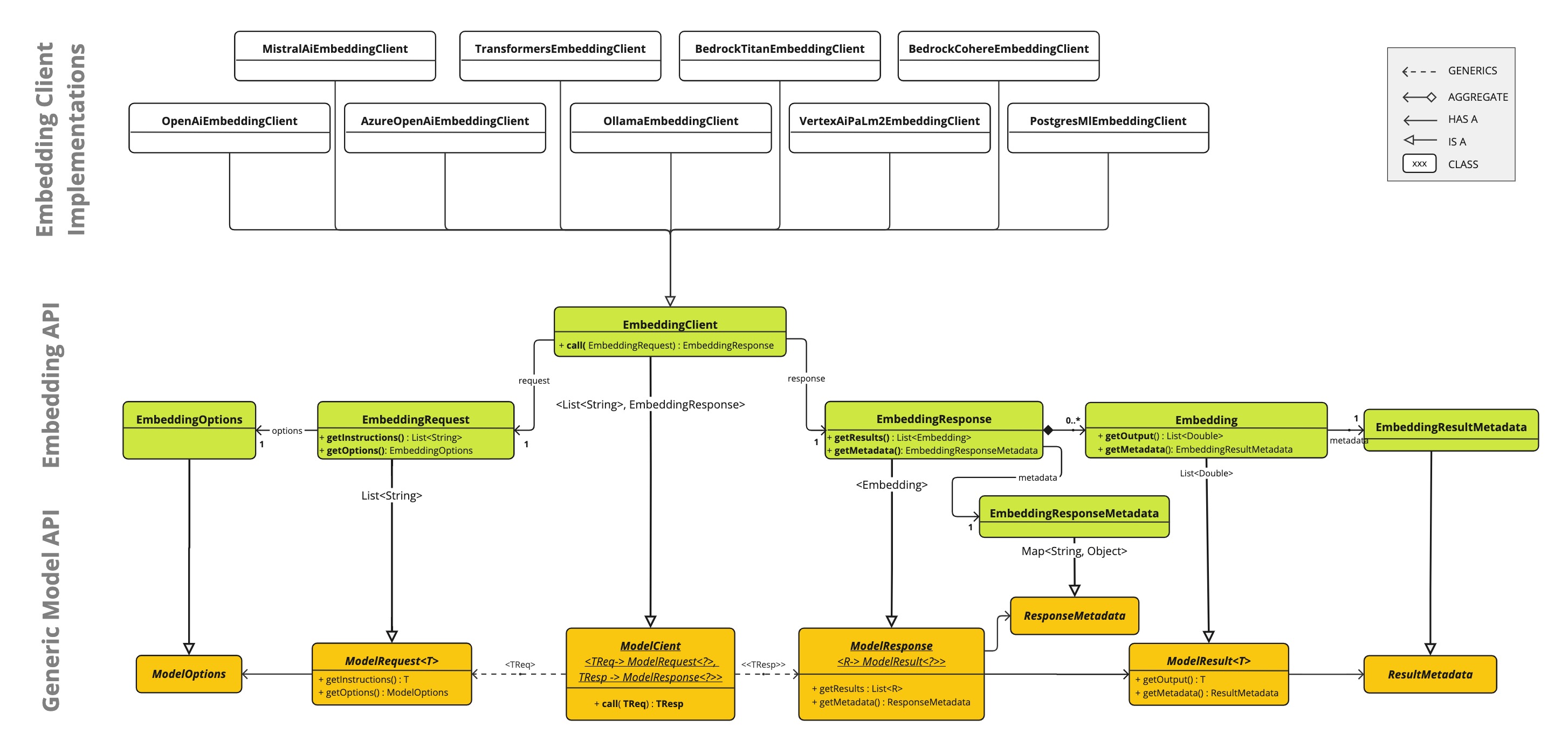
嵌入式客户端
本节提供了嵌入式客户端接口和相关类的指南。
public interface EmbeddingClient extends ModelClient<EmbeddingRequest, EmbeddingResponse> {
@Override
EmbeddingResponse call(EmbeddingRequest request);
/**
* Embeds the given document's content into a vector.
* @param document the document to embed.
* @return the embedded vector.
*/
List<Double> embed(Document document);
/**
* Embeds the given text into a vector.
* @param text the text to embed.
* @return the embedded vector.
*/
default List<Double> embed(String text) {
Assert.notNull(text, "Text must not be null");
return this.embed(List.of(text)).iterator().next();
}
/**
* Embeds a batch of texts into vectors.
* @param texts list of texts to embed.
* @return list of list of embedded vectors.
*/
default List<List<Double>> embed(List<String> texts) {
Assert.notNull(texts, "Texts must not be null");
return this.call(new EmbeddingRequest(texts, EmbeddingOptions.EMPTY))
.getResults()
.stream()
.map(Embedding::getOutput)
.toList();
}
/**
* Embeds a batch of texts into vectors and returns the {@link EmbeddingResponse}.
* @param texts list of texts to embed.
* @return the embedding response.
*/
default EmbeddingResponse embedForResponse(List<String> texts) {
Assert.notNull(texts, "Texts must not be null");
return this.call(new EmbeddingRequest(texts, EmbeddingOptions.EMPTY));
}
/**
* @return the number of dimensions of the embedded vectors. It is generative
* specific.
*/
default int dimensions() {
return embed("Test String").size();
}
}
嵌入方法提供了多种将文本转换为嵌入的选项,适应单个字符串、结构化文档对象或文本批次。
提供了多个嵌入文本的快捷方法,包括嵌入(String text)方法,它接受单个字符串并返回相应的嵌入向量。
所有快捷方法都是围绕调用方法实现的,这是调用嵌入模型的主要方法。
通常,嵌入返回的是表示数值向量格式嵌入的双精度列表。
嵌入ForResponse方法提供了更全面的输出,可能包括有关嵌入的附加信息。
维度方法是一个方便的工具,供开发人员快速确定嵌入向量的大小,这对于理解嵌入空间和后续处理步骤很重要。
嵌入请求
嵌入请求是一个模型请求,它接受一系列文本对象和可选的嵌入请求选项。
下面的列表显示了嵌入请求类的截断版本,不包括构造函数和其他实用方法:
public class EmbeddingRequest implements ModelRequest<List<String>> {
private final List<String> inputs;
private final EmbeddingOptions options;
// other methods omitted
}
嵌入响应
嵌入响应类的结构如下:
public class EmbeddingResponse implements ModelResponse<Embedding> {
private List<Embedding> embeddings;
private EmbeddingResponseMetadata metadata = new EmbeddingResponseMetadata();
// other methods omitted
}
嵌入响应类保存AI模型的输出,每个嵌入实例包含单个文本输入的结果向量数据。
嵌入响应类还携带有关AI模型响应的嵌入响应元数据。
嵌入
嵌入代表单个嵌入向量。
public class Embedding implements ModelResult<List<Double>> {
private List<Double> embedding;
private Integer index;
private EmbeddingResultMetadata metadata;
// other methods omitted
}
可用实现
内部地,各种嵌入客户端实现使用不同的低级库和API来执行嵌入任务。以下是一些可用的嵌入客户端实现:
- Spring AI OpenAI嵌入
- Spring AI Azure OpenAI嵌入
- Spring AI Ollama嵌入
- Spring AI Transformers (ONNX) 嵌入
- Spring AI PostgresML嵌入
- Spring AI Bedrock Cohere嵌入
- Spring AI Bedrock Titan嵌入
- Spring AI VertexAI PaLM2嵌入
- Spring AI Mistral AI嵌入


















 555
555

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











