



这开头还是介绍一下群,如果感兴趣PolarDB ,MongoDB ,MySQL ,PostgreSQL ,Redis, Oceanbase, Sql Server等有问题,有需求都可以加群群内,可以解决你的问题。加群请微信联系 liuaustin3 ,(共2000人左右 1 + 2 + 3 + 4 +5) 新入群的将默认分配达到5群),另欢迎 OpenGauss 的技术人员加入。
新年的第二篇,新年后的两天工作鸡飞狗跳,让我很累。我不怕一个人技术的问题,我怕他最近不在状态,每个人都有不在状态的时候,干错事,所答非所问。事情是干不完的,分清主次,我们也承认人的能力是有限的,这也是我一个想着早点退休的人,慢慢悟出来的,可能是年龄大了,悟出的理越来越多,我的生活不止有数据库,还有更绚烂多彩的东西等着我。


阿里巴巴是世界上最大的电子交易商务平台,为6亿人提供了交易服务,截止2018年交易总额超过7680亿元,在电子商务中有几个重要的特点:
1 在促销活动开始后,每秒的交易会快速增加
2 大量的交易记录会瞬间朝向系统的缓冲区逼近
3 交易中的数据存在温度,并且这些(热,温,冷)温度会快速转移。
比如在2018年,双11全球购物节经历了122倍的交易增长,每秒处理49.1万个销售交易,相当于每秒超过7000万个数据库的实物,为了应对这些,我们引入了 x-engine, 这是阿里巴巴开发的polardb 写优化存储引擎,他利用分层存储和LSM TREE来加速数据的写入充分利用硬件基于FPGA的合并,并使用一套优化措施,包括事务中的异步写入,多个阶段流水线合并期间的增量缓存替换等,评估结果显示,x-engine在这种实物工作负载下的性能优于其他存储引擎。
阿里巴巴运营者全球最大的最繁忙的电子商务平台,包括C2C零售市场,B2B市场和其他的在线市场,为超过6亿消费者提供服务,在2018年总的交易额度交易额超过7680亿美元,这些在线购物市场创造了购物和销售的新方式,例如:一个在线促销活动一开始就可以迅速吸引全球顾客的关注,因为于线下的商业相比,数字市场中的在线商店没有物理限制。为了通过这一个考验我们引入一种新的在线事物处理OLTP 存储引擎 XENGINE,因为实物处理性能的一个重要部分取决于数据的持久化和存储的高效性。
电子商务工作负载的关键挑战,我们首先确定三个关键的技术挑战
1 海啸问题:阿里巴巴的电子商务平台经常需要事先选择满足顾客广泛期望,并且在整个市场范围内举办促销活动,如双十一全球购物节每年11月11日举行,天猫上几乎所有卖家的主要促销活动从午夜开始,虽然许多的促销活动持续1天,但一些折扣只有在有限的时间内提供火数量内提供(先到先得),这就造成了底层存储引擎的实物工作量的激增,(视为美妙实物数相对于时间的巨大垂直波峰)。从11月11日的00:00:00开始,就像一股巨大的海啸冲击岸边。
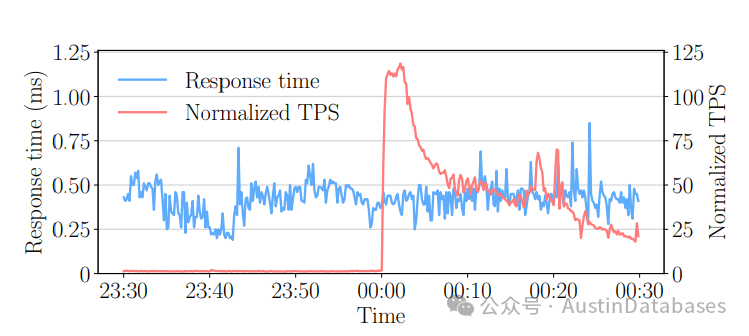
为了应对图1中显示的122倍峰值,阿里巴巴采用了OLTP数据库的共享无关体系结构,其中分片用于将实物分布在多个数据库实力之间,并在峰值到来之前增加数据库实力的数量,尽管这样方法有效,但由于需要的实例的数量之多,他会带来巨大的经济和工程成本。
我们通过改进存储引擎的单机容量来解决这个问题,存储引擎是OLTP数据库的核心组件之一,从而减少给定的峰值和吞吐量所需的实力数量,或者在固定的成本下提高可事先的吞吐量。在线促销活动在电子商务交易中制造了高峰时段,于飞高峰时段相比,这些交易包含了更多的写入操作,尽管近年来主内存容量稳步在增长,但在双十一,需要更多更新的交易记录,这些仍然超过设计的容量,因此我们必须利用RAM SSD HDD 组成有层次结构的存储来解决问题。X-engine ,通过利用这种层次结构,根据数据的温度降数据防止在不同的层次中,并使用新的内存技术,这就像通过主机增加水库来排放刘聪的洪水一样,LSM 树结构来加速写操作的常见技术,这里还包括了日志的数据结构的追加方法,优化基于树结构存储方式,以及两者的混合形式等,我们发现其中任何一种方法都不能满足电子交易的写入性能,一些列存储,不适合写入密集交易,其他一些提升了写入性能,但亿牺牲点查询和范围查询性能为代价,不适合混合读写的电子商务工作负载,LSM树结构包含一个存储在内存中的组件,我们可以对其应用追加方法,以事先快速的插入,病包含多个磁盘的组件,每个组件都包含级别,组成一个树状的结构,其中每个级别的大小明显大于其上一级,这种数据结构非常适合分层存储,有助于解决我们数据流涌入引起问题的处理。
快速流动的当前问题在对于大多数数据库工作负载尤其在告诉产生数据记录的业务中,在固定的时间段中有较强的空间特性,在双11购物节这样的重大促销活动中,如全天都会举办不同类别的品牌的秒杀活动,以刺需求并引起客户的注意,和购买不同的商品。这意味数据库缓存中的热数据会不断地变化,任何记录的温度也可以从热转温,在转冷。如果将数据库缓存视为水库,底层数据视为海洋,这将产生一个冷热数据的快速交换的过程,任何方向移动于非常深的底部,如X-engine ,存储引擎需要确保新出现的热数据能尽快从深层检出并有效的进行缓存。
X-Engine 是一个基于LSM树用于OLTP数据库的存储引擎,主要是为了解决阿里云巴巴电子商务平台面临的挑战通过多核心的处理器线程的并行性,在主内存中处理大部分请求将写操作与事务解耦使其异步进行,并且将长时间的写入分成多个步骤来进行,在多个通道中进行,增加总的数据吞吐量,为解决数据洪水的问题,X-engine 利用分层存储的方式在不同的层级之间移动数据,利用精细化的LSM树状结构和优化的压缩算法。最终我们通过锚定当前数据流大量涌入的问题,通过多版本源数据索引,在数据库写入的时候进行更新,加快我们在分层存储中的数据提取的速度,而不需要考虑数据的温度。
这里我们做了相关的工作如下并解决了我们识别了面向电子商务中的OLTP存储引起面临的三个挑战,针对这个三个挑战我们开发出基于lsm tree 下的x-engine,引入了一套优化的方法,解决问题,如降息后LSM树的数据结构,PFGA加速压缩,事务中异步写入多阶段流水线和多版本的元数据索引。
通过使用标准基准测试和实际的业务我们对 X-Engine进行了广泛的评估,通过测试,结果中展现在促销期间,通过x-engine在电子商务工作负载中的性能优于 innodb, rocksdb 这样的数据库引擎。
系统设计,X-Engine 是一种基于优化的LSM树结构的分层OLTP的存储引擎,基于电子商务失误工作负载中的数据的温度不断的变化,我们将记录放置在不同的存储层,亿分别提供不同的状态的记录的访问的方案,这使得x-engine 可以根据记录的热度,来灵活的设计数据机构和访问方法,同时我们在设计中也发现LSM树并不能完全支持电子商务工作负载,在X-EGINE中我们设计并应用了一套优化方案来解决之前确定的需要解决的问题,作为 POLARDB 的一部分,X-Engine 可以部署在POLARDB 上的POLARFS上,PolarDB FS 采用了许多新的技术,以实现超低延迟的文件系统,如使用RDMA 和 NVMe .
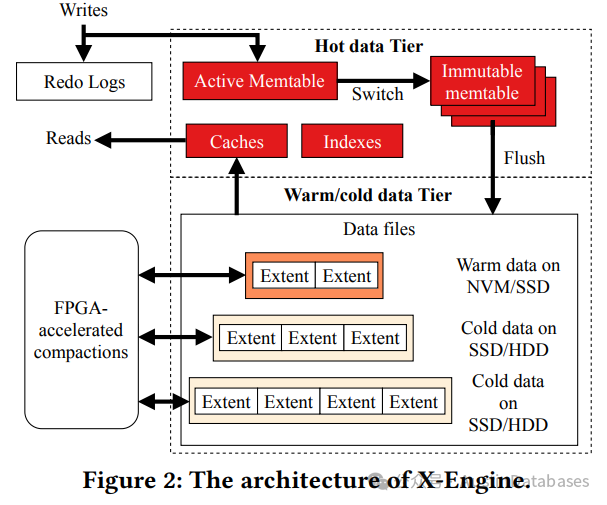
待续.....




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









