



开头还是介绍一下群,如果感兴趣PolarDB ,MongoDB ,MySQL ,PostgreSQL ,Redis, OceanBase, Sql Server等有问题,有需求都可以加群群内有各大数据库行业大咖,可以解决你的问题。加群请联系 liuaustin3 ,(共2720人左右 1 + 2 + 3 + 4 +5 + 6 + 7 + 8 +9)(1 2 3 4 5 6 7群均已爆满,开8 近 200群 9群)
MySQL的SQL优化相对于其他的数据库来说,应该是简单的主要的原因有以下
1 业务简单:使用MySQL的业务一般为互联网业务,且在拆库,分表的基础上语句必然变得简单,更多的复杂性是在程序和架构设计的层面。
2 单线程数据查询方式:单线程的数据查询方式更希望的是短小的SQL,这样避免复杂的SQL进行上下文切换中消耗更多的CPU,根据数据库的查询设计来说,MySQL还是希望短小精悍的SQL来进行业务的处理。
3 基于B+TREE的数据物理存储方式:如要发挥最大化的MySQL的查询性能,要利用MySQL查询中的物理属性来进行有的放矢的主键查询,对MYSQL更有利。
基于这些理念和MySQL的物理实现基础,大部分懂得道理的架构师和程序员,都不会给MySQL施加如ORACLE ,SQL SERVER,PostgreSQL类似的大型SQL语句。
但.....
很多MySQL的文盲,还在MySQL上施加了复杂的SQL语句,这就需要进行查询的优化和分析了。一般针对MySQL的分析我们怎么来做。(基于MySQL 版本差异大,MYSQL 5.6 5.7 8.0 9.0 ),这里按照向下兼容的方式,可能有些方法在高版本的MySQL已经非必须,快速查找问题的方法
我们以下面的一个语句作为一个例子;
MySQL [cloud]> explain SELECT
-> COUNT(*)
-> FROM
-> (
-> SELECT
-> eb.slyGroupCo AS groupCo,
-> e.code AS entCo,
-> e.name AS entNa,
-> e.show_meth AS showMeth,
-> e.type + '' AS tag,
-> min(eb.BeginDa) AS beginda,
-> max(eb.EndDa) AS endda, ,
-> GROUP_CONCAT(p.`Name`) AS pkgs
-> FROM
-> shopbi eb,
-> shop dt,
-> prodg p,
-> ent e,
-> bdf bd
-> WHERE
-> e.id = eb.enterpriseid
-> AND eb.id = dt.ShopBillID
-> AND dt.ProductPKGID = p.ID
-> AND eb.shopState = 0
-> AND eb.slymdCode IS NOT NULL
-> AND bd.DESC_ = 'S024739'
-> AND e.ORGID = bd.ID_
-> AND e.code LIKE '%ENT8853%'
-> GROUP BY
-> e.id,
-> eb.id
-> ORDER BY
-> max(eb.createDate) DESC
-> ) a;
+----+-------------+------------+--------+-----------------------------------------------------+--------------------+---------+---------------------------+-------+---------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+------------+--------+-----------------------------------------------------+--------------------+---------+---------------------------+-------+---------------------------------+
| 1 | PRIMARY | <derived2> | ALL | NULL | NULL | NULL | NULL | 23072 | NULL |
| 2 | DERIVED | p | ALL | PRIMARY | NULL | NULL | NULL | 224 | Using temporary; Using filesort |
| 2 | DERIVED | dt | ref | PRIMARY,FKD55C954DBC4687E4,FKD55C954DA4BA8D24 | FKD55C954DA4BA8D24 | 98 | cloudplat.p.ID | 103 | Using index |
| 2 | DERIVED | eb | eq_ref | PRIMARY,FKEB7193FD322835EC,INDEX_SHOPBILL_SLYMDCODE | PRIMARY | 98 | cloudplat.dt.ShopBillID | 1 | Using where |
| 2 | DERIVED | e | eq_ref | PRIMARY,FKD027336111B1115F | PRIMARY | 98 | cloudplat.eb.EnterpriseID | 1 | Using where |
| 2 | DERIVED | bd | eq_ref | PRIMARY | PRIMARY | 182 | cloudplat.e.ORGID | 1 | Using where |
+----+-------------+------------+--------+-----------------------------------------------------+--------------------+---------+---------------------------+-------+---------------------------------+
6 rows inset (0.002 sec1 看到一个MySQL的语句,首先我先看type,尤其复杂的SQL,先看type这里有没有 ALL, 在type中ALL的字段出现,说明在这部分存在全表扫描,那么首先我们就要先分析这块的部分是否有问题。在查看了表信息后,发现对应的索引和主键都是齐全的,关键为什么走了ALL,主要的原因是一个表中的行数非常的少,且与另一个表连接是主外键关系,所以必然对于小表走了全表扫描,所以排除了这部分索引有问题。
MySQL [cloud]> select count(*) from product;
+----------+
| count(*) |
+----------+
| 261 |
+----------+
1 row in set (0.002 sec)MySQL [cloudplat]> select count(*) from shopbi;
+----------+
| count(*) |
+----------+
| 935312 |
+----------+
1 row in set (1.174 sec)下面想快速的对SQL进行优化,则需要使用第二种方案,针对核心表进行分析,这里一眼可以分析出,这个SQL中的核心表是eb,因为eb参与了与多个表之间的关联且通过它来进行where条件的给出是最多的。
eb表的条件 |
|---|
e.id = eb.enterpriseid |
eb.id = dt.ShopBillID |
eb.id = dt.ShopBillID |
eb.shopState = 0 |
eb.slymdCode IS NOT NULL |
max(eb.createDate) DESC |
CREATE TABLE `eb` (
`id` varchar(32) NOT NULL COMMENT '主键',
`shopCode` varchar(32) DEFAULT NULL COMMENT
`EnterID` varchar(32) DEFAULT NULL COMMENT
`createDate` datetime DEFAULT NULL COMMENT
`modate` datetime DEFAULT NULL COMMENT
`shopId` varchar(32) DEFAULT NULL COMMENT
`shopState` int(1) DEFAULT '0' COMMENT
PRIMARY KEY (`id`),
KEY `FKEB7322835EC` (`EnterpriseID`),
KEY `FKEB7193AAD` (`createUser`),
KEY `INDEX_SHOPBILL_SLYMDCODE` (`slymdCode`) USING BTREE,
KEY `INDEX_SHOPBILL_SHOPID` (`shopId`) USING BTREE,
CONSTRAINT `FKEB719335EC` FOREIGN KEY (`EnteiseID`) REFERENCES `enterprise` (`ID`),
CONSTRAINT `FKEB71D131AAD` FOREIGN KEY (`creaUser`) REFERENCES `bdf2` (`USERNAME_`)eb表的条件 | |
|---|---|
e.id = eb.enterseid | 有索引 |
eb.id = dt.ShopBiID | 主键 |
eb.shate = 0 | 无索引 |
eb.slymdCode IS NOT NULL | 有索引 |
max(eb.creatte) DESC | 无索引 |
同时经过验证,虽然shopState无索引,但这里 shopstate过滤的数据并不多,只占本身表的10%,而90%的数据都是需要的。所以这里并不能再这个表进行更多的优化。同时经过语句的分析,发现这里有一个表的条件可以过滤更多的数据。这个表就是bd, 经过再次分析bd表,其中这里有一个关键,可以大量减少e表的扫描行数,而e表的扫描行数减少,将大幅度的减少eb表的扫描行数,而关键在于bd表的DESC_ 没有索引,而导致全表扫描与其他表进行比对。所以随即对表 bd添加索引。
| bdf2_dept | CREATE TABLE `bdf2_dept` (
`ID_` varchar(60) NOT NULL,
`COMP_ID_` varchar(60) DEFAULT NULL,
`CREA_DATE_` date DEFAULT NULL,
`DESC_` varchar(120) DEFAULT NULL,
`NA_` varchar(60) DEFAULT NULL,
`PAT_ID_` varchar(60) DEFAULT NULL,
PRIMARY KEY (`ID_`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC |
+-----------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row inset (0.001 sec)
MySQL [cloudplat]> select count(*) from bdf2;
+----------+
| count(*) |
+----------+
| 1506 |
+----------+
1 row inset (0.002 sec)
ALTER TABLE `cloud`.`bdf2` ADD INDEX `idx_DESC` (`DESC`);MySQL [cloudplat]> select count(*) from ense;
+----------+
| count(*) |
+----------+
| 30787 |
+----------+
1 row in set (0.026 sec)在添加完索引后,整体SQL运行的效率提高了 440倍,从原来的4秒,到现在的0.009秒。
MySQL [cloud]> ALTER TABLE `cloud`.`bdf2` ADD INDEX `idx_DESC` (`DESC_`);
Query OK, 0 rows affected (0.009 sec)
Records: 0 Duplicates: 0 Warnings: 0
MySQL [cloudplat]> explain SELECT
-> COUNT(*)
-> FROM
-> (
-> SELECT
-> eb.slyGroupCode AS groupCode,
-> e.code AS entCode,
-> e.name AS entName,
-> e.show_method AS showMethod,
-> e.type + '' AS tag,
-> min(eb.BeginDate) AS begindate,
-> max(eb.EndDate) AS enddate,
-> e.dbname AS dbname,
-> e.domainname AS domainname,
-> eb.shopCode AS shopCode,
-> eb.shopName AS shopName,
-> eb.linkman AS linkman,
-> eb.slymdCode AS slymdCode,
-> eb.phone AS phone,
-> eb.email AS email,
-> eb.remark AS remark,
-> GROUP_CONCAT(p.`Name`) AS pkgs
-> FROM
-> sholl eb,
-> sholldt dt,
-> propkg p,
-> entise e,
-> bdf2 bd
-> WHERE
-> e.id = eb.entiseid
-> AND eb.id = dt.ShllID
-> AND dt.ProdGID = p.ID
-> AND eb.shate = 0
-> AND eb.slymdCode IS NOT NULL
-> AND bd.DESC_ = 'S739'
-> AND e.ORGID = bd.ID_
-> AND e.code LIKE '%EN53%'
-> GROUP BY
-> e.id,
-> eb.id
-> ORDER BY
-> max(eb.createDate) DESC
-> ) a;
+----+-------------+------------+--------+--------------------------------------------------------------------------------+--------------------+---------+---------------------------+------+-----------------------------------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+------------+--------+--------------------------------------------------------------------------------+--------------------+---------+---------------------------+------+-----------------------------------------------------------+
| 1 | PRIMARY | <derived2> | ALL | NULL | NULL | NULL | NULL | 90 | NULL |
| 2 | DERIVED | bd | ref | PRIMARY,idx_DESC | idx_DESC | 363 | const | 1 | Using where; Using index; Using temporary; Using filesort |
| 2 | DERIVED | e | ref | PRIMARY,FKD0211B1115F | FKD06111B1115F | 99 | cloud.bd.ID_ | 15 | Using index condition; Using where |
| 2 | DERIVED | eb | ref | PRIMARY,FKE835EC,INDEX_SHOPBILL_SLYMDCODE,idx_EnterpriseID_shopState | FKEB7193FD322835EC | 99 | cloudplat.e.ID | 2 | Using where |
| 2 | DERIVED | dt | ref | PRIMARY,FKDDBC4687E4,FKD55C9A8D24 | FKD55C4687E4 | 98 | cloudplat.eb.id | 3 | Using index |
| 2 | DERIVED | p | eq_ref | PRIMARY | PRIMARY | 98 | cloud.dt.ProdID | 1 | NULL |
+----+-------------+------------+--------+--------------------------------------------------------------------------------+--------------------+---------+---------------------------+------+-----------------------------------------------------------+
6 rows inset (0.002 sec)
MySQL [cloudplat]> SELECT
-> COUNT(*)
-> FROM
-> (
-> SELECT
-> eb.slyGroupCode AS groupCode,
-> e.code AS entCode,
-> e.name AS entName,
-> e.show_method AS showMethod,
-> e.type + '' AS tag,
-> min(eb.BeginDate) AS begindate,
-> max(eb.EndDate) AS enddate,
-> e.dbname AS dbname,
-> e.domainname AS domainname,
-> eb.shopCode AS shopCode,
-> eb.shopName AS shopName,
-> eb.linkman AS linkman,
-> eb.slymdCode AS slymdCode,
-> eb.phone AS phone,
-> eb.email AS email,
-> eb.remark AS remark,
-> GROUP_CONCAT(p.`Name`) AS pkgs
-> FROM
-> shopbill eb,
-> shopbilldt dt,
-> productpkg p,
-> enterprise e,
-> bdf2_dept bd
-> WHERE
-> e.id = eb.enteseid
-> AND eb.id = dt.ShllID
-> AND dt.ProdGID = p.ID
-> AND eb.shate = 0
-> AND eb.slymdCode IS NOT NULL
-> AND bd.DESC_ = 'S0739'
-> AND e.ORGID = bd.ID_
-> AND e.code LIKE '%E53%'
-> GROUP BY
-> e.id,
-> eb.id
-> ORDER BY
-> max(eb.crate) DESC
-> ) a;
+----------+
| COUNT(*) |
+----------+
| 14 |
+----------+
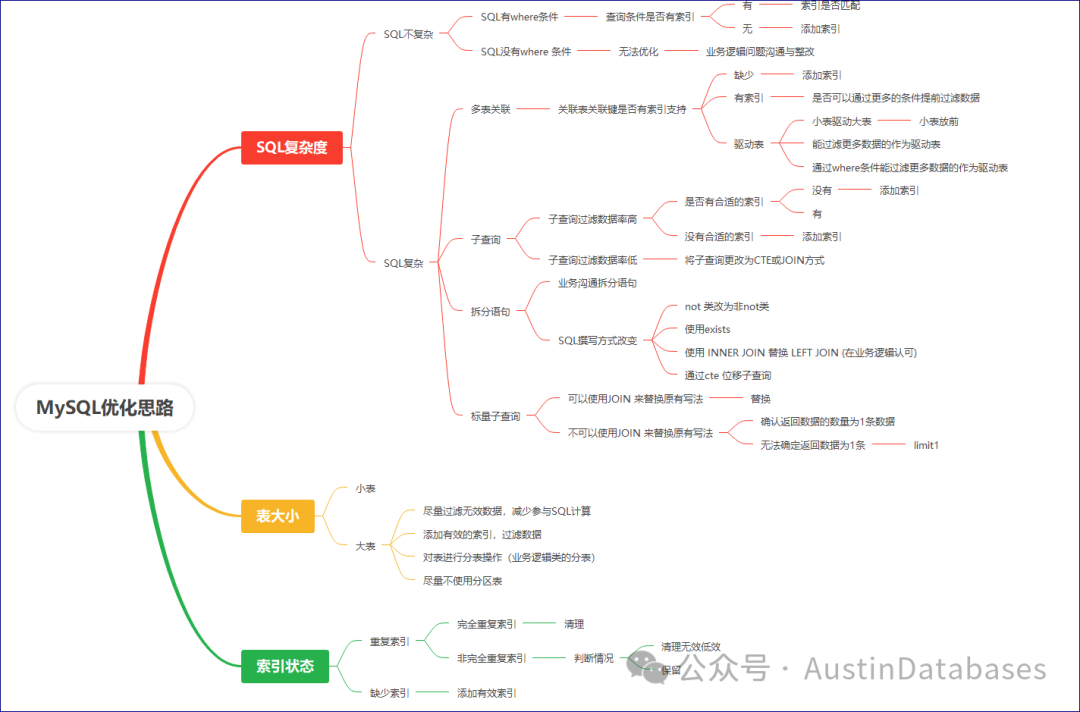
1 row inset (0.009 sec)下面是一个简单的MySQL优化的思路(初级版)
结语:SQL的优化也是分等级,快速的优化解决大部分的问题,针对少量的SQL难点进行细致的优化和问题的解决,如逻辑法,业务法,SQL改写法,HINT 重定index 大法,后期有了相应的案例可以继续和大家进行探讨。
置顶
开源软件是心怀鬼胎的大骗局 -- 开源软件是人类最好的正能量 --- 一个人的辩论会
MySQL相关文章
MySQL 的SQL引擎很差吗?由一个同学提出问题引出的实验
用MySql不是MySQL, 不用MySQL都是MySQL 横批 哼哼哈哈啊啊
MYSQL --Austindatabases 历年文章合集
OceanBase 相关文章
OceanBase 架构学习--OB上手视频学习总结第二章 (OBCA)
OceanBase 6大学习法--OB上手视频学习总结第一章
没有谁是垮掉的一代--记 第四届 OceanBase 数据库大赛
跟我学OceanBase4.0 --阅读白皮书 (OB分布式优化哪里了提高了速度)
跟我学OceanBase4.0 --阅读白皮书 (4.0优化的核心点是什么)
跟我学OceanBase4.0 --阅读白皮书 (0.5-4.0的架构与之前架构特点)
跟我学OceanBase4.0 --阅读白皮书 (旧的概念害死人呀,更新知识和理念)
OceanBase 学习记录-- 建立MySQL租户,像用MySQL一样使用OB
临时工访谈:OceanBase上海开大会,我们四个开小会 OB 国产数据库破局者
临时工说:OceanBase 到访,果然数据库的世界很卷,没边
数据库信息速递 阿里巴巴的分布式数据库OceanBase旨在进军中国以外的市场 (翻译)
PostgreSQL 相关文章
PostgreSQL 添加索引导致崩溃,参数调整需谨慎--文档未必完全覆盖场景
PostgreSQL SQL优化用兵法,优化后提高 140倍速度
PostgreSQL 运维的难与“难” --上海PG大会主题记录
PostgreSQL 什么都能存,什么都能塞 --- 你能成熟一点吗?
全世界都在“搞” PostgreSQL ,从Oracle 得到一个“馊主意”开始
PostgreSQL 加索引系统OOM 怨我了--- 不怨你怨谁
PostgreSQL “我怎么就连个数据库都不会建?” --- 你还真不会!
病毒攻击PostgreSQL暴力破解系统,防范加固系统方案(内附分析日志脚本)
PostgreSQL 远程管理越来越简单,6个自动化脚本开胃菜
PostgreSQL 稳定性平台 PG中文社区大会--杭州来去匆匆
PostgreSQL 分组查询可以不进行全表扫描吗?速度提高上千倍?
POSTGRESQL --Austindatabaes 历年文章整理
PostgreSQL 查询语句开发写不好是必然,不是PG的锅
PostgreSQL 字符集乌龙导致数据查询排序的问题,与 MySQL 稳定 "PG不稳定"
PostgreSQL Patroni 3.0 新功能规划 2023年 纽约PG 大会 (音译)
PostgreSQL 玩PG我们是认真的,vacuum 稳定性平台我们有了
PostgreSQL DBA硬扛 垃圾 “开发”,“架构师”,滥用PG 你们滚出 !(附送定期清理连接脚本)
MongoDB 相关文章
MongoDB 大俗大雅,上来问分片真三俗 -- 4 分什么分
MongoDB 大俗大雅,高端知识讲“庸俗” --3 奇葩数据更新方法
MongoDB 大俗大雅,高端的知识讲“通俗” -- 2 嵌套和引用
MongoDB 大俗大雅,高端的知识讲“低俗” -- 1 什么叫多模
MongoDB 合作考试报销活动 贴附属,MongoDB基础知识速通
MongoDB 使用网上妙招,直接DOWN机---清理表碎片导致的灾祸 (送书活动结束)
数据库 《三体》“二向箔” 思维限制 !8个公众号联合抽奖送书 建立数据库设计新思维
MongoDB 是外星人,水瓶座,怎么和不按套路出牌的他沟通?
17000多张MongoDB表的锅 自动分析删除表数据难题--从头到尾的处理过程(文尾有MongoDB开发规范)
MongoDB 插入更新数据慢,开发问哪的问题?附带解决方案和脚本
MongoDB 挑战传统数据库聚合查询,干不死他们的MongoDB 2023纽约 MongoDB 大会 -- 我们怎么做的新一代引擎 SBE Mongodb 7.0双擎力量(译)
MongoDB 2023年度纽约 MongoDB 年度大会话题 -- MongoDB 数据模式与建模
MongoDB 双机热备那篇文章是 “毒”
MongoDB 会丢数据吗?在次补刀MongoDB 双机热备
MONGODB ---- Austindatabases 历年文章合集
PolarDB 相关文章
POLARDB 添加字段 “卡” 住---这锅Polar不背
PolarDB 版本差异分析--外人不知道的秘密(谁是绵羊,谁是怪兽)
PolarDB 答题拿-- 飞刀总的书、同款卫衣、T恤,来自杭州的Package(活动结束了)
PolarDB for MySQL 三大核心之一POLARFS 今天扒开它--- 嘛是火星人
PolarDB-MySQL 并行技巧与内幕--(怎么薅羊毛)
PolarDB 并行黑科技--从百套MySQL撤下说起 (感谢8018个粉丝的支持)
PolarDB 杀疯了,Everywhere Everytime Everydatabase on Serverless
POLARDB 从一个使用者的角度来说说,POALRDB 怎么打败 MYSQL RDS
PolarDB 最近遇到加字段加不上的问题 与 使用PolarDB 三年感受与恳谈
PolarDB 从节点Down机后,引起的主从节点强一致的争论
PolarDB serverless 真敢搞,你出圈了你知道吗!!!!
PolarDB VS PostgreSQL "云上"性能与成本评测 -- PolarDB 比PostgreSQL 好?
临时工访谈:PolarDB Serverless 发现“大”问题了 之 灭妖记 续集
临时工访谈:庙小妖风大-PolarDB 组团镇妖 之 他们是第一
PolarDB for PostgreSQL 有意思吗?有意思呀
PolarDB Serverless POC测试中有没有坑与发现的疑问
临时工说:从人性的角度来分析为什么公司内MySQL 成为少数派,PolarDB 占领高处
POLARDB -- Ausitndatabases 历年的文章集合
PolarDB for PostgreSQL 有意思吗?有意思呀
临时工访谈系列
国内最大IT服务公司-招聘DBA “招聘广告”的变化--分析与探讨
没有谁是垮掉的一代--记 第四届 OceanBase 数据库大赛
SQL SERVER 系列
SQL SERVER 如何实现UNDO REDO 和PostgreSQL 有近亲关系吗
SQL SERVER 我没有消失,SQL SERVER下一个版本是2025 (功能领先大多数数据库)
SQL SERVER 2022 针对缓存扫描和Query Store 的进步,可以考虑进行版本升级
阿里云系列
阿里云数据库产品权限设计缺陷 ,六个场景诠释问题,你可以做的更好?
阿里云数据库--市场营销聊胜于无--3年的使用感受与反馈系列
阿里云数据库产品 对内对外一样的卷 --3年阿里云数据库的使用感受与反馈系列
阿里云数据库使用感受--客户服务问题深入剖析与什么是廉价客户 --3年的使用感受与反馈系列
阿里云数据库使用感受--操作界面有点眼花缭乱 --3年的使用感受与反馈系列


















 889
889

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









